这一节我们主要学习
- 深度强化学习的基础知识及其应用场景
- 用基于策略的方法(Policy-based)学习一个做事的 Actor
- 用基于价值的方法(Value-based)学习一个批评的 Critic(下学期内容)
- 将 Actor 与 Critic 结合得到当前最强的方法 A3C(下学期内容)
1.深度强化学习

David Sivler 说 人工智能(AI)= 强化学习(RL)+ 深度学习(DL)
15年 Google 在 nature 发表 深度强化学习玩 Atari 游戏的论文
16年著名的 Alpha Go 痛扁人类
1.1 强化学习应用场景
 有个傻傻的机器人小白( Agent )去闯荡世界( Environment ),世界是非常开放的,将自己的状态( State )毫不吝啬地给小白呈现 ,
有个傻傻的机器人小白( Agent )去闯荡世界( Environment ),世界是非常开放的,将自己的状态( State )毫不吝啬地给小白呈现 ,
而小白也会做出一些懵懵懂懂的探索动作( Action ),这时候世界就会告诉小白你的所作所为是好的还是不好的( Reward )。
小白看到一杯水( State ),懵懂的小白一下子将它打翻了( Action ),则他会收到负面反馈( Reword )。由于环境是连续的,
紧接着小白面前的就是一杯被打翻的水( State ),于是试着把水擦干净( Action ),得到了正面反馈( Reward )。
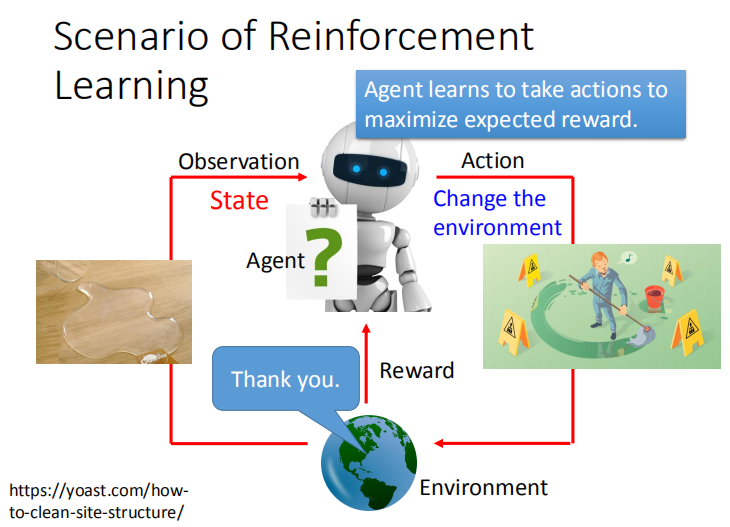
于是,小白要做的就是,根据前面收获的正面和负面反馈,去学习哪些能时正面反馈最大化的行为。
1.2 监督学习与增强学习
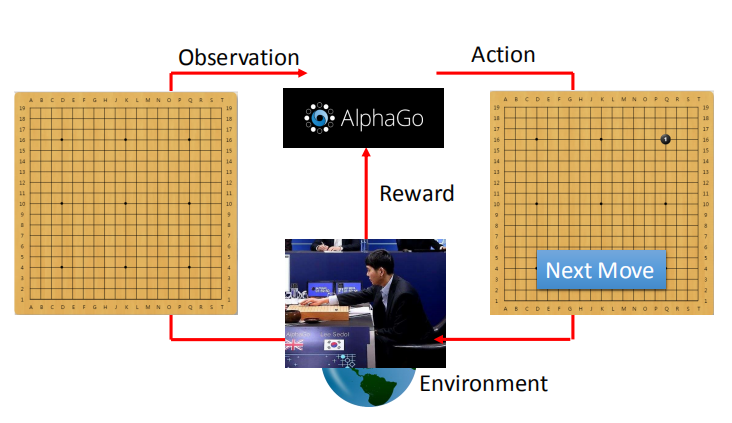 在下围棋的过程中,环境为你的对手,机器观察棋盘上的落子情况,
在下围棋的过程中,环境为你的对手,机器观察棋盘上的落子情况,
根据对手的落子,机器做出不同的动作。
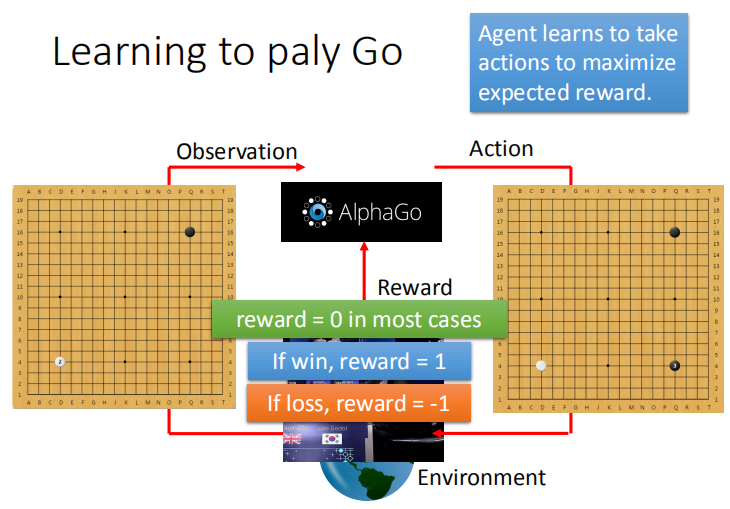 问题的难点在于,不是每次落子都能够得到有效的 reward,需要结束一盘棋局才能得到 reward,大多数情况下,reward 的值为 0。
