多分类任务
- 逻辑回归 (logistic regression) 解决多分类问题
- “一对多” (one-vs-all)分类算法
问题场景举例:
- 自动邮件归类, 第一个例子:假如说你现在需要一个学习算法能自动地将邮件归类到不同的文件夹里,区分开来自工作的邮件、来自朋友的邮件、来自家人的邮件或者是有关兴趣爱好的邮件,那么,就有了一个四分类问题:其类别有四个,分别用 y=1、y=2、y=3、y=4 来代表。
- 药物诊断。如果一个病人因为鼻塞来到你的诊所,他可能并没有生 病,用 y=1 这个类别来代表;或者患了感冒,用 y=2 来代表;或者得了流感用 y=3 来代表。
- 天气。要区分哪些天是晴天、多云、雨天、或者下雪天
二分类与多分类的数据集区别:
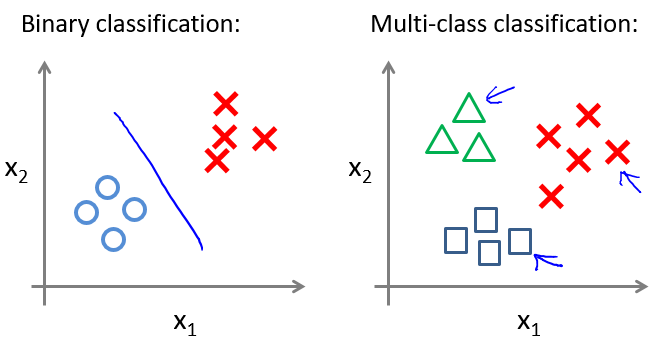
一个学习算法来进行分类呢?
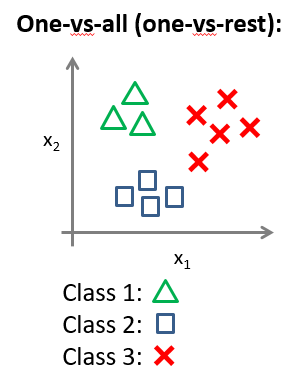
下面将介绍如何进行一对多的分类工作,有时这个方法也被称为”一对余”方法。
现在我们有一个训练集,有三个类别,我们用三角形表示 y=1,方框表示 y=2,叉叉表示 y=3。我们下面要做的就是使用一个训练集,将其分成三个二元分类问题。
先从用三角形代表的类别 1 开始,实际上我们可以创建一个,新的”伪”训练集,类型 2 和类型 3 定为负类,类型 1 设定为正类,我们创建一个新的训练集,我们要拟合出一个合适的分类器。
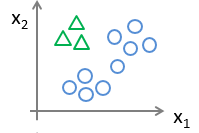
