这节我们主要学习
- 1.卷积神经网络(CNN)简介
- 2.CNN模型
- 3.在Keras中实现CNN
- 4.理解CNN实际在做什么
- 5.CNN的一些应用
1. CNN 简介
1.1 为什么使用卷积神经网络
典型的深度学习模型就是很深的神经网络,包含多个隐含层,多隐含层的神经网络很难直接使用BP算法进行直接训练。
因为反向传播误差是往往会发散,很难收敛。
为什么使用卷积神经网络处理图像问题:
- 使用比整个图片小很多的图案
通常一个神经元不需要通过整个图片来发现一些图案;
即神经元只需要选取一些特征图案就可做出判断,如通过判断鸟嘴来分类鸟,而不是使用鸟的整张图片。
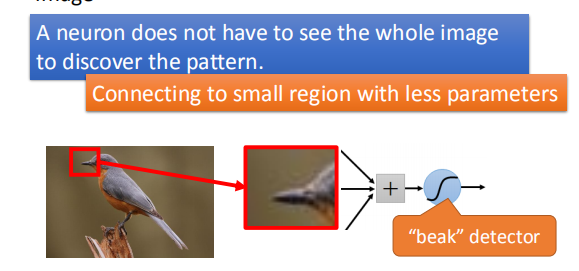
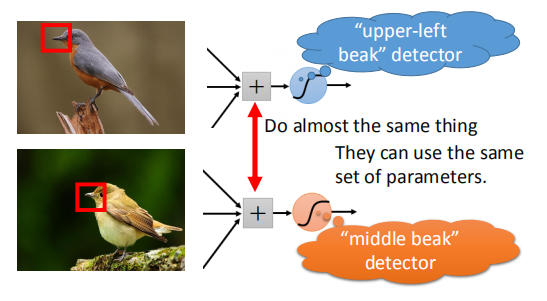
- 相同的图案出现在不同的地区
对整张图片中不同位置的相同图案进行提取,并且可以使用相同的参数设置进行训练。
如下图,不同位置的鸟嘴,不用分别设置 detector 处理,直接使用相同参数相同 detector(下文详解)。
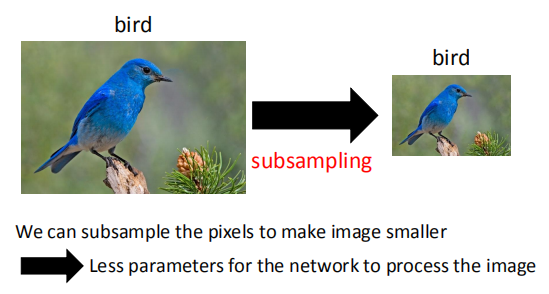
