这一节我们主要学习
- 介绍迁移学习
- 迁移学习的分类
- 模型微调(Model Fine-tuning)
- 多任务学习(Multitask Learning)
- 领域对抗训练(Domain-adversarial training)
- 零样本学习(Zero-shot Learning)
1.介绍迁移学习
- 迁移学习是一种利用已有的解决某种问题的模型(知识)来解决其他不同但是相关问题的方法。

迁移学习要解决的问题是:假设我们现在手上有与任务不直接相关的数据,这些数据能否帮助我们完成任务呢?
例如,我们现在要做猫和狗的分类器,现在我们手上有一堆和猫狗不是直接相关的数据:
- 大量的在自然界拍摄的老虎和大象的图片;
- 大量的猫和狗的卡通图片。
这些数据都和现实世界中的猫狗图片有一定的关联性,但同时也有较大的差别。
我们需要将利用这些数据训练得到的模型运用到猫狗分类的问题上,这就是迁移学习。

当我们只拥有少量的符合任务要求的目标数据,但类似的源数据却很多的时候,
我们可以考虑使用迁移学习,比如以下情况。
| 目标领域 | 目标任务 | 不相关的数据 |
|---|---|---|
| 语音识别 | 对台湾语做识别 | 从 youtube 上爬取英文、中文语音数据训练模型来迁移学习 |
| 图像分类 | 医疗数据极度缺乏,做医疗诊断时 | 使用已有的海量图像数据( coco , imagenet 等) |