问题的难点在于,不是每次落子都能够得到有效的 reward,需要结束一盘棋局才能得到 reward,大多数情况下,reward 的值为 0。
监督学习根据棋谱来进行学习。
强化学习是让两个 agent 进行大量的相互对弈,依据经验来进行学习。
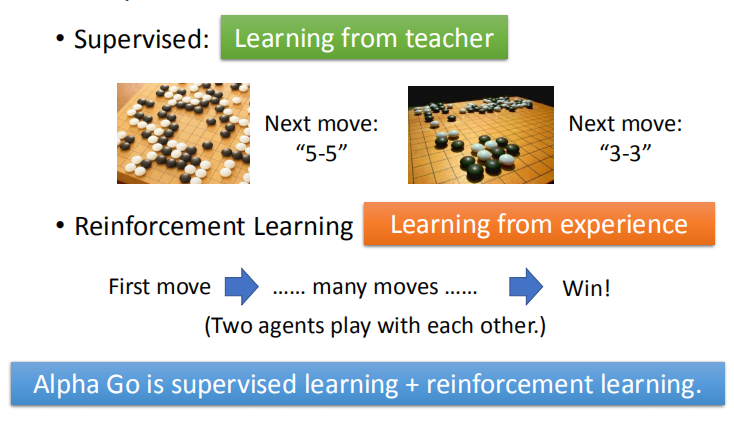
- Supervised
就是告诉机器说看到什么样的态势就落在指定的位置。
Supervised不足的地方就是具体态势下落在哪个地方是最好的,其实人也不知道,因此不太容易做Supervised。
用Supervised就是machine从老师那学,老师说下哪就下哪。 - Reinforcement
就是让机器找一个对手不断下下,赢了就获得正的reward,没有人告诉它之前哪几步下法是好的,
它要自己去试,去学习。Reinforcement 是从过去的经验去学习,没有老师告诉它什么是好的,什么是不好的,machine要自己想办法,
其实在做Reinforcement 这个task里面,machine需要大量的training,可以两个machine互相下。
Alpha Go 结合了两种方法,先进行监督学习,获得较好的表现之后再进行强化学习。
1.3 聊天机器人
Reinforcement Learning 也可以被用在Learning a chat-bot。
chat-bot 是seq2seq,input 就是一句话,output 就是机器的回答。
如果采用Supervised ,就是告诉机器有人跟你说“hello”,你就回答“hi”。
如果有人跟你说“bye bye”,你就要说“good bye”。
如果是Reinforcement Learning 就是让机器胡乱去跟人讲话,讲讲,人就生气了,
machine就知道一句话可能讲得不太好。不过没人告诉它哪一句话讲得不好,它要自己去发掘这件事情。
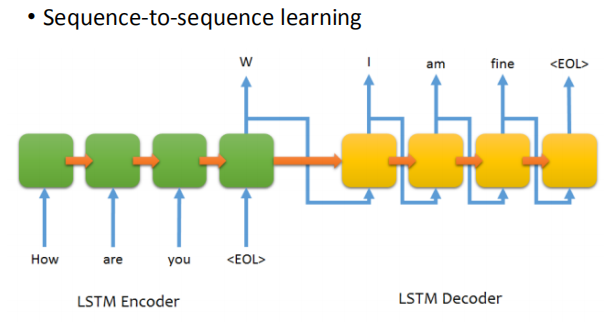
使用强化学习的一种方法是让 Agent 和人对话,Agent 会随机回答,最终可能得到很不好的结果,机器再根据 reward 来调整。
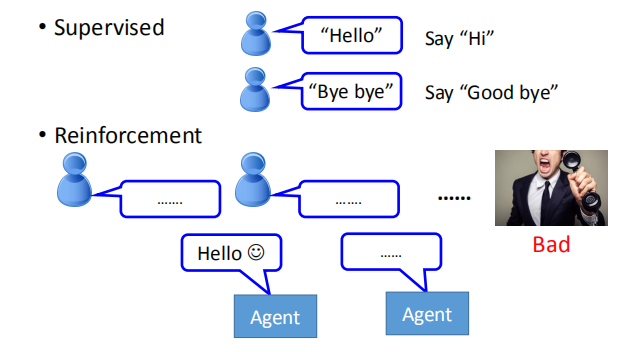
