大型数据集的学习
我们应该怎样应对一个有 100 万条记录的训练集?
以线性回归模型为例,每一次梯度下降迭代,我们都需要计算训练集的误差的平方和,如果我们的学习算法需要有 20 次迭代,这便已经是非常大的计算代价。
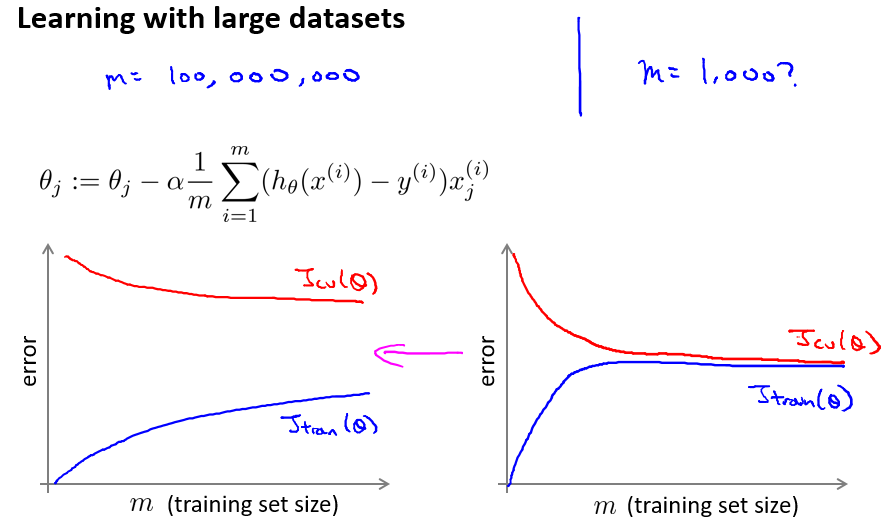
首先应该做的事是去检查一个这么大规模的训练集是否真的必要,也许我们只用 1000 个训练集也能获得较好的效果,我们可以绘制学习曲线来帮助判断。
拓展问题:
Todo: 如果在1000个样本的情况下,学习曲线是右图所示的样子,继续增加样本,结果会有很大的变化吗?
答:应该不会
我们应该怎样应对一个有 100 万条记录的训练集?
以线性回归模型为例,每一次梯度下降迭代,我们都需要计算训练集的误差的平方和,如果我们的学习算法需要有 20 次迭代,这便已经是非常大的计算代价。
首先应该做的事是去检查一个这么大规模的训练集是否真的必要,也许我们只用 1000 个训练集也能获得较好的效果,我们可以绘制学习曲线来帮助判断。
Todo: 如果在1000个样本的情况下,学习曲线是右图所示的样子,继续增加样本,结果会有很大的变化吗?
答:应该不会