- 对像素进行二次采样不会更改对象
二次采用可以减小图片尺寸,但不改变图像中特征图案,即对训练结果没有影响。
1.2 整个 CNN 模型架构
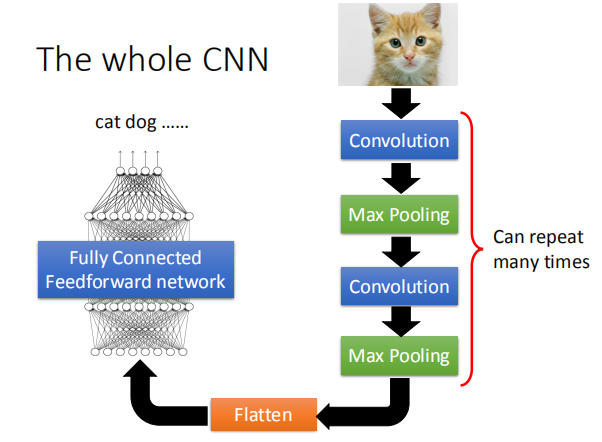 CNN 模型中图像处理具有以下性质:
CNN 模型中图像处理具有以下性质:
性质1:使用比整个图片小很多的图案
性质2:能够处理不同区域相同的图案
性质3: 对像素进行二次采样不会更改对象
性质1和2使用卷积操作实现,性质3使用最大池化操作实现。
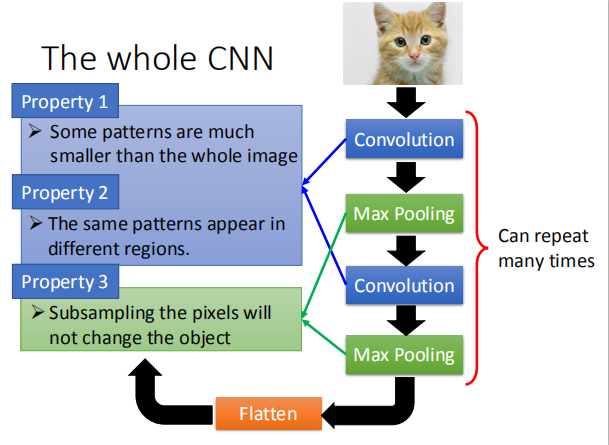
2. 卷积神经网络主要内容
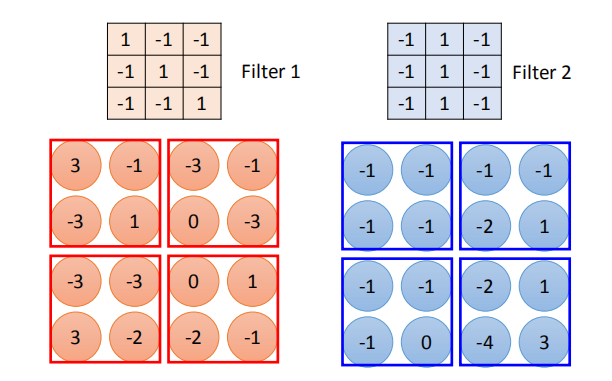
2.1 卷积操作
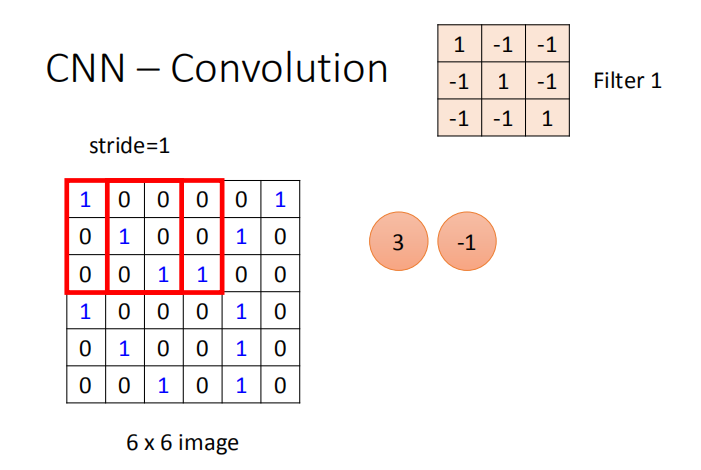
卷积过程如下。首先,将过滤器叠加在图像数组的左上部。
接下来,对过滤器及其目前所在的图像子部分执行对应元素乘积。
也就是说,将过滤器的左上部元素与图像的左上部元素相乘,依此类推。
然后,将这些结果相加来生成一个值。接着,将过滤器在图像上移动一段距离(称为步幅),并重复该过程。
