这一节我们主要学习
- 生成模型(Generative Models)
- 像素循环神经网络(PixelRNN)
- 变分自编码器(Variational Autoencoder(VAE))
1. 生成模型(Generative Models)

Generative Models:
https://openai.com/blog/generative-models/
凡我不能创造的,我都没有理解
Generative models ,就是在做创造的事情。
- 生成模型分类
- PixelRNN
- Variational Autoencoder(VAE)
- Generative Adversarial Network(GAN)
2. 像素循环神经网络(PixelRNN)
2.1 介绍像素循环神经网络
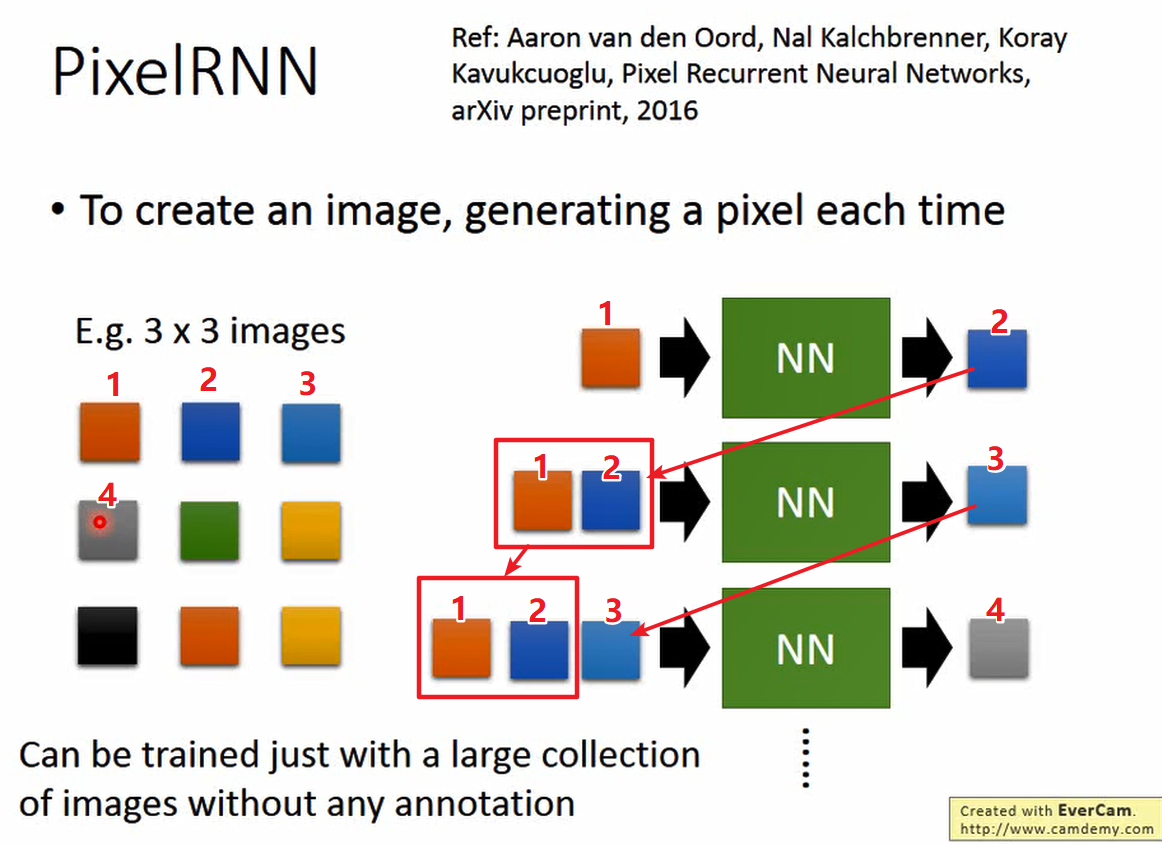
PixelRNN 根据前面的像素预测接下来的像素。
假设生成一个3X3的 image ,流程如下:
- 将1作为RNN的输入,输出为2;
- 将1,2作为RNN的输入,输出为3;
- 将1,2,3作为RNN的输入,输出为4;
依次内推,输出3X3大小的image。