在进行强化学习时,机器要进行大量的对话,一般采取的方法是,
- 让两个机器人互相交谈(有时会产生良好的对话,有时会产生不良影响)。

- 通过这种方法,我们可以生成很多对话
- 使用一些预定义的规则来评估对话的优点
 两个chat-bot互相对话,对话之后有人要告诉它们它们讲得好还是不好。
两个chat-bot互相对话,对话之后有人要告诉它们它们讲得好还是不好。
在围棋里比较简单,输赢是比较明确的,对话的话就比较麻烦,
你可以让两个machine进行无数轮互相对话,
问题是你不知道它们这聊天聊得好还是不好,这是一个待解决问题。
现有的方式是制定几条规则,如果讲得好就给它positive reward ,
讲得不好就给它negative reward,好不好由人主观决定,
然后machine就从它的reward中去学说它要怎么讲才是好。
后续可能会有人用GAN的方式去学chat-bot。通过discriminator判断是否像人对话,
两个agent就会想骗过discriminator,即用discriminator自动认出给reward的方式。
Reinforcement Learning 有很多应用,尤其是人也不知道怎么做的场景非常适合。
1.4 交互式搜索
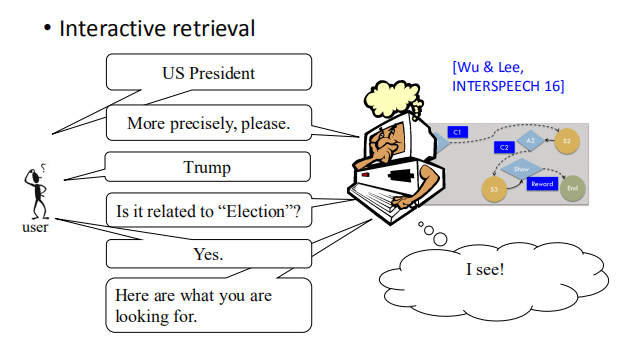 让machine学会做Interactive retrieval,
让machine学会做Interactive retrieval,
意思就是说有一个搜寻系统,能够跟user进行信息确认的方式,
从而搜寻到user所需要的信息。
直接返回user所需信息,它会得到一个positive reward,然后每问一个问题,都会得到一个negative reward。
Reinforcement Learning 还有很多应用,比如开个直升机,开个无人车呀,
也有通过deepmind帮助谷歌节电,也有文本生成等。
现在Reinforcement Learning最常用的场景是电玩。
现在有现成的environment,比如Gym,Universe。
让machine 用Reinforcement Learning来玩游戏,
跟人一样,它看到的东西就是一幅画面,就是pixel,然后看到画面,