| 文本分析 | 特定领域,比如法律文件分析 | 可以从其他领域的文本分析迁移 |
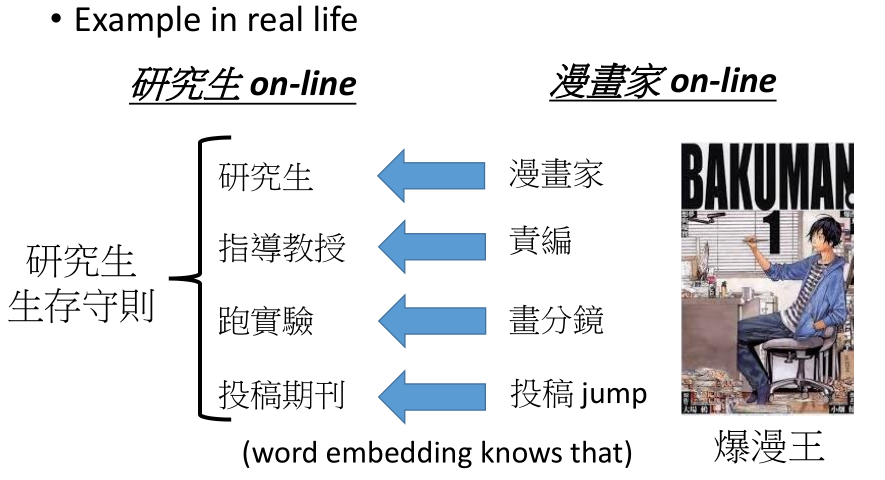
2.迁移学习的分类
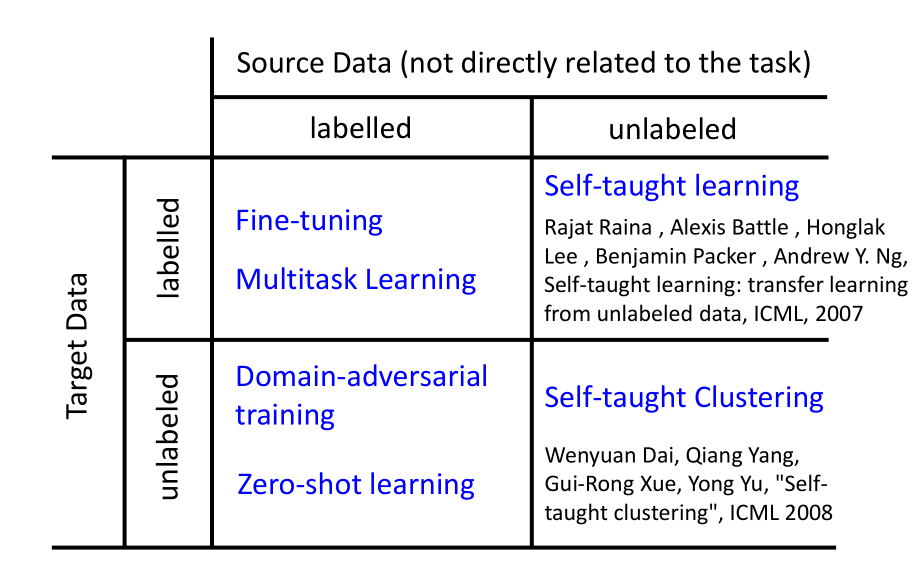
迁移学习中: 目标数据有有标签和无标签两种情况;源数据也有有标签和无标签两种情况。
所以一共有如上图所示的四种情况,分别对应不同的迁移学习的方法:
- Target Data: labelled,Source Data: labelled——Model Fine-tuning,Multitask Learning.
- Target Data: labelled,Source Data: unlabelled——Self-taught learning.
- Target Data: unlabelled, Source Data: labelled——Domain-adversarial training, Zero-shot learning.
- Target Data: unlabelled, Source Data: unlabelled——Self-taught Clustering.
3.模型微调(Model Fine-tuning)

