这一节我们主要学习
- 激活函数(activation function)
- 自适应学习率(Adaptive Learning Rate)
- 早停法(Early Stopping)
- 正则化(Regularization)
- Dropout
1. 前言
1.1 如何评估训练出的神经网络
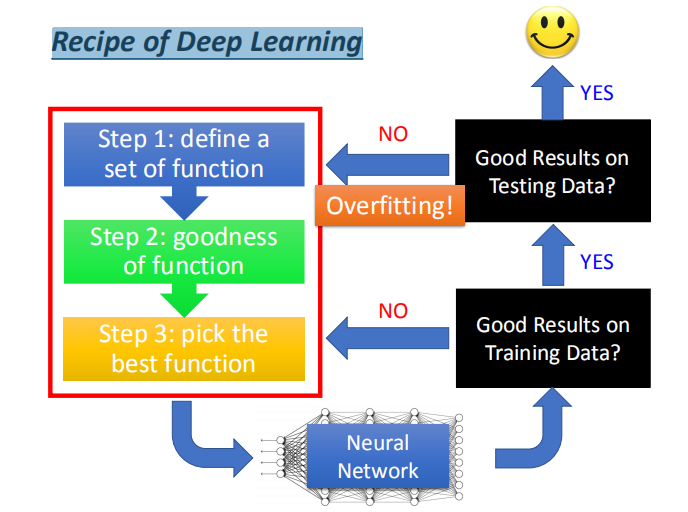
- 我们通过深度学习的三个步骤得到一个神经网络,那么如何判断我们得到的是不是一个好的神经网络呢?
- 首先,要判断该神经网络在训练集上的表现(深度学习不能保证模型在训练集上的表现)。
如果表现不好,要回到开始的三个步骤进行调整,直到其在训练集上表现好为止。 - 其次,检查我们已经得到的在训练集上表现好的神经网络在测试集的表现。
如果表现不好,则是出现了过拟合,回到开始的三个步骤进行调整。
如果表现是好的,那么我们得到了一个好的深度神经网络。
- 注意要通过正确的步骤对深度神经网络进行评估,
这样才能发现问题所在,而不是效果不好则盲目责怪过拟合,比如:
 该图片取自论文:图像识别中的深度残差学习 <font size=3.5>http://arxiv.org/abs/1512.03385</font>