它要做什么事情它自己决定,并不是写程序告诉它说你看到这个东西要做什么。需要它自己去学出来。
 机器像人类一样学习如何玩游戏,
机器像人类一样学习如何玩游戏,
-
机器观察游戏画面
-
机器学习采取合适的动作
-
太空入侵者游戏
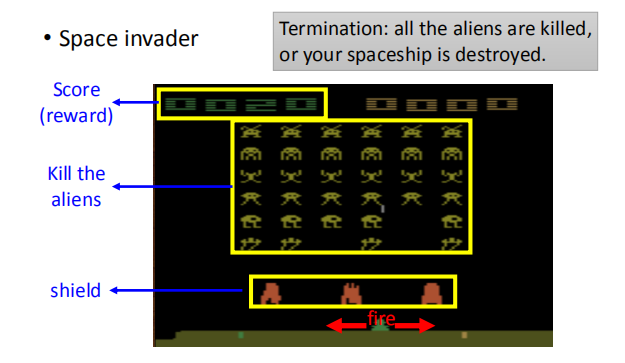 游戏得分为 reward;当所有的外星人被杀光或者飞船被毁游戏结束。
游戏得分为 reward;当所有的外星人被杀光或者飞船被毁游戏结束。
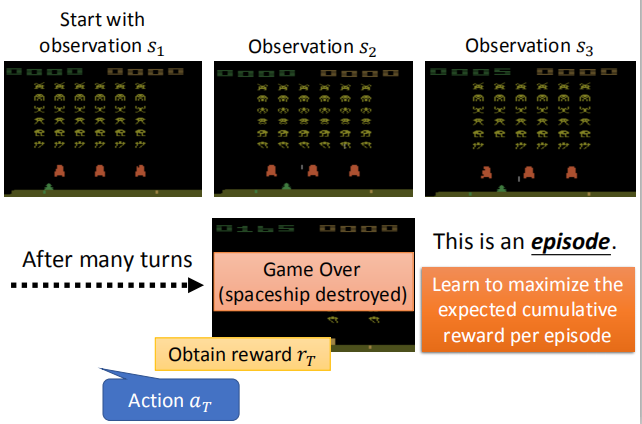
 动作$a_1$:左移, reward为 0;当执行完动作 $a_1 $之后,外星人也进行了一些移动;
动作$a_1$:左移, reward为 0;当执行完动作 $a_1 $之后,外星人也进行了一些移动;
但这种变化与机器采取的动作是没有关系的,有时候环境的变化是纯粹随机的。
动作 $a_2$:开火,reward 为 5。
经过多轮的循环之后,游戏结束(飞船被摧毁);这一过程被称为一个
episode,我们的学习目标是,在每一轮的 episode 中,最大化累积的 reward。
1.5 强化学习的难点
-
奖励延迟
-
在太空入侵的游戏中,仅仅开火这一个动作能够获得奖励,尽管开火前的移动也很重要
-
在下围棋时,牺牲短期的好处以获得长足的利益可能才是更好的选择
-
-
机器的操作会影响其接受的后续数据
- 机器要能够探索他没有做过的行为
2. 强化学习的方法
Reinforcement Learning 的方法主要分为Policy-based的方法和 Valued-based 的方法。
先有Valued-based的方法,再有Policy-based的方法。
在Policy-based的方法里面,会learn一个负责做事的Actor,
在Valued-based的方法会learn一个不做事的Critic,专门批评不做事的人。
我们要把Actor和Critic加起来叫做Actor+Critic的方法。
2.1 用基于策略的方法(Policy-based Approach)学习一个 Actor
先来看看怎么学一个Actor:
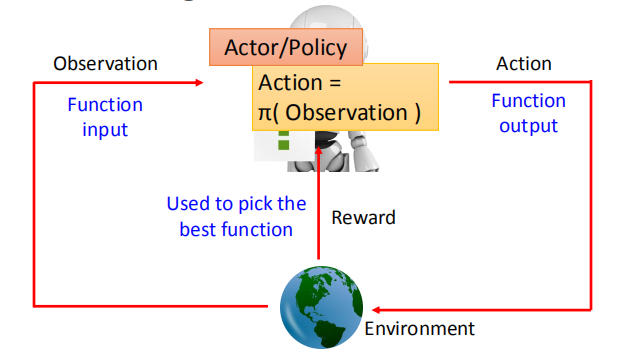