这里的三角形是正样本,而圆形代表负样本。可以这样想,设置三角形的值为 1,圆形的值为 0,下面我们来训练一个标准的逻辑回归分类器,这样我们就得到一个正边界。
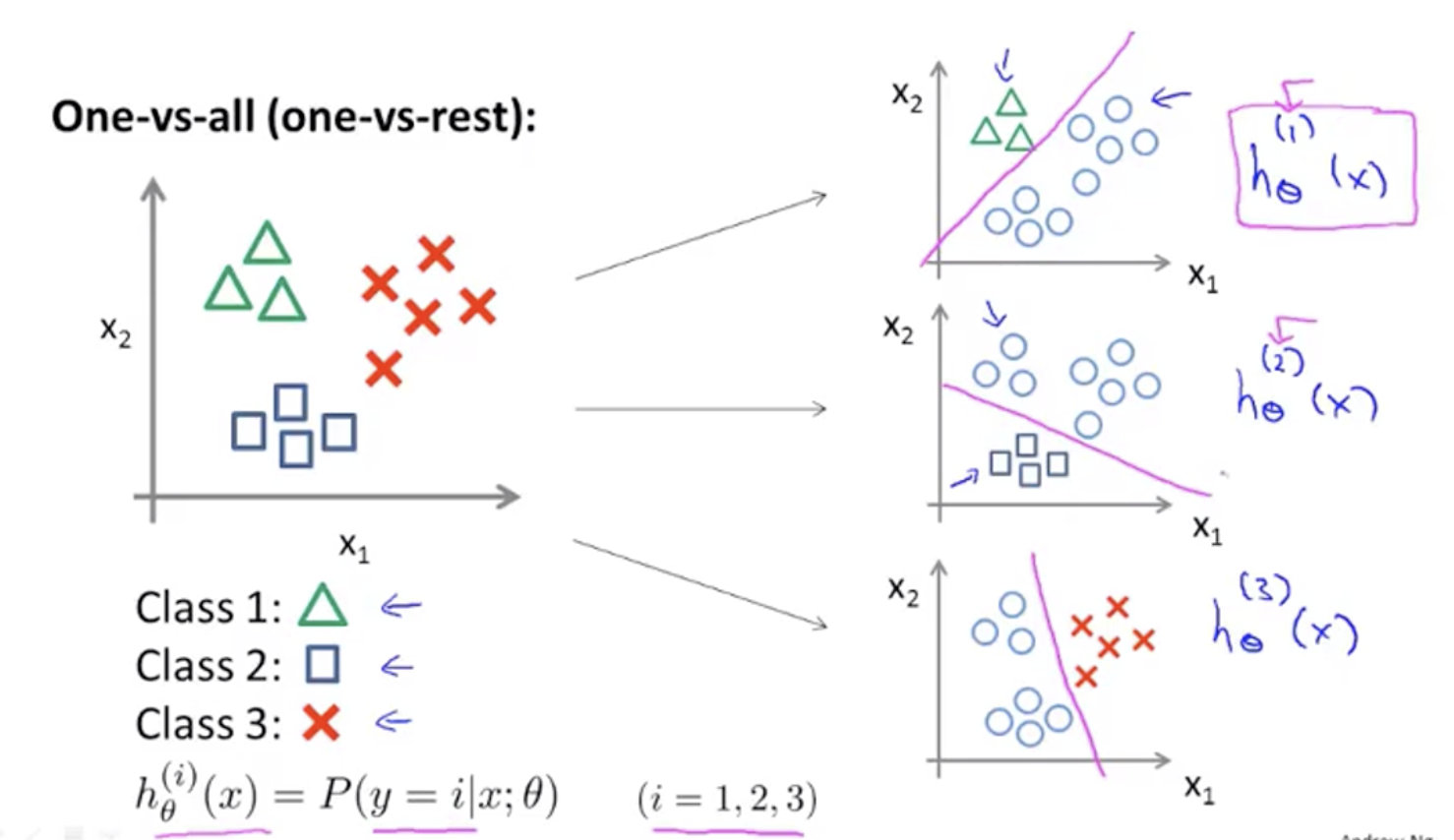
为了能实现这样的转变,我们将多个类中的一个类标记为正向类(y=1),然后将其他所有类都标记为负向类,这个模型记作$h^{(1)}{\theta}(x)$。接着,类似地第我们选择另一个类标记为 正向类(y=2),再将其它类都标记为负向类,将这个模型记作 $h^{(2)}{\theta}(x)$,依此类推。 最后我们得到一系列的模型简记为:
最后,在我们需要做预测时,我们将所有的分类机都运行一遍,然后对每一个输入变量,都选择最高可能性的输出变量。 总之,我们已经把要做的做完了,现在要做的就是训练这个逻辑回归分类器:$h^{(i)}{\theta}(x)$, 其中 i 对应每一个可能的 y=i,最后,为了做出预测,我们给出输入一个新的 x 值做预测。我们要做的就是在我们三个分类器里面输入 x,然后我们选择一个让 $h^{(i)}{\theta}(x)$ 最大的 i,即 $\max_{i}h^{(i)}_\theta(x)$。
你现在知道了基本的挑选分类器的方法,选择出哪一个分类器是可信度最高效果最好的,那么就可认为得到一个正确的分类,无论 i 值是多少,我们都有最高的概率值,我们预测 y 就是那个值。这就是多类别分类问题,以及一对多的方法,通过这个小方法,你现在也可以将逻辑回归分类器用在多类分类的问题上。
牛刀小试
Todo: 如果要按照这种方式进行三分类,需要几个分类器?
答:3个