该图片取自论文:图像识别中的深度残差学习 <font size=3.5>http://arxiv.org/abs/1512.03385</font>
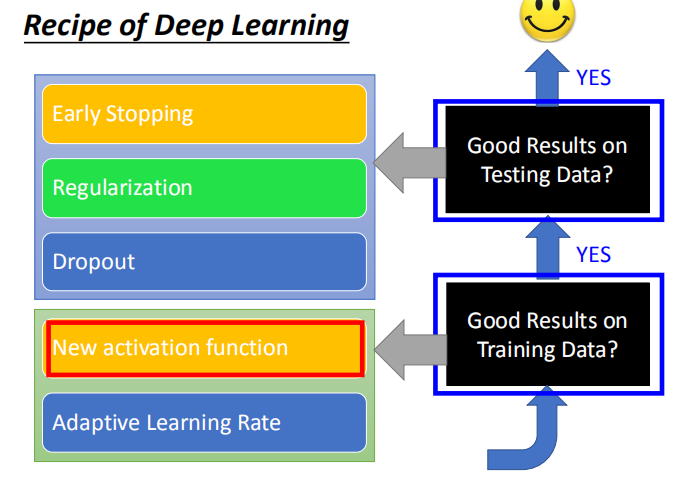
1.2 对模型进行改进
- 提高模型在训练集上的表现:
- 1.激活函数
- 2.自适应学习率
- 提高模型在测试集上的表现:
- 1.早停法
- 2.正则化
- 3.Dropout
2. 提高模型在训练集上的表现
2.1 更换新的激活函数
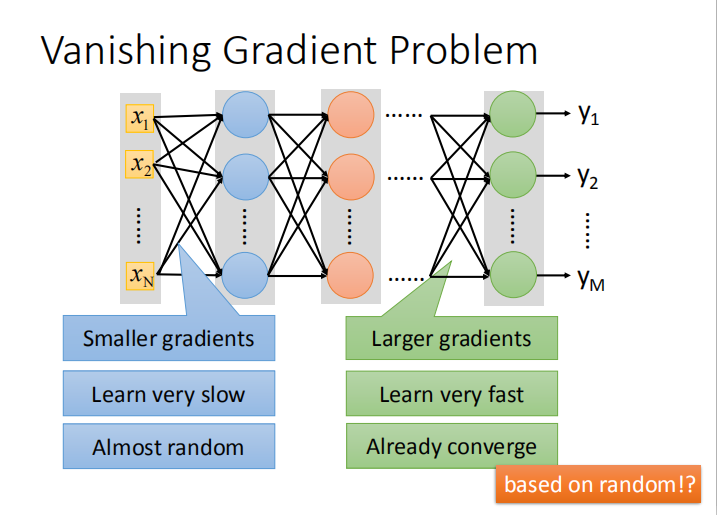
- 当神经网络比较深的时候,若激活函数为 sigmoid 函数且每个参数学习率一致,会发生梯度消失问题,导致模型可能收敛的结果比较差。
- 理论上,可以设置动态的学习率来解决梯度不一致的问题。但是更有效的方法是换掉导致该问题的元凶 —— sigmoid 函数。
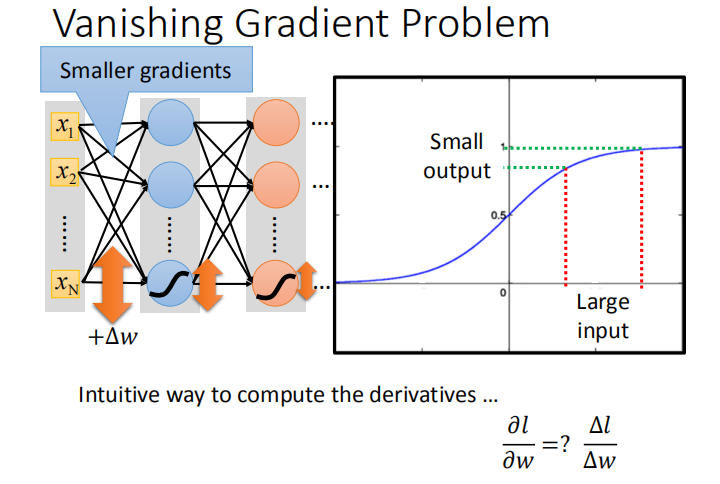
- 使用 ReLU 函数的原因:
- 1.计算速度快
- 2.生物学上的理由
- 3.相当于无限个不同偏差的 sigmoid 函数叠在一起
- 4.可以解决梯度消失问题
- Rectified Linear Unit(ReLU):
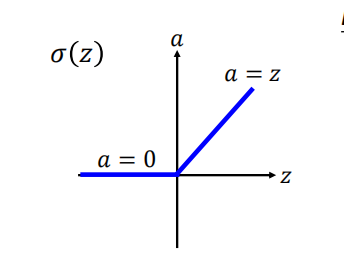