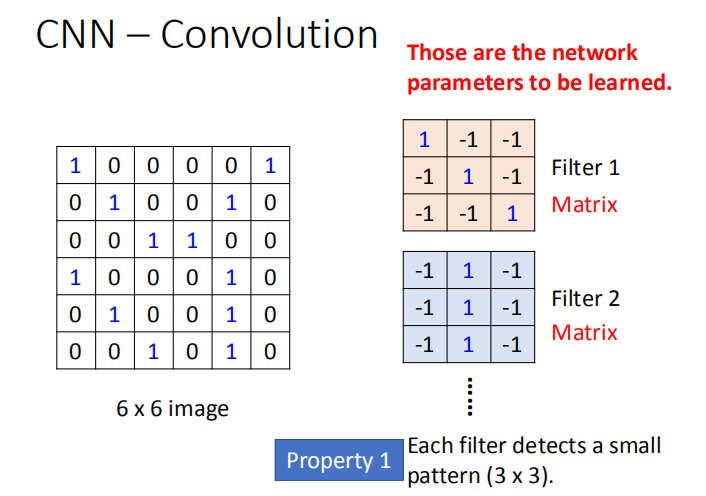 卷积核(也叫过滤器): Filter1,Filter2,$…$;需要一个人为设计卷积核的大小和个数, 这里大小是一个 3X3 的矩阵。
卷积核(也叫过滤器): Filter1,Filter2,$…$;需要一个人为设计卷积核的大小和个数, 这里大小是一个 3X3 的矩阵。
因为使用卷积操作可以将图片的局部特性提取出来,所以实现了性质1,使用比图像小的特征图案。
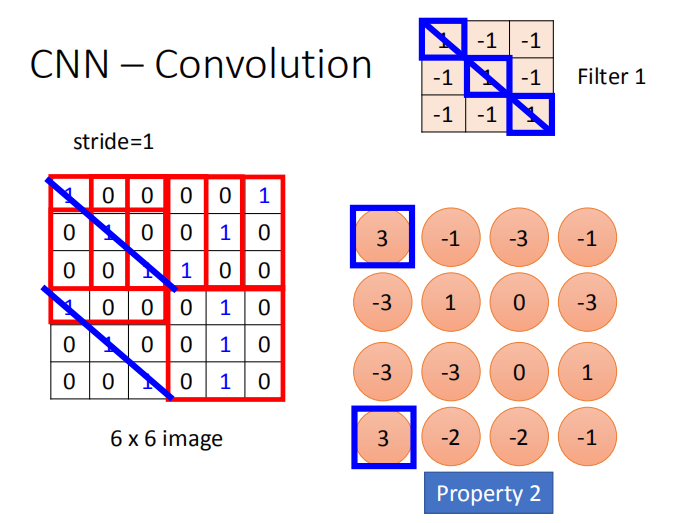
确定卷积操作的步长 stride:
stride=1(每次操作向右移动一列):
 stride=2(每次操作向右移动两列):
stride=2(每次操作向右移动两列):
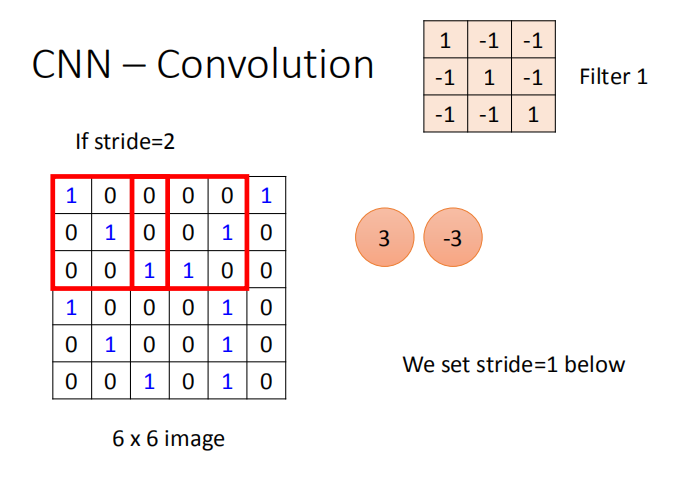

使用卷积操作提取图像的特征,因为卷积核扫描整个图像,所以在不同区域的特征图案都会被提取到,这也是性质2的实现。
特征图谱: 采用不同的过滤器,得到不同的特征图谱。
2.2 对彩色图片作卷积
图像是一种二阶或三阶字节数组,二阶数组包含宽度和高度两个维度,三阶数组有 3 个维度,包括宽度、高度和多个通道。
