过拟合问题
过拟合(Overfitting)
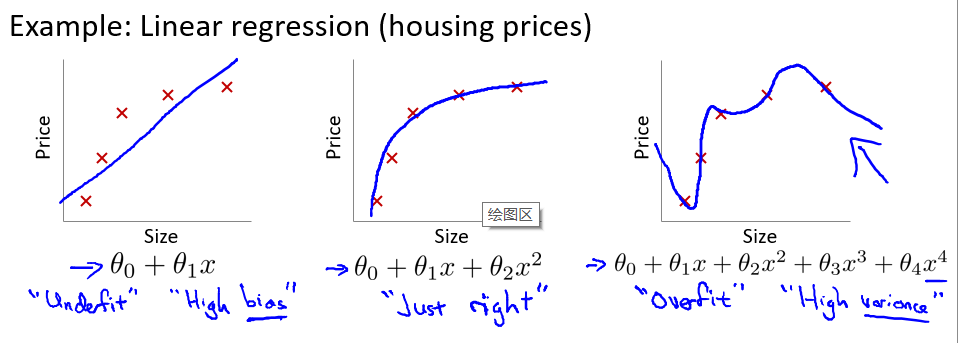
-
第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练集;
-
第三个模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。
-
我们可以看出,若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
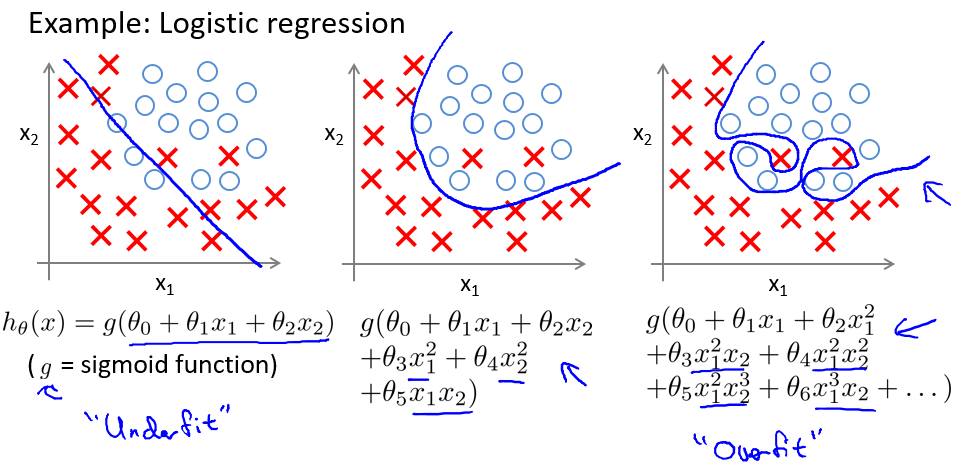
就以多项式理解,x 的次数越高,拟合的越好,但相应的预测的能力就可能变差。
如何解决过拟合问题
-
丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如 PCA, LDA),缺点是丢弃特征的同时,也丢弃了这些相应的信息;
-
正则化。 保留所有的特征,但是减少参数的大小(magnitude),当我们有大量的特征,每个特征都对目标值有一点贡献的时候,比较有效。
-
还有一个解决方式就是增加数据集, 因为过拟合导致的原因就过度拟合测试数据集, 那么增加数据集就很大程度提高了泛化性了.