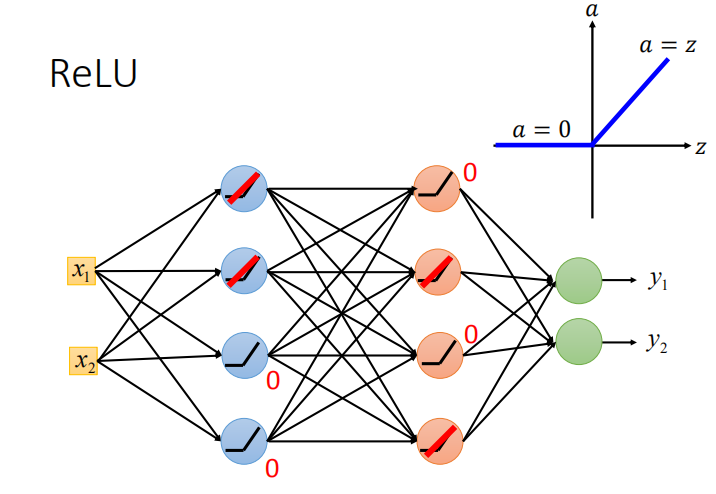
- 使用 ReLU 函数代替 sigmoid 函数可以解决梯度消失的问题是因为:
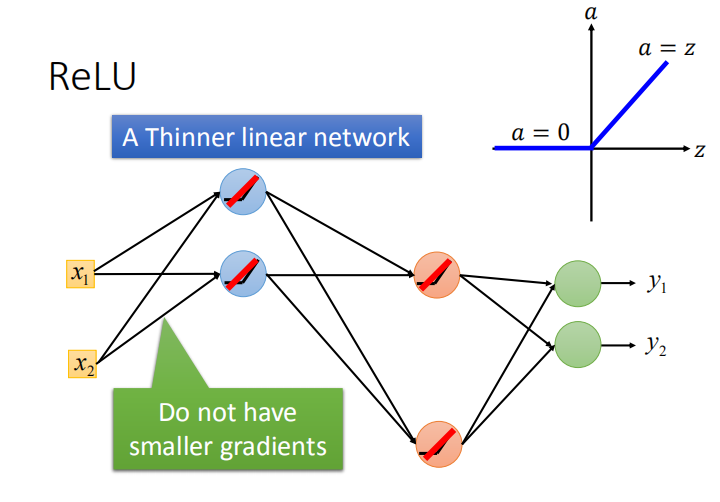
- 作用在输入大于零区域的神经元相当于线性函数,作用在输入小于零区域的神经元相当于消失。
- 整个网络会变成一个很瘦的线性网络,靠近输入层的参数梯度就不会特别小,从而解决了梯度消失问题。
- 但是网络只是在小范围内是线性的,整体来说总的网络还是非线性的。
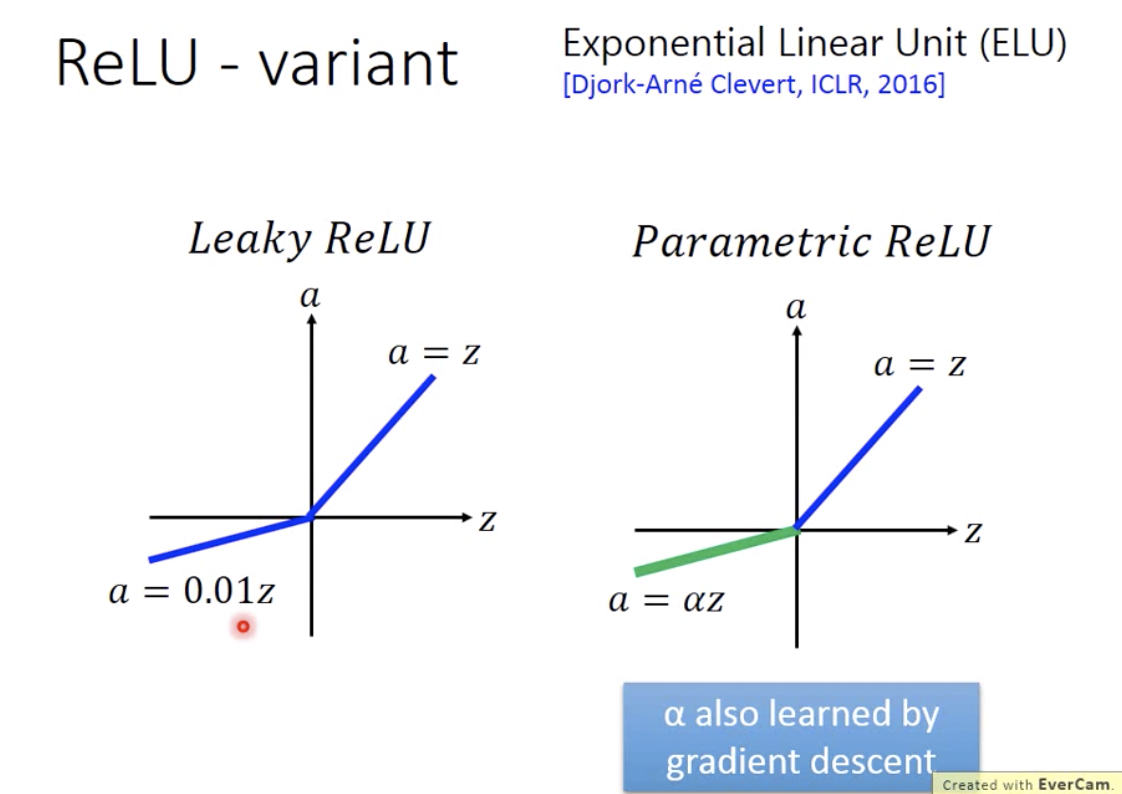
- ReLU 的变形:带泄露线性整流函数(Leaky ReLU)、参数线性整流函数(Parametric ReLU)、Exponential Linear Unit
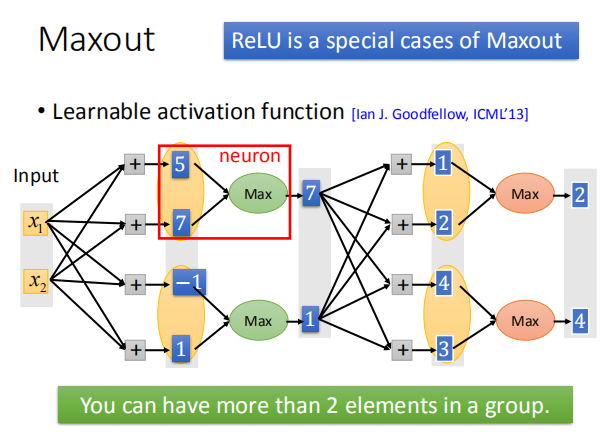
- Maxout Network 的运作方式:
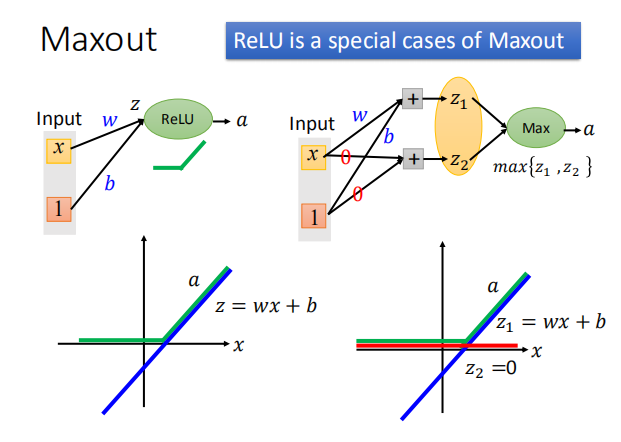
- Maxout Network 怎么产生 ReLU:
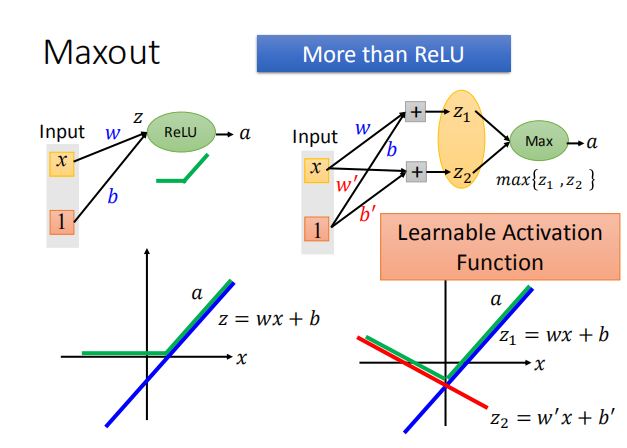
