机器学习的数据
- 讨论机器学习的数据量的影响
- 数据量与特征值选择
机器学习的数据
多年前,两位研究人员 Michele Banko 和 Eric Brill 进行了一项有趣的研究,他们尝试通过机器学习算法来区分常见的易混淆的单词,他们尝试了许多种不同的算法,并且改变了训练数据集的大小,并尝试将这些学习算法用于不同大小的训练数据集中,这就是他们得到的结果:
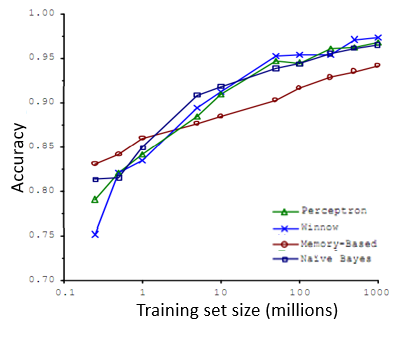
这些趋势非常明显。首先大部分算法,都具有相似的性能;其次,随着训练数据集的增大,在横轴上代表以百万为单位的训练集大小,从 0.1 个百万到 1000 百万,也就是到了 10 亿规模的训练集的样本,这些算法的性能也都对应地增强了。
这些结果表明,许多不同的学习算法有时倾向于表现出非常相似的表现,但是真正能提高性能的,是你能够给一个算法大量的训练数据。像这样的结果,引起了一种在机器学习中的普遍共识:”取得成功的人不是拥有最好算法的人,而是拥有最多数据的人“。
数据量与特征参数选择

关于机器学习数据与特征值的选取比较有效的检测方法:
-
一个人类专家看到了特征值 x,能很有信心的预测出 y 值吗?
因为这可以证明 y 可以根据特征值 x 被准确地预测出来。 -
我们实际上能得到一组庞大的训练集,并且在这个训练集中训练一个有很多参数的学习算法吗?