所以灰阶图是二阶的,而 RGB 图(彩色图片)是三阶的(包含 3 个通道)。
那么对应的卷积核就要设计成一个三维矩阵, 这也是和上面灰阶图作卷积不同的地方。

2.3 卷积和全连接对比
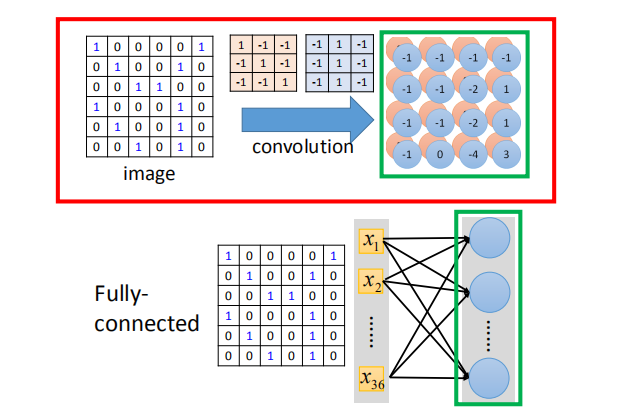
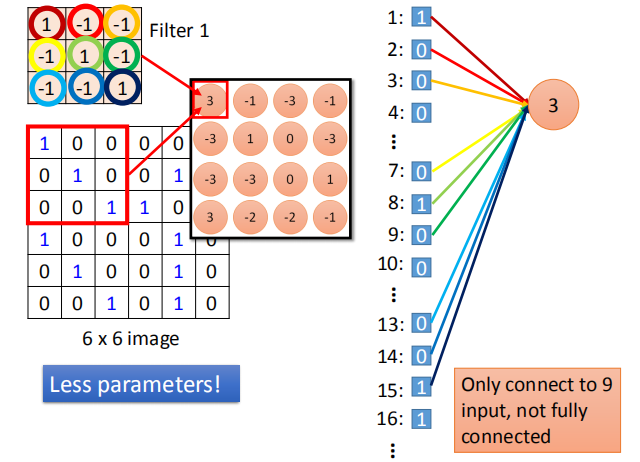
更少的参数:过滤器中的每个参数,仅仅连接到9个输入,而不是全连接。
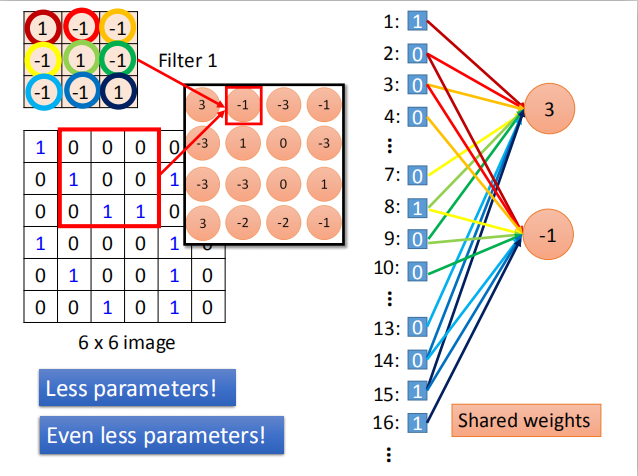
权值共享:每次卷积操作使用相同的卷积核,实现了权值共享。
2.2 最大池化
取每个池化区域的最大值:
 最终得到一个 2X2 的结果:
最终得到一个 2X2 的结果:
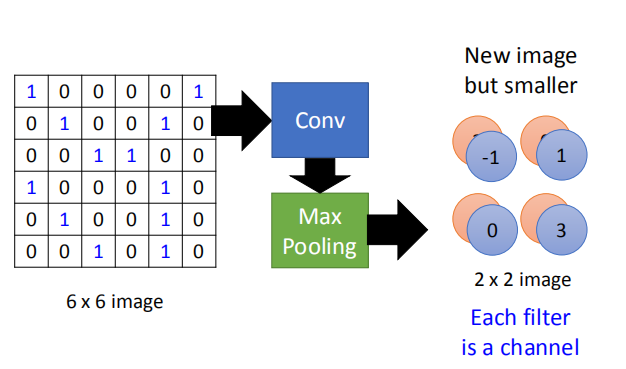 得到的新的图片更小,每一个过滤器代表一个通道。
得到的新的图片更小,每一个过滤器代表一个通道。
经过卷积和池化操作之后得到的图片比原图片更小;通道的数量和卷积核的数量相同。
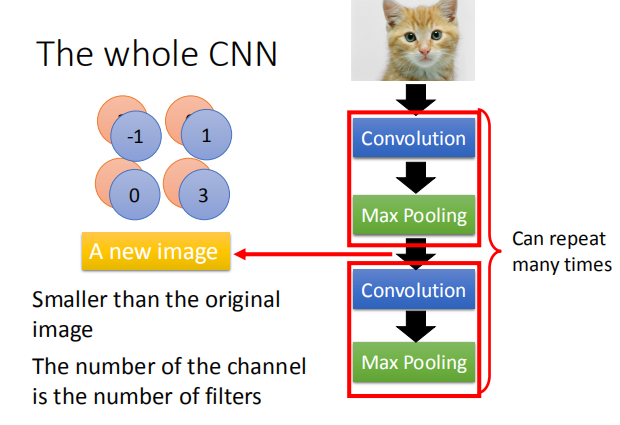
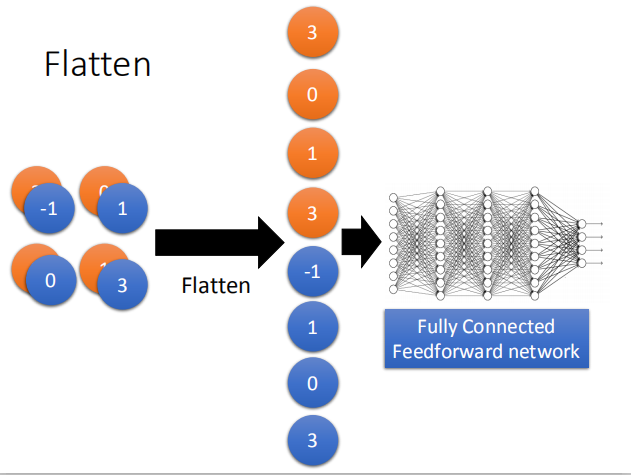