所谓的Actor是什么呢?我们之前讲过,Machine Learning 就是找一个Function,
Reinforcement Learning也是Machine Learning 的一种,所以要做的事情也是找Function。
这个Function就是所谓的魔术发现,Actor就是一个Function。
这个Function的input就是Machine看到的observation,它的output就是Machine要采取的Action。
我们要透过reward来帮我们找这个best Function。
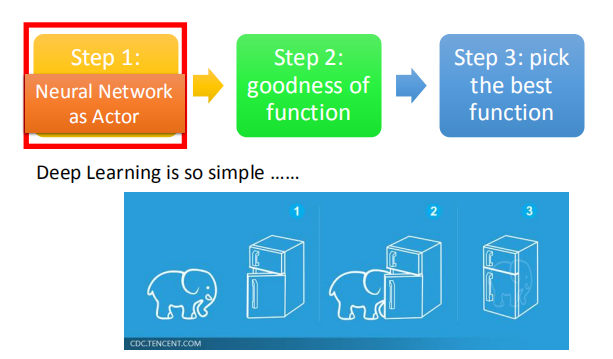
找个这个Function有三个步骤:
第一个步骤就是决定你的Function长什么样子,假设你的Function是一个Neural Network,就是一个deep learning。
 如果Neural Network作为一个Actor,这个Neural Network的输入就是observation,
如果Neural Network作为一个Actor,这个Neural Network的输入就是observation,
可以通过一个vector或者一个matrix 来描述。
output就是你现在可以采取的action。
举个例子,Neural Network作为一个Actor,inpiut是一张image,
output就是你现在有几个可以采取的action,output就有几个dimension。
假设我们在玩Space invader,output就是可能采取的action左移、右移和开火,
这样output就有三个dimension分别代表了左移、右移和开火。
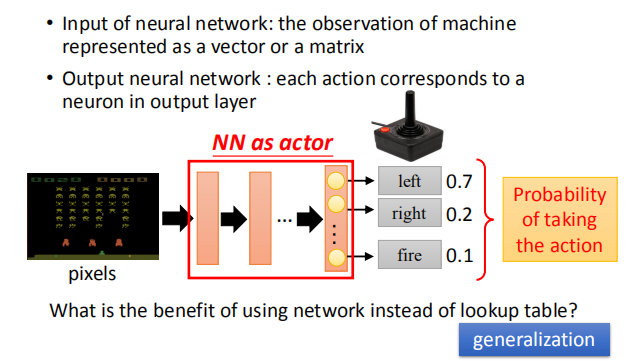 神经网络的输入为机器的 observation,即像素点组成的向量或矩阵,输出对应机器每一个动作的发生概率。
神经网络的输入为机器的 observation,即像素点组成的向量或矩阵,输出对应机器每一个动作的发生概率。
相比于传统的查找表,神经网络有泛化的功能,不用穷举所有输入的情况
第二步骤就是,我们要决定一个Actor的好坏。
在Supervised learning中,我们是怎样决定一个Function的好坏呢?
