随机梯度下降
如果我们一定需要一个大规模的训练集,我们可以尝试使用随机梯度下降法来代替批量梯度下降法。
在随机梯度下降法中,我们定义代价函数为一个单一训练实例的代价:
随机梯度下降算法为:首先对训练集随机“洗牌”,然后:
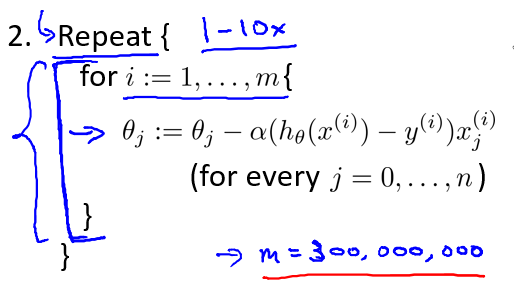
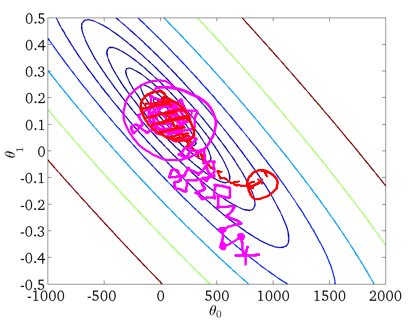
随机梯度下降算法在每一次计算之后便更新参数 θ,而不需要首先将所有的训练集求和,在梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但是这样的算法存在的问题是,不是每一步都是朝着”正确”的方向迈出的。因此算法虽然会逐渐走向全局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。