当我们的特定任务所拥有的数据集非常少,但是非相关的数据集很多时,这种问题我们称之为一次性学习(one-shot learning)。
例如,当我们要对某个人的语音进行语音辨识的时候,那个人的语音音数据特别少。但是我们有很多来自其他人的语音数据。
这时,我们需要使用迁移学习的方法:用许多人的语音数据训练模型,然后再用特定人选的语音数据对模型进行微调。
处理该类问题的时候需要注意的地方:由于目标数据很少,在用目标数据进行训练的时候要防止过拟合。
3.1 迁移学习技巧:保守训练
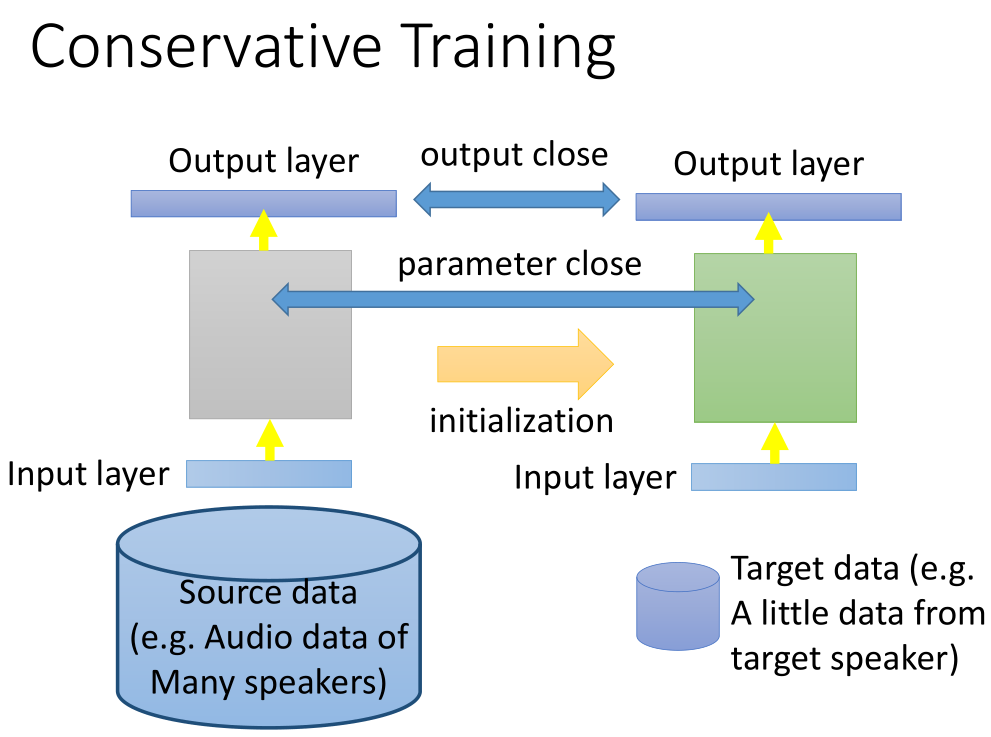
假设,我们已经有大量的源语音数据以及少量的目标数据集,我们先使用源数据训练出一个模型,
然后在原模型的基础之上,我们再使用目标数据对模型进行训练,得到的新模型可能发生过拟合而产生较大偏差。
因此,我们需要在训练新模型的时候,需要给模型添加一些限制,使得训练完成之后,前后两次模型不要差太多。
例如,当输入相同时,我们希望前后两个模型的输出不要相差太多。
在训练新的模型的时候,我们可以将旧模型的参数作为正则项加进去,使得新模型的参数与旧模型参数不会相差太大。
3.2 迁移学习技巧:层转移
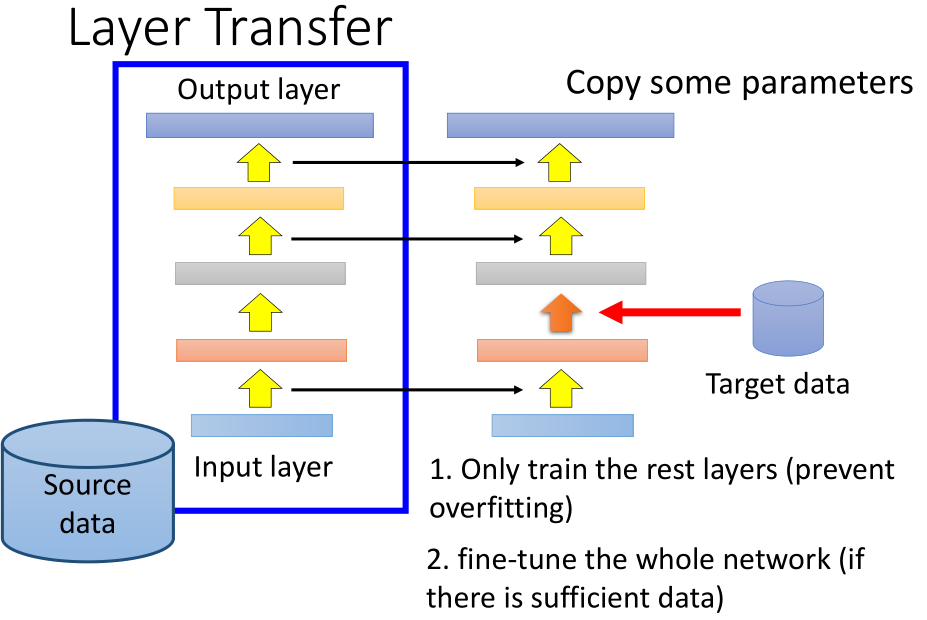
我们在训练新模型的时候可以对参数做一些限制,只需要调整某一些网络层的参数。
当我们使用源数据训练好一个模型的时候,