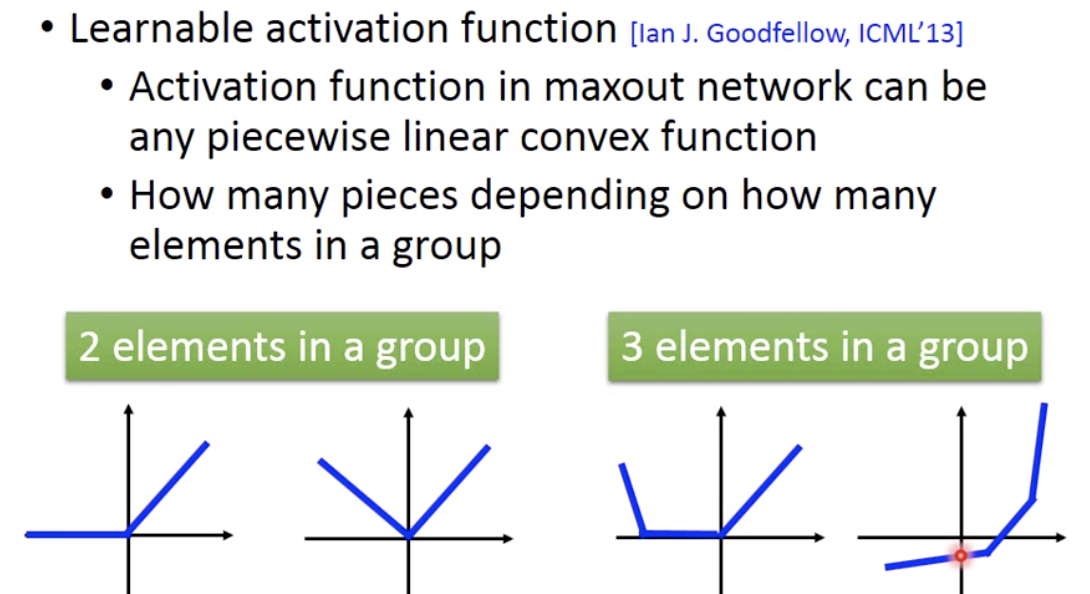
- Maxout Network 可以产生其他的类似 ReLU 的函数:
- Maxout Network 生成激活函数的特点:1.分段线性凸函数 2.分段数取决于组中的元素数
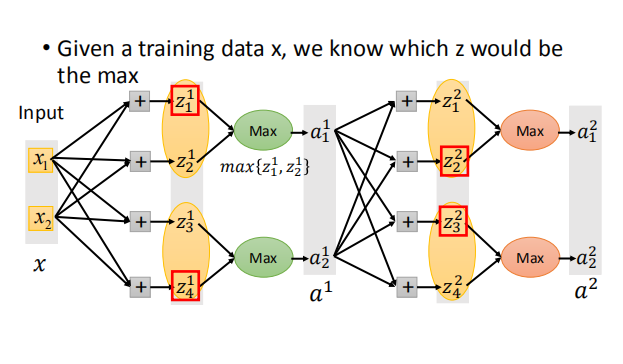
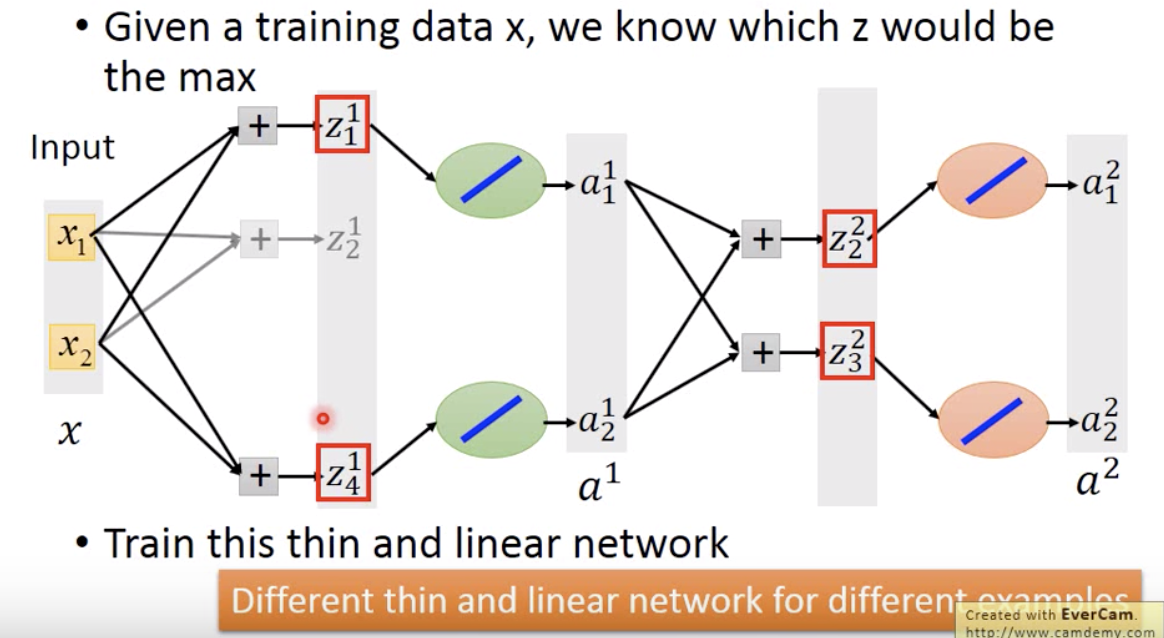
- Maxout Network 训练:看似不能算偏微分,其实给定输入的时候,网络是线性的。而且对于不同的输入对应不同的线性网络,保证所有的参数都可以被训练到。
2.2 自适应学习率(Adaptive Learning Rate)
- 在讲梯度下降时已经讨论过 Adagrad——我们用一次微分来估计二次微分的值。这建立在二次微分比较固定的情况下,但是实际情况是很复杂的。

- 实际训练神经网络时,误差曲面可能非常的复杂。
- 如图,在梯度比较大的时候,我们需要小一点的学习率;在梯度比较小的时候,我们需要大一点的学习率,以保证损失函数正常收敛。所以我们一般会用比 Adagrad 效果好一点的 RMSProp。

- RMSProp 其实是和 Adagrad 一样的思路,只是在求分母的时候考虑了历史梯度和新梯度的权重,如图:
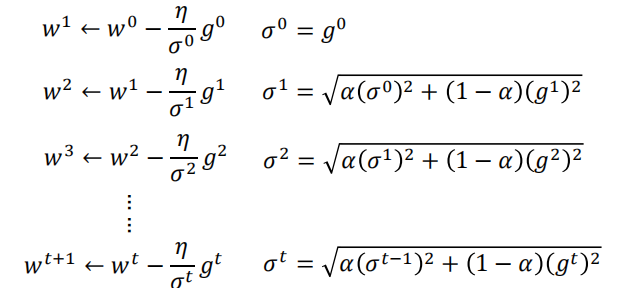
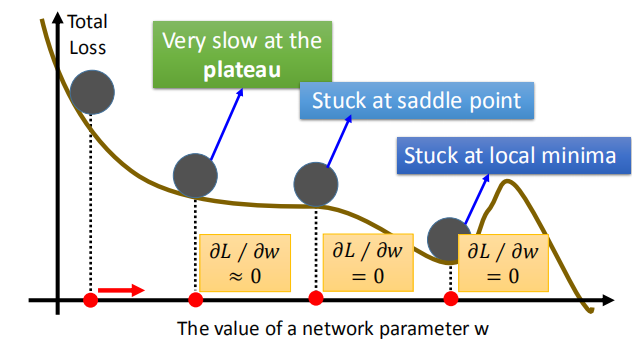
- 在训练时可能会遇到三大问题:
- 参数更新太慢
- 函数卡在鞍点
- 函数卡在局部最小点
- 把物理世界中“惯性”这一概念应用到梯度下降中,使得参数移动不仅取决于当前的梯度,而且受前一次移动的影响,从而有希望冲出局部最优点,去寻找全局最优点。
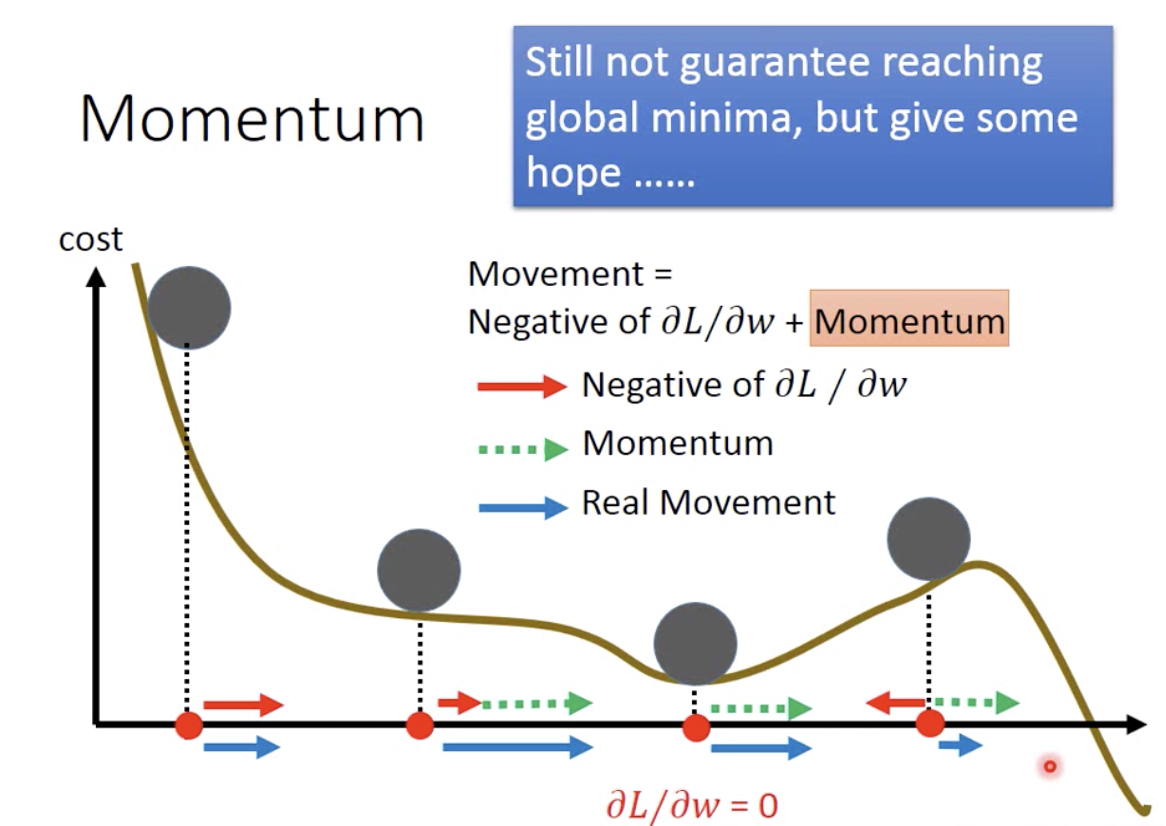
- 简单梯度下降和添加动量的梯度下降的对比:
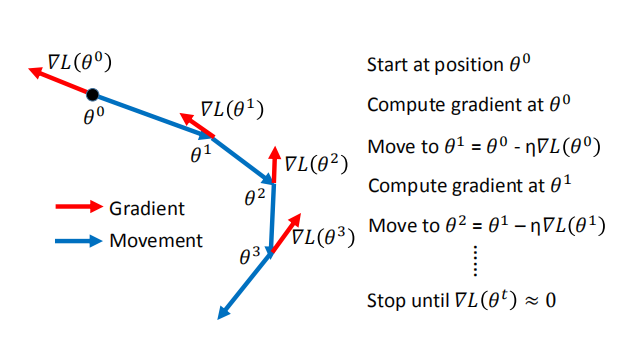
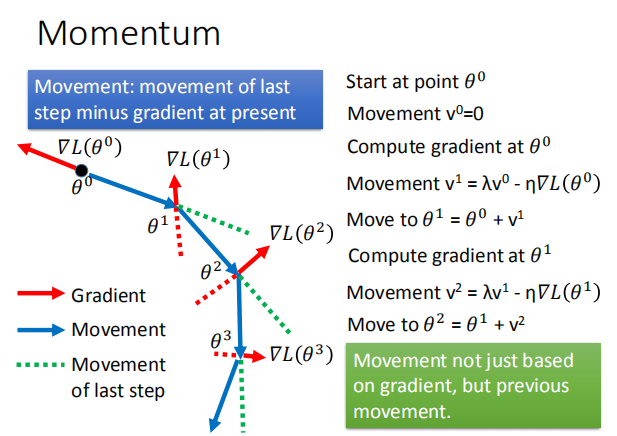
- 说明为什么只考虑前一次的移动方向就是考虑过去所有的移动方向:

- Adam = RMSProp + Momentum:

3. 提高模型在测试集上的表现
3.1 早停法(Early Stopping)
- 在实际训练的过程中,学习率设置正确的情况下,随着训练的次数(epochs)增加,模型在训练集上的准确率会越来越高,但在测试集上的准确率随着过拟合的出现反而开始变差。所以我们需要一个告知我们即将出现过拟合的机制——早期停止,来保证测试集上最好的效果。但由于不能边训练边测试,于是引入了验证集(Validation set)来做计算。