举个Training Example例子来说,我们把图片扔进去,看它的结果和target是否像,
如果越像的话这个Function就会越好,
我们会一个loss,然后计算每个example的loss,我们要找一个参数去minimize这个参数。
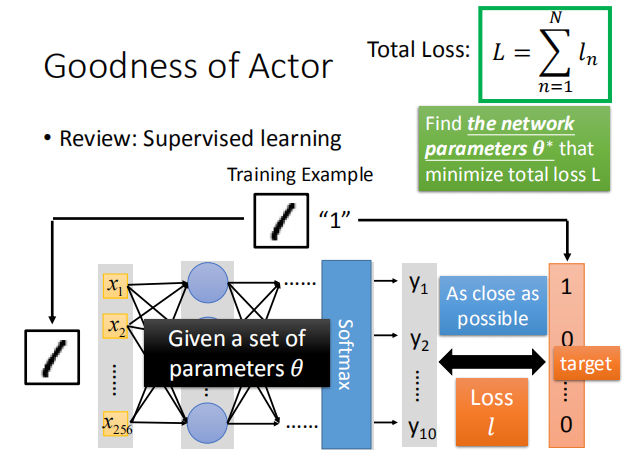 在分类问题中,我们使用交叉熵作为损失函数,我们需要找到最佳的参数 $\theta^*$ 使损失函数最小。
在分类问题中,我们使用交叉熵作为损失函数,我们需要找到最佳的参数 $\theta^*$ 使损失函数最小。
 在强化学习中,我们使用总奖励的期望值 $\bar R_{\theta}$ ,来评估一个 Actor $\pi_{\theta}(s)$ 的好坏
在强化学习中,我们使用总奖励的期望值 $\bar R_{\theta}$ ,来评估一个 Actor $\pi_{\theta}(s)$ 的好坏
 我们使用 $\pi_{\theta}(s)$ 进行 N 次游戏,用 $R_{\theta}$ 的平均值来代替期望 $\bar R_{\theta}$
我们使用 $\pi_{\theta}(s)$ 进行 N 次游戏,用 $R_{\theta}$ 的平均值来代替期望 $\bar R_{\theta}$
怎么选择最好的function,其实就是用我们的Gradient Ascent。我们已经找到目标了,就是最大化这个$\bar{R}_\theta$
然后用梯度下降的方法找到最佳的 Actor:
-
问题描述:
$\theta^* = arg max \bar R_{\theta}$ $\bar R_{\theta}$ = $\sum_{\tau} R(\tau)P(\tau|\theta)$
- 梯度下降:
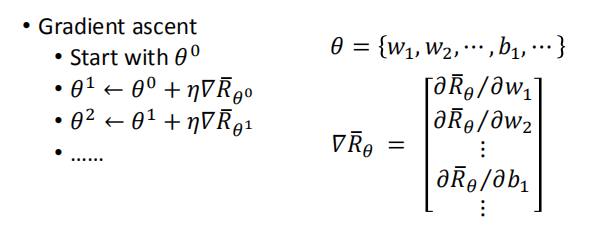
因为我们只能改变 $\theta$ 来改变 Actor,所以只对 $\theta$ 求导。
 这里我们同样需要使用样本的概率来代替 $P(\tau|\theta)$
这里我们同样需要使用样本的概率来代替 $P(\tau|\theta)$
- $P(\tau|\theta)$ 的计算:
其中有些概率项和 Actor 无关,有些与 Actor 有关

- 计算$\nabla$ $\log{P(\tau|\theta)}$:
忽略掉与 $\theta$ 无关的部分

最终的计算结果:
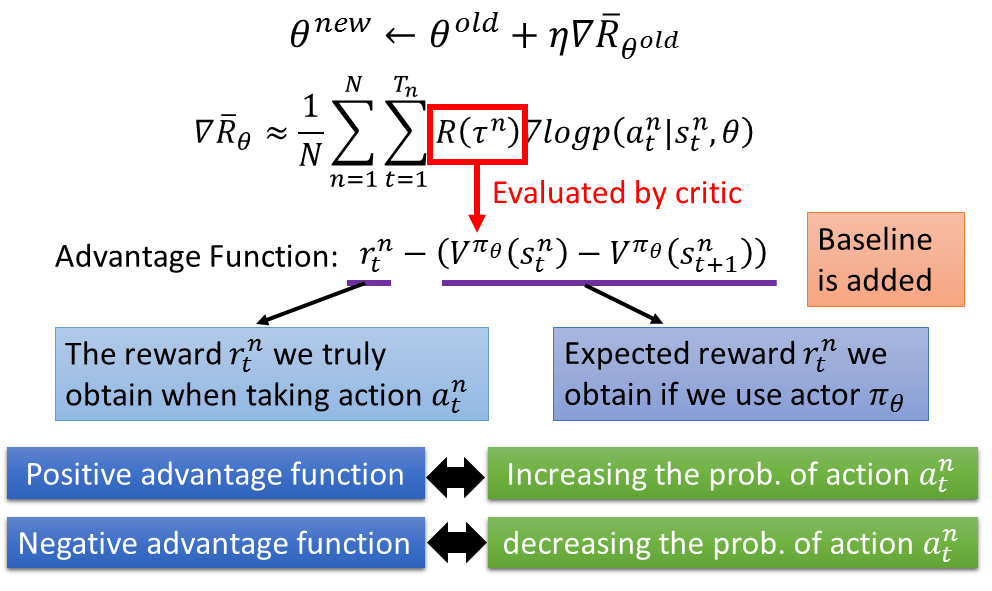
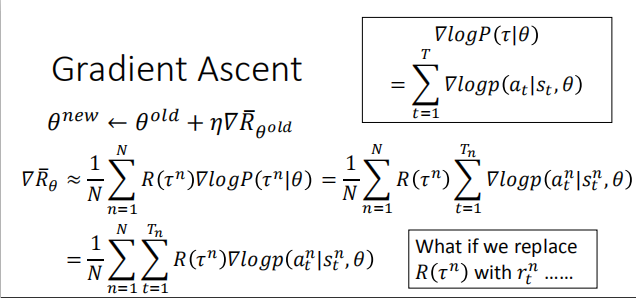 当 R 为正时,调整 $\theta$ 的值,来增大某一个动作发生的概率。
当 R 为正时,调整 $\theta$ 的值,来增大某一个动作发生的概率。
当 R 为负时,调整 $\theta$ 的值,来减小某一个动作发生的概率。
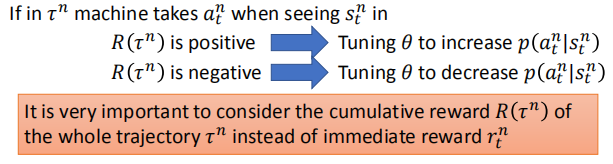 我们使用累计的 reward 而不是及时的奖励。
我们使用累计的 reward 而不是及时的奖励。
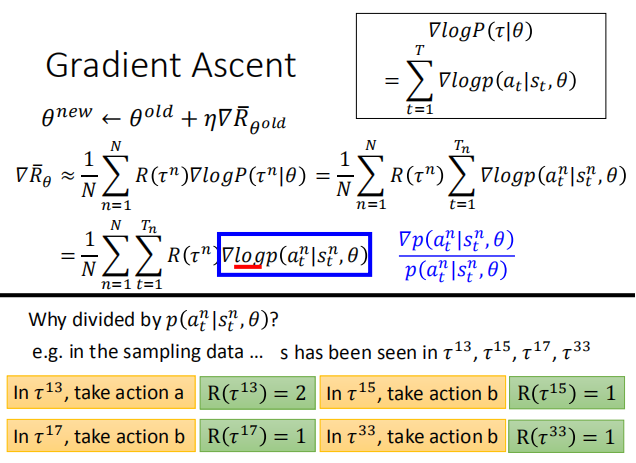
-
1.当 $R_{\theta}$ 一直为正时,并不会影响那些 reward 值较大的动作;
因为最后神经网络要经过 softmax 来输出每个动作的概率,那些 reward 较小
的动作,发生的概率也会相应减小。 -
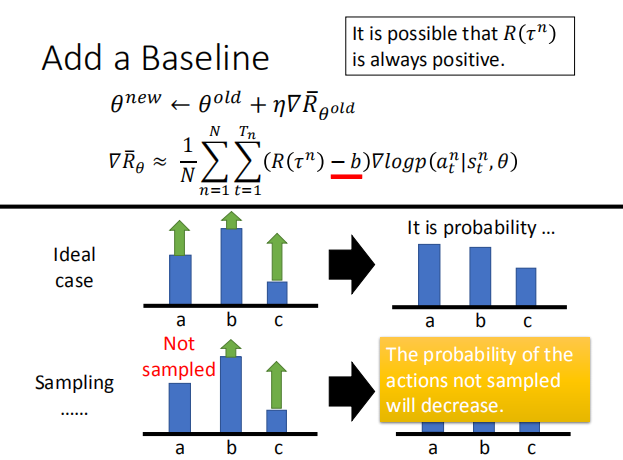
2.在采样的过程中,我们可能会遇到某一个 action 不被采样的情况,这时我们需要添加