如果我们只有少量的目标数据,我们可以将原模型中的某些层的参数直接复制到新的网络中,我们只需要训练余下层的参数;
如果目标数据较多,我们也可以在原模型的基础之上调整整个网络的参数得到新的模型。
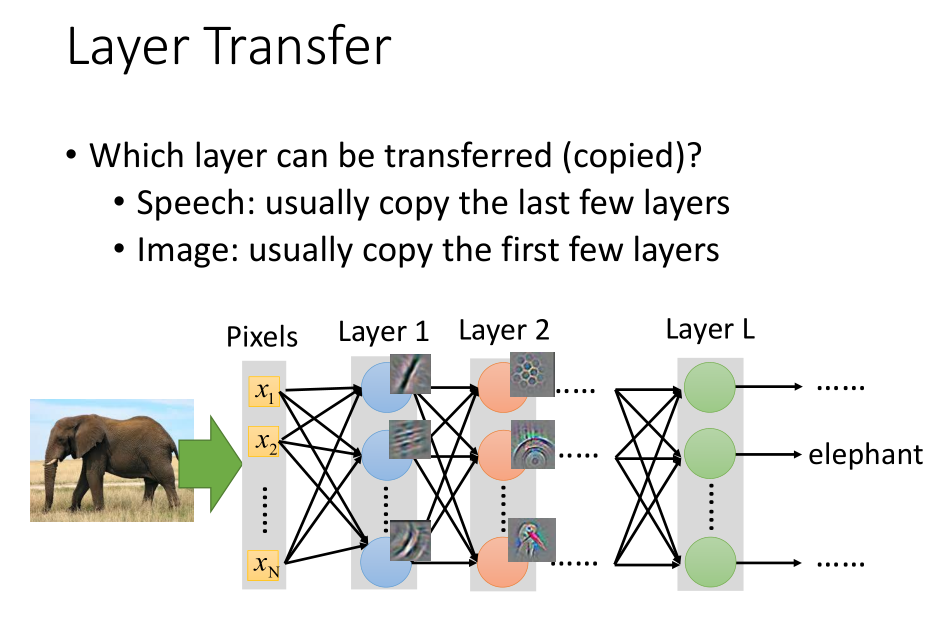
在不同的任务之中,需要转移的网络层不同。
- 语音识别中,通常只复制最后几层网络,然后重新训练输入层网络。
语音识别的结果,应该跟发音者没有关系的,所以最后几层是可以被复制的。
而不同的地方在于,从声音信号到发音方式,每个人都不一样。
- 在图像任务中。通常只复制前面几层,而训练最后几层。
通常前几层做的就是检测图像中有没有简单的几层图形,
而这些是可以迁移到其他任务中。
而通常最后几层通常是比较特异化的,这些是需要训练的。
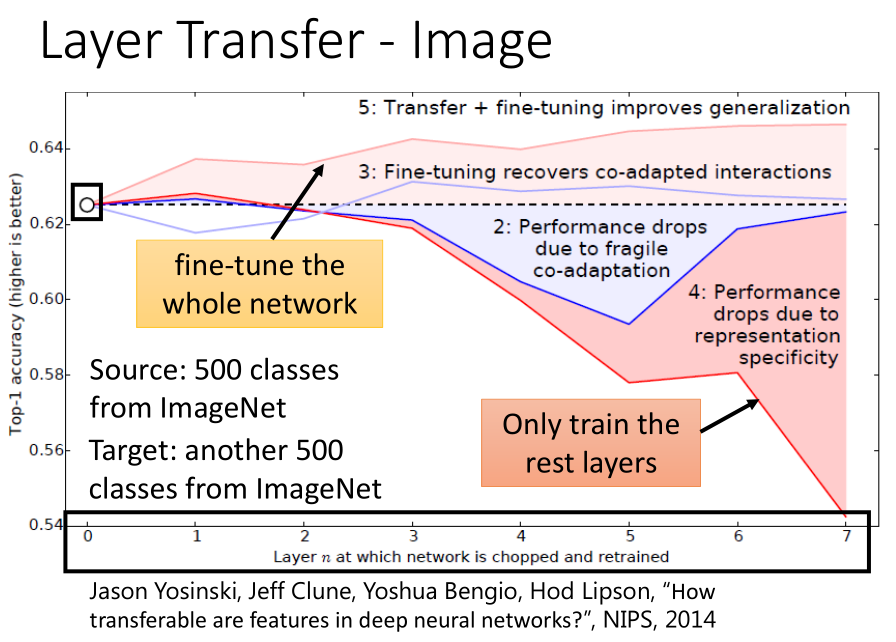
- 网络层迁移学习的实验结果(图像任务)
Image在 Layer Transfer 上的实验,出自 Bengio 在 NIPS2014 的论文。
ImageNet的数据120万图像分为 source 和 target ,
按照分类数量划分,其中500个分类作为 source ,另外500个为 target。
co-adaptation:相互适应
feature representation:特征表示