2.3 Flatten
经过一些列的卷积和池化操作之后,我们需要将得到的图片平展开来,经过最后一层的全连接层达到最终的输出结果。
3. 在 Keras 中实现 CNN
在 Keras 中,我们只需要修改网络的结构和输入的形式。
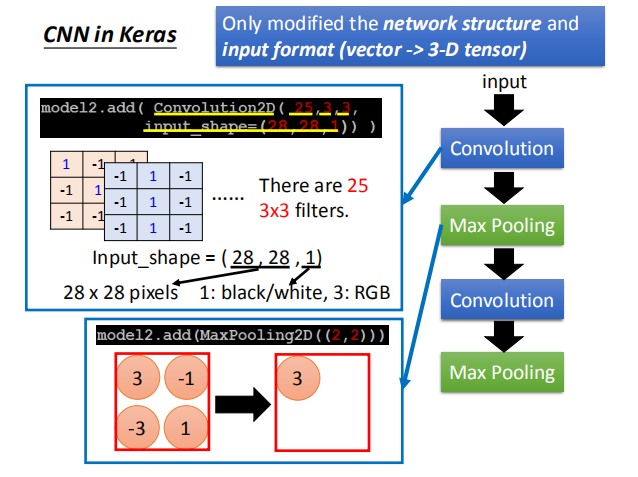 如图,我们有25个 3X3 的过滤器,输入的 shape 为(28,28,1):
如图,我们有25个 3X3 的过滤器,输入的 shape 为(28,28,1):
当为黑白图像时,最后一位为1;当为彩色图片时,最后一位为3。
左下角使用最大池化操作,池化的结果为一个单独的像素值3。
每一个卷积层中,每个滤波器所包含的参数的多少:
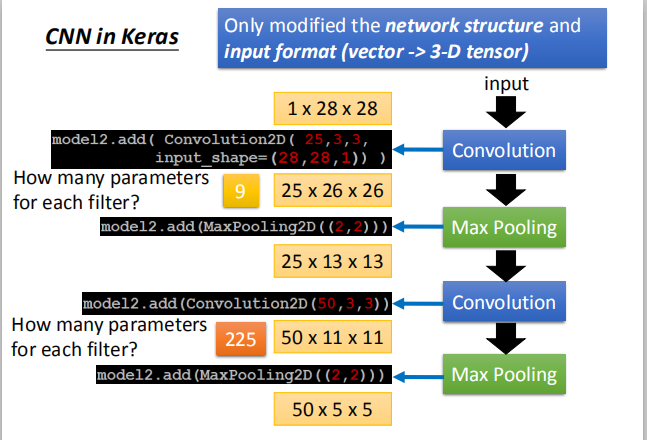 第一个卷积层为单通道,每一个通道的卷积核的大小为 3X3,每个过滤器包含的参数的个数为9。
第一个卷积层为单通道,每一个通道的卷积核的大小为 3X3,每个过滤器包含的参数的个数为9。
第二个卷积层有25个通道,每一个通道的卷积核的大小为 3X3,每个过滤器包含的参数的个数为225。