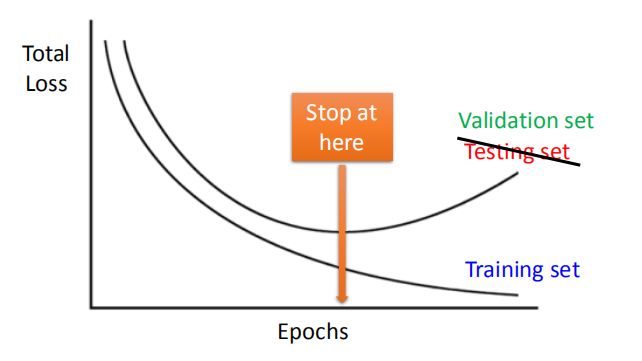
- Keras: <font size=3.5>http://keras.io/getting-started/faq/#how-can-i-interrupt-training-when-the-validation-loss-isnt-decreasing-anymore </font>
3.2 正则化(Regularization)
- 在损失函数后面添加一个系数的“惩罚项”是正则化的常用方式,为了防止系数过大从而让模型变得复杂。
- $\lambda$ 是一个超参数,用于控制正则化程度
- 使新的损失函数达到最小,找到一组权重不仅使原始的损失函数最小,而且使权重接近 0

- L2 正则化通过让原损失函数加上了所有特征系数的平方和来实现正则化。
- 可以看出每次更新时,会对特征系数进行一个比例的缩放,这会让系数趋向变小而不会变为 0,因此 L2 正则化会让模型变得更简单,防止过拟合。

- L1 正则化通过让原损失函数加上了所有特征系数绝对值的和来实现正则化。