一个 baseline,只有 reward 超过 baseline 的动作发生的概率才会增加。这样某些动作
不被采样的概率将会减小。
2.2 用基于价值的方法(Value-based Approach)学习一个 Critic
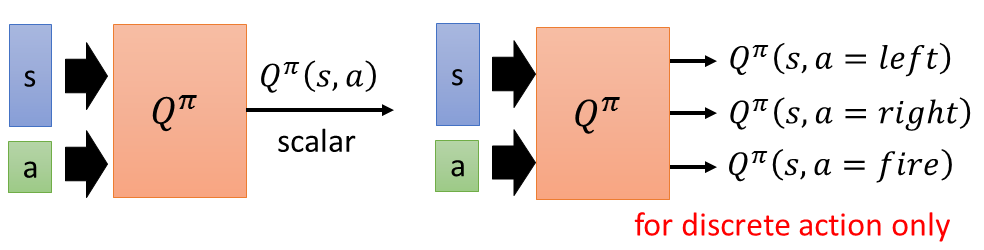
Critic就是Learn一个Neural Network,这个Neural Network不做事,然后Actor可以从这个Critic中获得,这就是Q-learning。
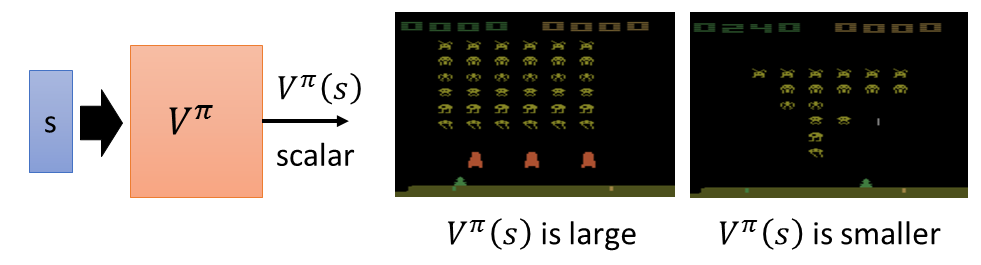
Critic就是learn一个function,这个function可以告诉你说现在看到某一个observation的时候,这个observation有有多好这样。
- 根据actor π 评估critic function
这个function是用Neural Network表示
- state value function $V^\pi(s)$
这个累加的reward是通过观察多个observation
 那么如何估计 $V^\pi(s)$ 呢?可以采用Monte-Carlo based approach。
那么如何估计 $V^\pi(s)$ 呢?可以采用Monte-Carlo based approach。
- State-action value function $Q^π(s,a)$
这个累加的reward是通过观察observation和take的action
2.3 Actor-Critic
该部分在李宏毅课程的第二个学期中介绍:https://www.bilibili.com/video/av35757082/?p=33