梯度下降
我们有函数 $J(\theta_{0}, \theta_{1})$, 我们不断的调整 $\theta_{0}$ 和 $\theta_{1}$, 来使得 $J(\theta_{0}, \theta_{1})$ 不断的变小, 直到 $J(\theta_{0}, \theta_{1})$ 达到最小值为止

梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数$J(\theta_{0}, \theta_{1})$的最小值。
梯度下降背后的思想是:开始时我们随机选择一个参数的组合$(\theta_{0},\theta_{1},……,\theta_{n})$ ,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到抵达一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
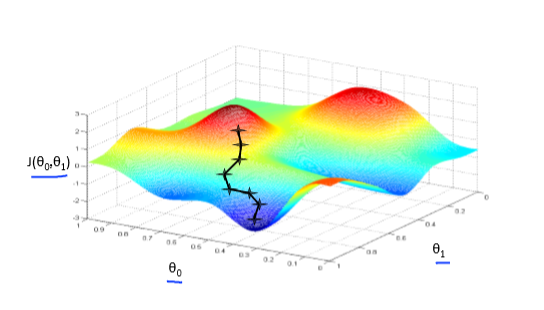
想象一下你正站立在山的这一点上,站立在你想象的公园这座红色山上,在梯度下降算法中,我们要做的就是旋转 360 度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。
批量梯度下降(batch gradient descent)算法的公式为:

其中 α 是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。
细节注意:更新$\theta_{0}$和 $\theta_{1}$。
实现梯度下降算法的微妙之处是,在这个表达式中,如果你要更新这个等式,你需要同时更新 $\theta_{0}$和 $\theta_{1}$,实现方法是:你应该计算公式右边的部分,通过那一部分计算出$\theta_{0}$和 $\theta_{1}$的值,然后同时更新$\theta_{0}$和$\theta_{1}$。
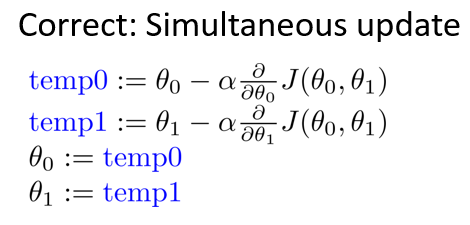
在梯度下降算法中,这是正确实现同时更新的方法。注意区别不正确的写法:
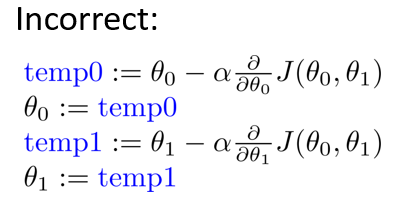
在接下来的视频中,我们要进入这个微分项的细节之中。