- 每次更新会加减一个常数,所以很容易产生特征的系数为 0 的情况,特征系数为 0 表示该特征不会对结果有任何影响,因此 L1 正则化会让特征变得稀疏,起到特征选择的作用,从而防止过拟合。

- 同为防止过拟合的办法,如果在深度学习中使用早期停止的话,正则化相对没有必要。
3.3 Dropout
- Dropout 是一种有深度学习特色的办法。
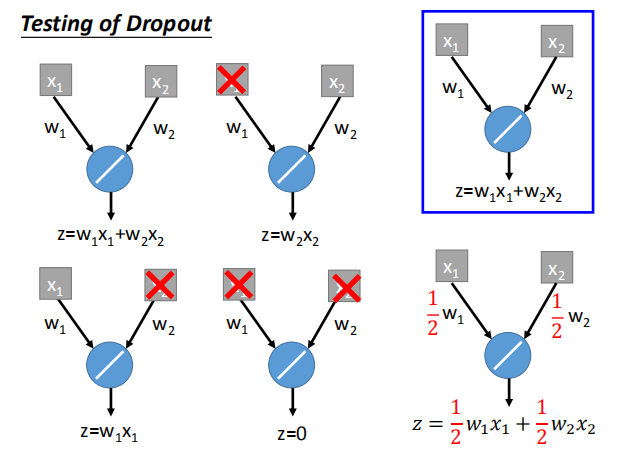
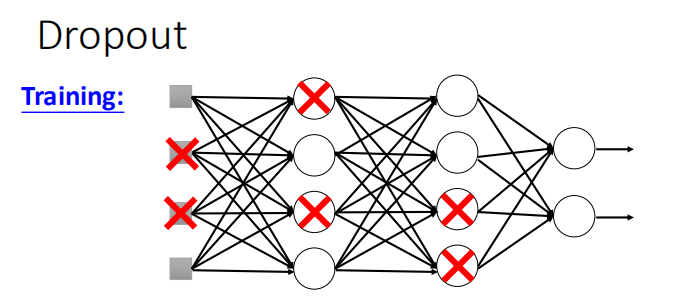
- Dropout 运作方式
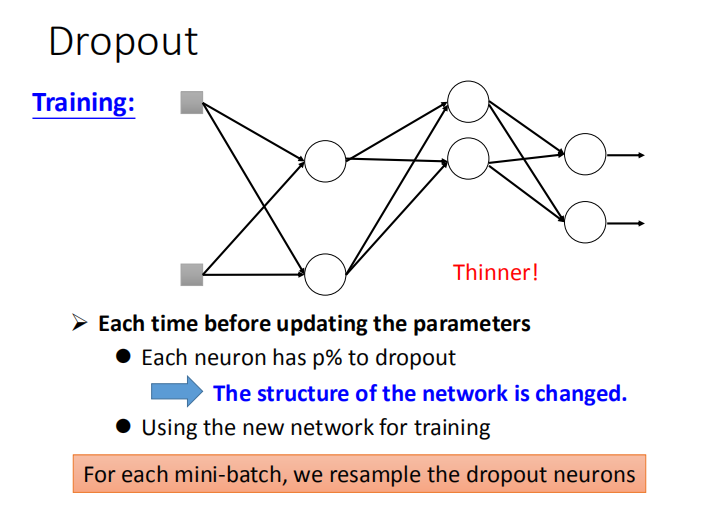
- 每次更新参数之前,对神经元(包括输入层的维度)进行抽样。每个神经元有 p% 的概率失活。
- 抽样后,对变瘦的神经网络进行训练。对于每一个mini-batch,都要重新采样神经元。
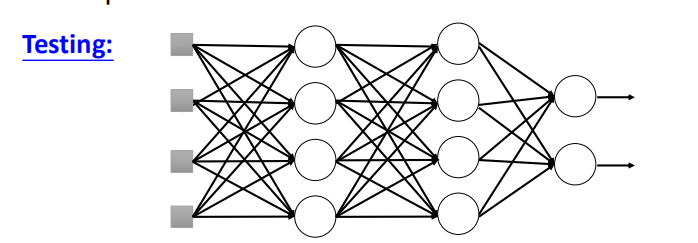
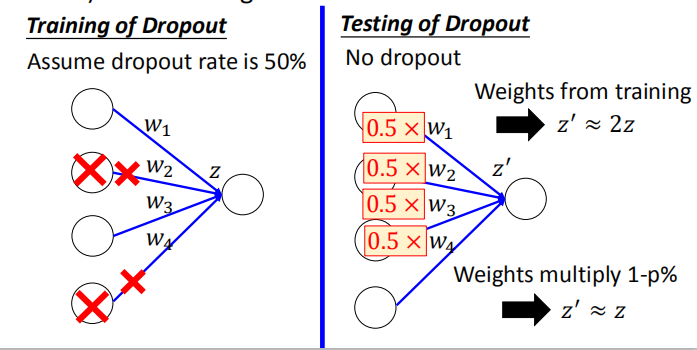
- 对训练完成的整个网络结构进行测试。如果训练时神经元的失活率为 p% ,测试时的所有权重都要乘以 1-p%
- 为什么训练的时候要用 Dropout,测试的时候不用:

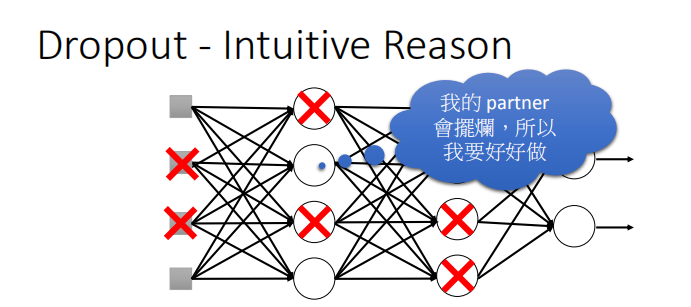
-
团队合作时,如果每个人都期望其他人来工作,那么团队最终什么都做不成;
然而,如果你知道你的合作伙伴会什么都不做,那你会做得好一点;
到测试时会发现其实每个人都有好好工作,所以最终会取得好的结果。 -
测试时所有权重都要乘以(1-p%)的直观原因:
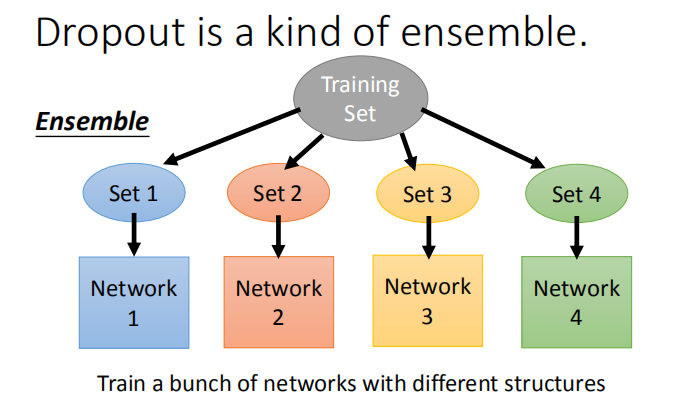
- 集成学习的运作方式:训练时,划分训练集分别训练;测试时,将数据输入所有训练好的模型求平均作为最后的结果。
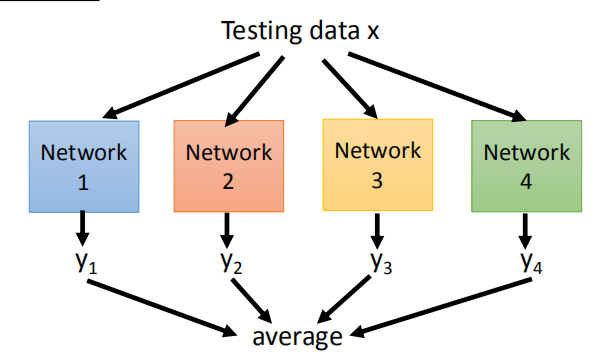
- Dropout 的运作方式:训练时,一个Mini-batch训练一个网络,但网络中的参数是共享的;
测试时,将所有权重乘以(1-p%),输入数据得出结果。且这个结果和继承学习取平均得到的结果近似相等。

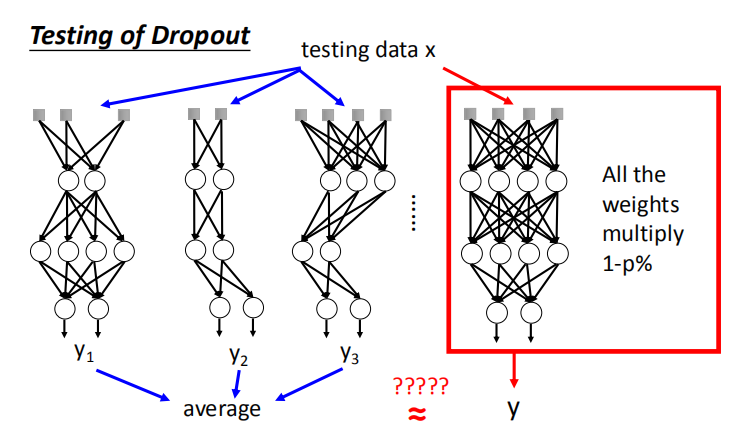
- 为什么 Dropout 的测试结果和继承学习的结果近似相等,这里举一个最简单的网络作为例子。
但是这个例子的理论不适用于非线性网络。不过,Dropout 对于非线性的网络还是适用的,
只是 Dropout 应用于线性网络的话效果会特别好。