问题驱动
- 异常检测(Anomaly Detection)
异常检测(Anomaly Detection) 异常检测(Anomaly detection)问题,这是机器学习算法的一个常见应用。这种算法的一个有趣之处在于:它虽然主要用于非监督学习问题,但从某些角度看,它又类似于一些监督学习问题。
假想你是一个飞机引擎制造商,当你生产的飞机引擎从生产线上流出时,你需要进行 QA (质量控制测试),而作为这个测试的一部分,你测量了飞机引擎的一些特征变量,比如引擎 运转时产生的热量,或者引擎的振动等等。

如果生产了 m 个引擎的话,将这些数据绘制成图表,看起来就是这个样子:
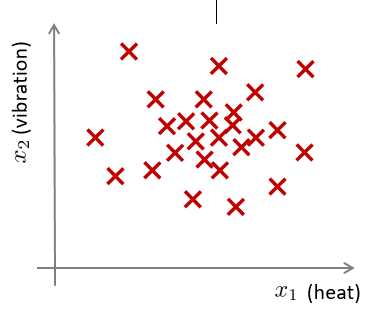
异常检测问题可以定义如下:我们假设后来有一天,有一个新的飞机引擎从生产线上流出,新飞机引擎有特征变量$x_{test}$, 我们希望知道这个新的飞机引擎是否有某种异常。
给定数据集$x^{(1)}, x^{(2)},…,x^{(m)}$,假设数据集是正常的,我们希望知道新的数据$x_{test}$是不是异常的,即这个测试数据不属于该组数据的几率如何。我们所构建的模型应该能根据该测试数据的位置告诉我们其属于一组数据的可能性 $p(x)$。
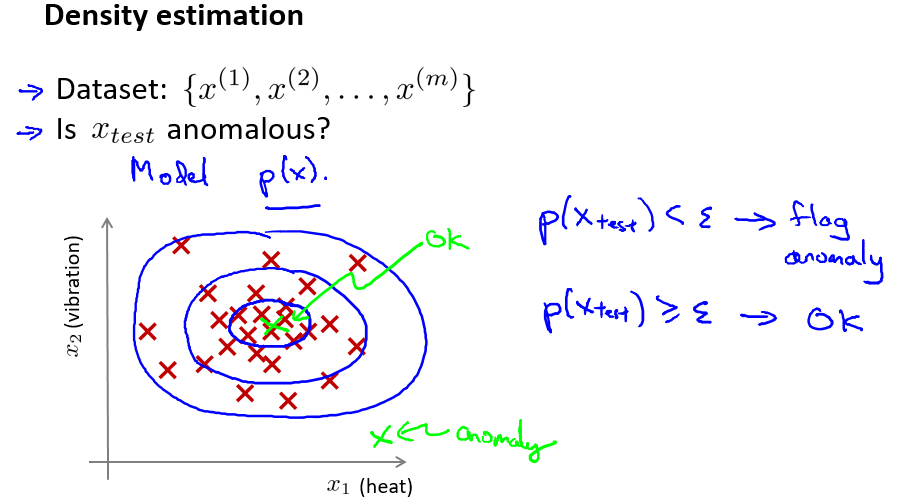
上图中,在蓝色圈内的数据属于该组数据的可能性较高,而越是偏远的数据,其属于该 组数据的可能性就越低。
这种方法称为密度估计,表达如下:
$x^{(i)}$用户的第 i 个特征
模型 $p(x)$为我们其属于一组数据的可能性,通过 $p(x)<\varepsilon$检测非正常用户。
牛刀小试
Todo: 小调查,列出你知道的异常检测的用途
答:
1.识别欺骗。特征:用户多久登录一次,访问过的页面,在论坛发布的帖子数量,甚至是打字速度等。构建模型来识别那些不符合该模式的用户;
2.数据中心。特征:内存使用情况,被访问的磁盘数量,CPU 的负载,网络的通信量等。构建模型来判断某些计算机是不是有可能出错了。