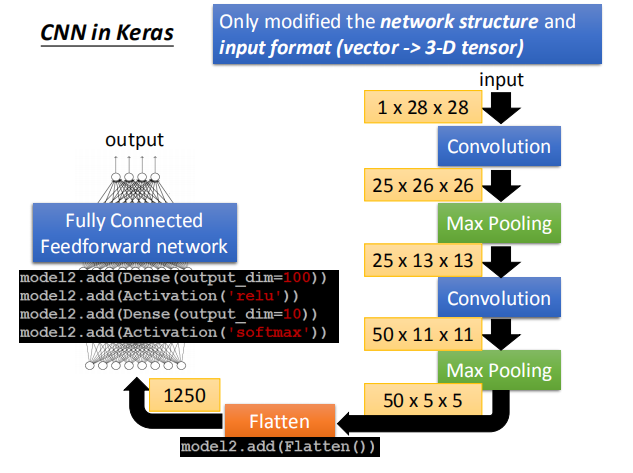
全连接层:
经过卷积和池化操作之后,将特征图像平铺,并添加两个全连接层,得到最终的输出结果。
4. CNN 实际在做什么
实际上,机器可能不会识别这是一双鞋子,而是一头美洲狮。

4.1 第一个卷积层
AlexNet 网络中第一个卷积层的过滤器的可视化结果:

4.2 更高的卷积层
- 哪张图片会使一个特定的神经元活跃

取出一个特定的神经元和相应的过滤器,将图片经过CNN网络的训练从该过滤器输出;
观察输出的结果,可以判断该神经元究竟在干什么。
第k个滤波器的输出是 11X11 矩阵,第k个滤波器的活跃程度:
$a^k=\sum_{i=1}^{11} \sum_{j=1}^{11} a^{k}_{ij} $
$x^* = arg$ $ \smash{\displaystyle\max_{x}}a^k$ (gradient descent) $\frac{\partial a^k}{\partial x_{ij}}$,我们通过梯度下降的方法找到使 $a^k$ 最大的 $x$。 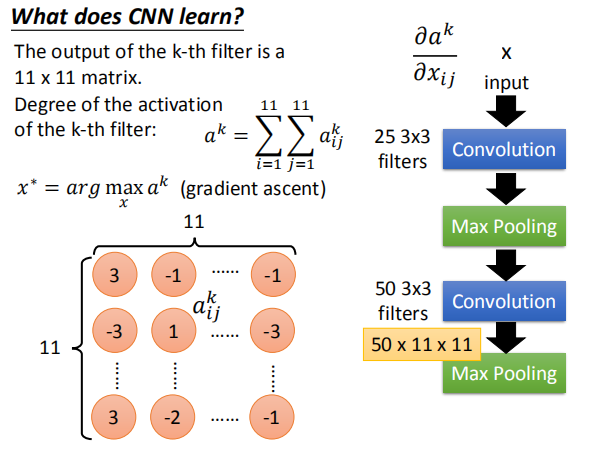 如图,是对第二个卷积层的前12个卷积核求出的使 $a^k$ 最大对应的 $x$ 图像。 