PixelRNN 不仅有效,而且在各种生成方法中 PixelRNN 产生的图是最清晰的。
上图的狗是真实世界的图片,假设只知道图片的上半身:
然后用模型预测出狗的下半身,如上图所示。
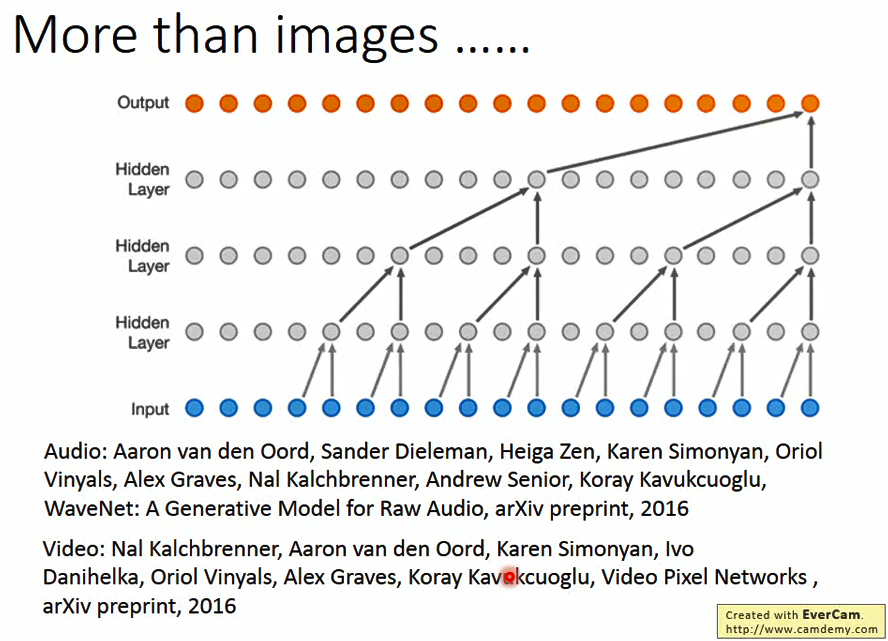
上述技术还可以应用于语音方面,如下图:
2.2 练习生成宝可梦模型

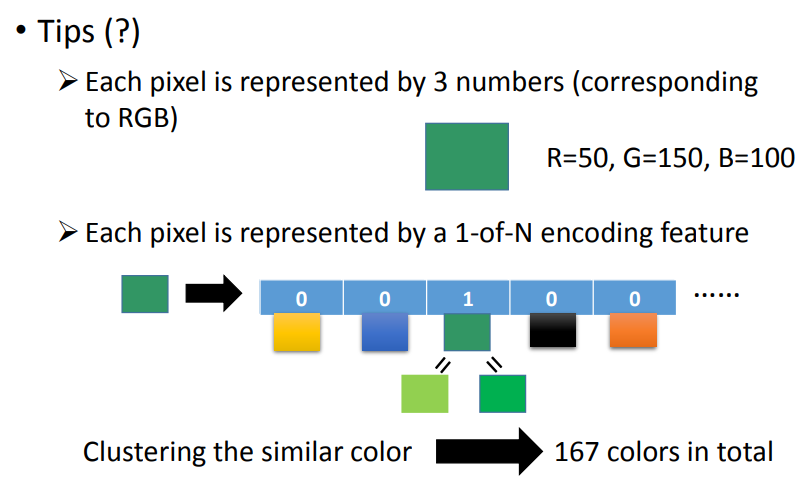
用在图像上有一些 tips : 如果 RGB 三个值相差不大,
则得到的颜色灰灰的、不够明亮,
可以把众多颜色聚成若干类然后做 1-of-N encoding 。
颜色一共有256X256X256种可能,然后把相似的颜色算作一种类别,最后生成167种颜色。

预测结果如下:

上图中宝可梦未在训练集中出现过。
如果要计算机从空白开始画,要给一个随机数,以免每次画出来的都一样。
3. 变自编码器(Variational Autoencoder (VAE))
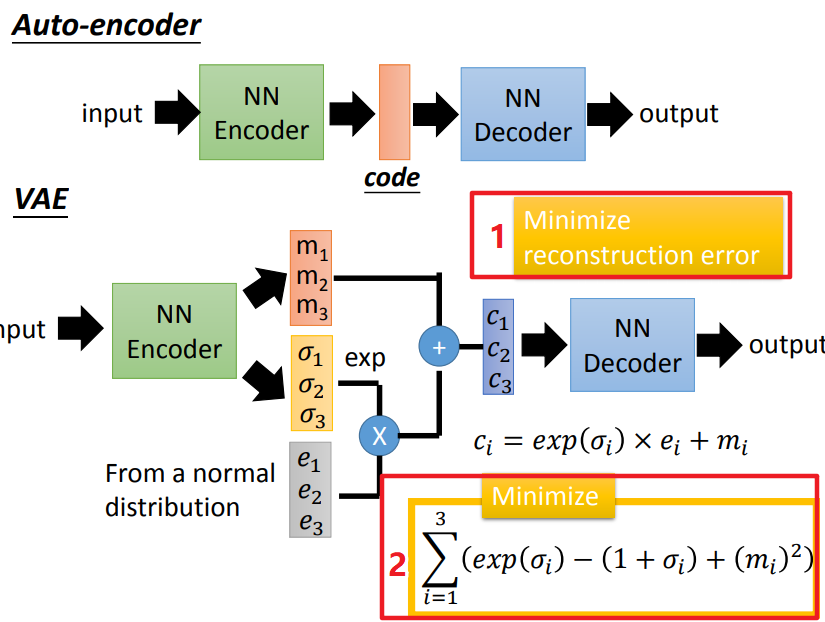
- AutoEncoder
根据自编码器的知识,最初的想法是利用解码器,
随机产生一个 code 作为输入向量,来产生图像,但是效果并不理想。
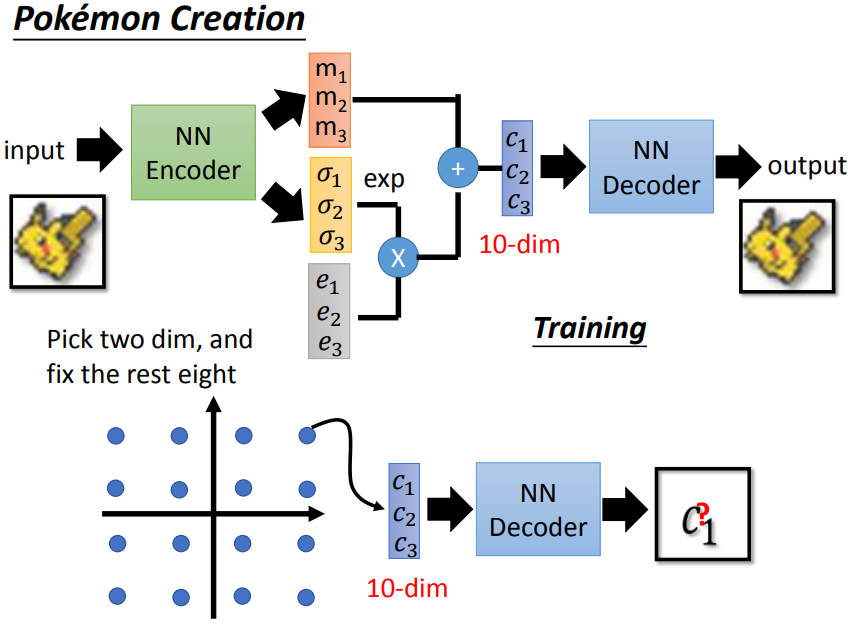
- VAE
对编码器的输出做出改变,如上图所示。
假设code维度是三维,则:
编码器的输出m1、m2、m3是原始code,
σ1、σ2、σ3视为添加的噪声的方差,这是自动学习的,通过指数操作保证非负,
e1、e2、e3是系数;
根据公式计算得到的新的 code 是带噪声的。
然后通过解码器得到输出,并且能够最小化重构误差(图中红色方框1)和最小化公式2(图中红色方框2)。
如果在学习时,仅仅最小化重构误差会怎样呢?
显然,噪声方差为0就能使得误差最小,但这和我们的想法不一致。
所以在上图右下方,在学习时不仅要最小化重构误差也要最小化该公式的值。
3.1 VAE 生成宝可梦
VAE 得到的结果不太清楚。
VAE 与 PixelRNN 区别在于:**理论上 VAE 可以控制要生成的 image **。
比如 code 是10维,固定其中8维、调整剩余2维,
看结果,可以解读 code 的每个维度代表什么意思,
从而每个维度就像拉杆一样可以有目的的调整。

3.2 VAE 写诗
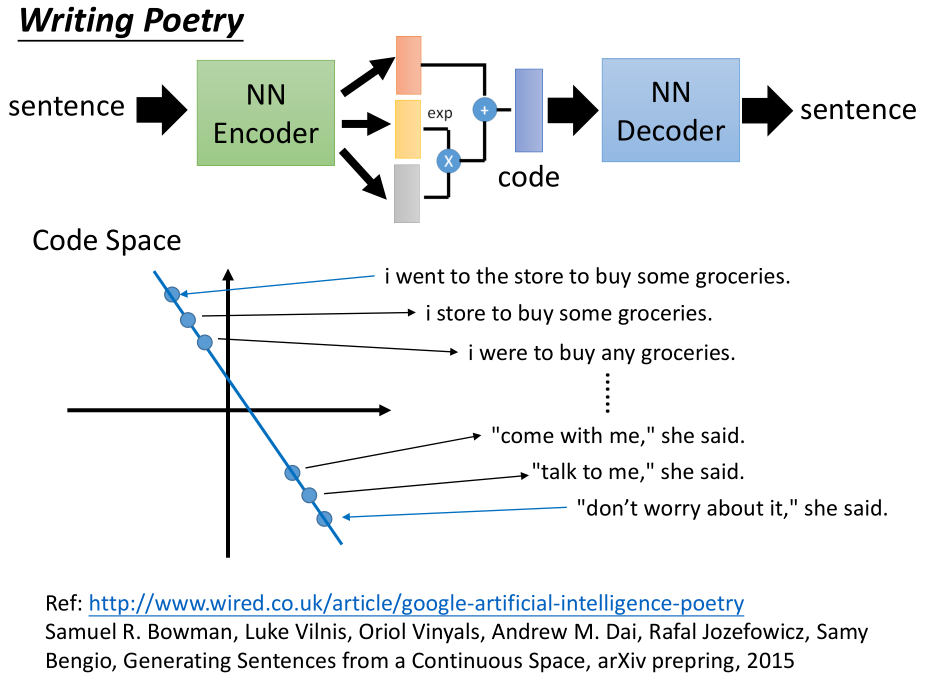
先任意选两个句子,经过 encoder 得到这两个句子的 code ,
在 code space 上是两个点,连接两点、等距采样、用 decoder 还原,得到一系列句子。
4. 总结
- 生成模型
- 生成模型方法之 PixelRNN
- 生成模型方法之 Variational AutoEncoder(VAE)