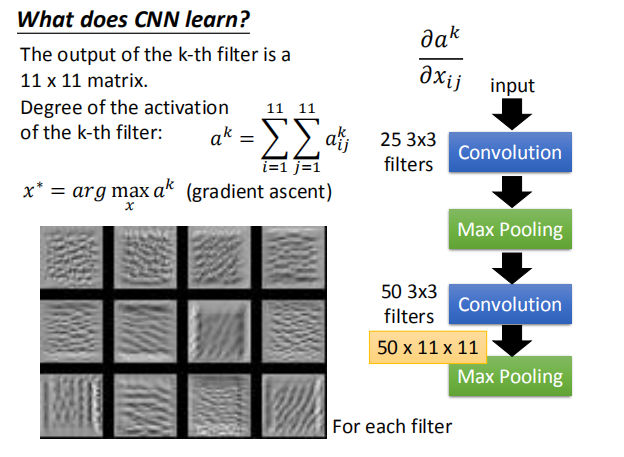 #### 4.3 全连接层 对于全连接层,我们可以使用与卷积层相同的方法,找到哪一张图片使该神经元的激活程度最大。 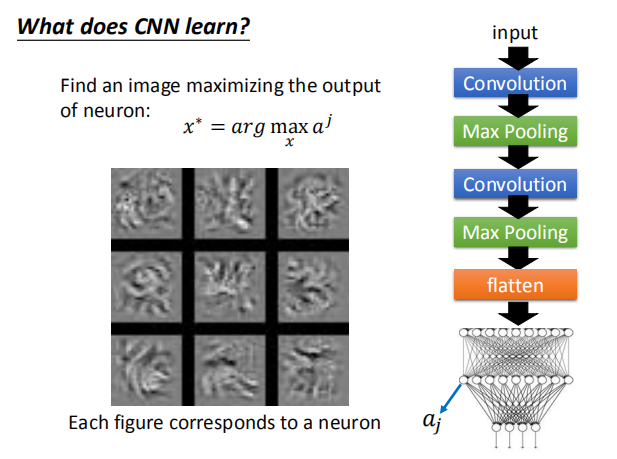 上图展示了前九个神经元对应的结果。 #### 4.4 最后一层 类似上述处理得到的 $x$。 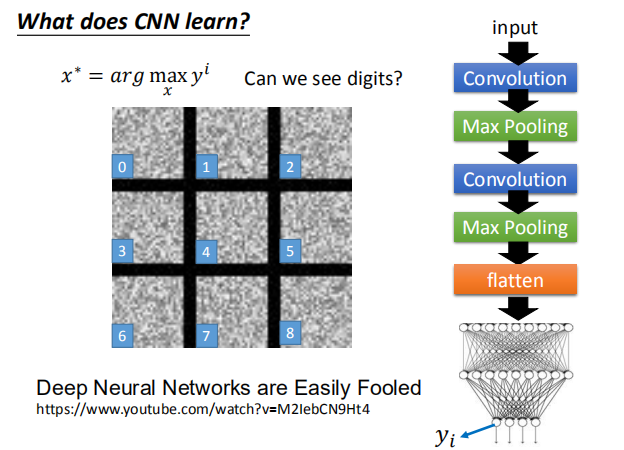 图片可视化结果的改良:  彩色图片得到的结果:  判断某些像素点对分类影响的大小: 通过微分的大小判断某些像素点的影响大小: 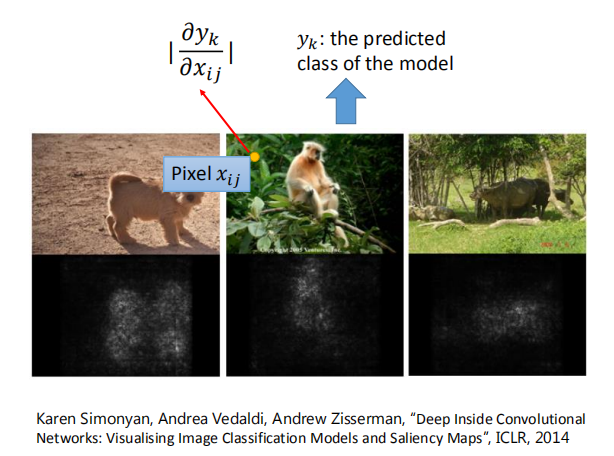 通过将某一部分遮住,判断该区域对最终分类的影响:  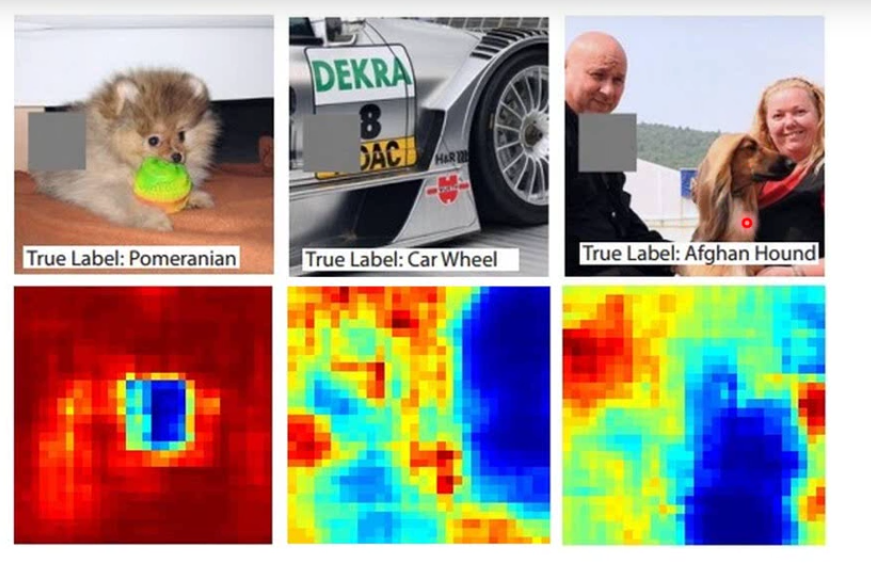### 5. CNN 的应用 #### 5.1 Deep Dream  将得到的结果夸张化:  参考网址:http://deepdreamgenerator.com/ #### 5.2 Deep Style 风格迁移:  结果:  参考网址:https://dreamscopeapp.com/ 原理: 将左右两张图片分别卷积得到他们的内容和风格,在找出一张图片,使其内容与左边的相似,风格与右边的相似。 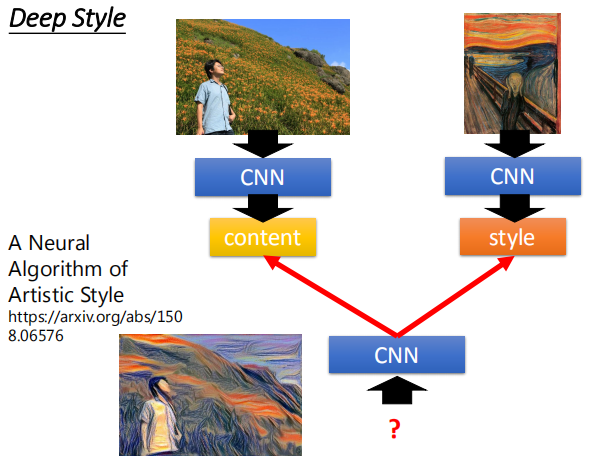 #### 5.3 CNN 网络更多应用 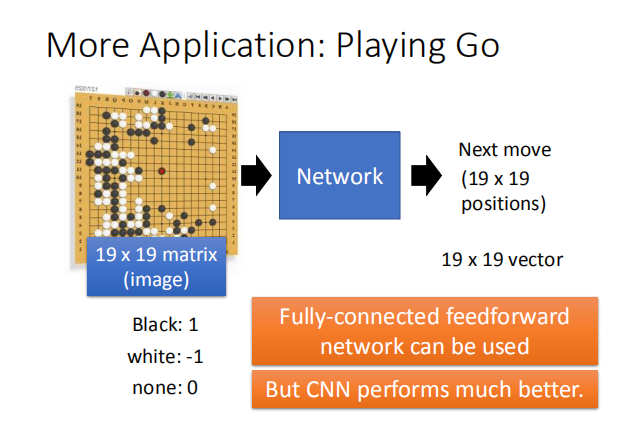 使用 CNN 网络能将棋盘当做图片来处理,而不是一个 19X19 的向量。 训练过程就是输入以前下过的棋谱,得到下一步的落子位置。 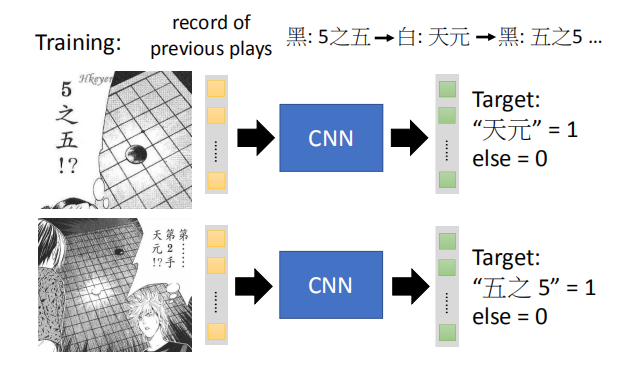 使用 CNN 的原因: + 有些图案比整个图像小得多 + 相同的图案出现在不同的地区 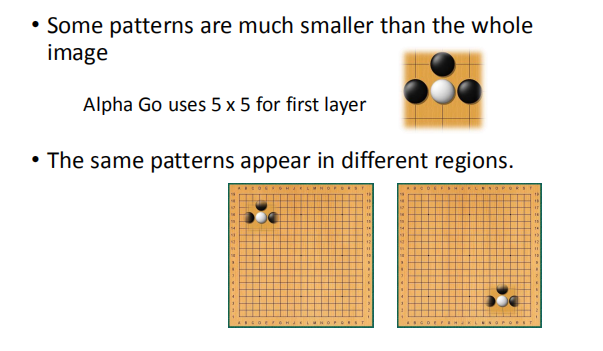 下围棋也有相似的特点。 + 对像素进行二次采样不会更改对象 在图像识别中具有这样的特点,需要进行池化操作,那么在下围棋时也有同样的特点吗?  在语音处理上应用: 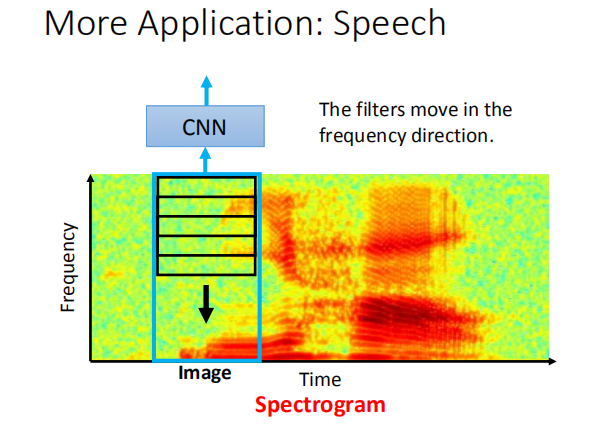 滤波器在声谱频率方向上移动。