-
横坐标表明网络从第n层开始重新训练;纵坐标表明 Top-1 准确率;结果表明:
-
可以发现,当我们只复制前面几个网络层时,效果有提升,但是复制得太多效果就开始变差。
-
曲线5表明,Layer Transfer + Fine-tuning 在所有情况下,accuracy均有提高。
这一结果的惊人之处在于,这里的target data已经非常多(ImageNet的一半),
但是再加上Source data(ImageNet的另一半)仍然有所帮助。 -
曲线2表示,如果用target domain训练出一个模型,固定住前几个layer,
再用target domain训练后几个layer,结果可能坏掉。 -
曲线3表明,在曲线2基础上fine-tune,结果会恢复。
-
综上:前面几层都学习到的是通用的特征(general feature),随着网络的加深,后面的网络更偏重于学习特定的特征(specific feature)
-
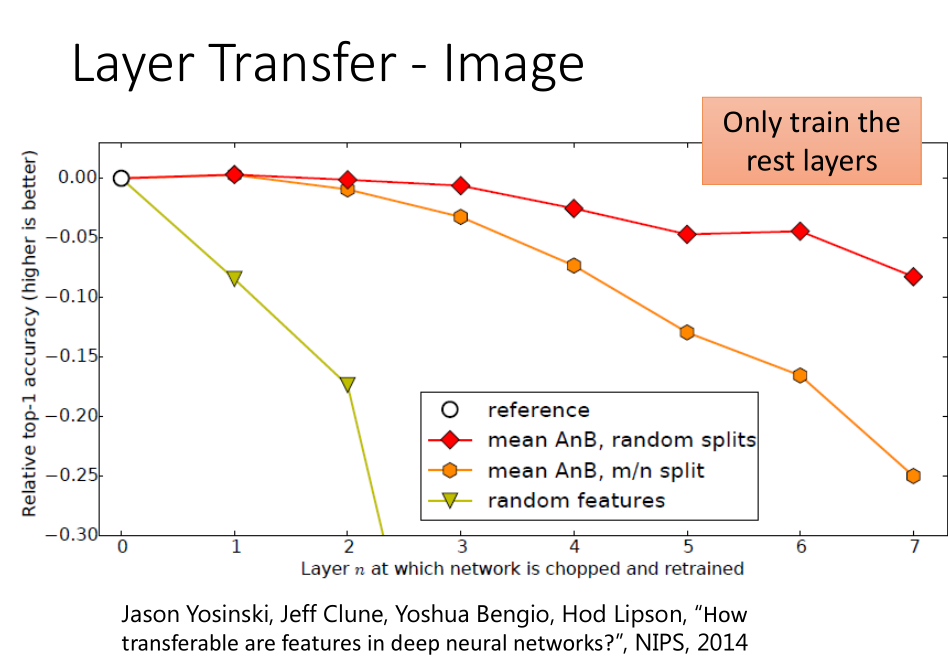
随着可迁移层数的增加,模型性能下降。但是,前3层仍然还是可以迁移的!同时,与随机初始化所有权重比较,迁移学习的精度是很高的!
4.多任务学习(Multitask Learning)
- 多任务学习:当我们有多个任务需要完成时,我们希望能够同时训练多个任务而得到较好的结果。
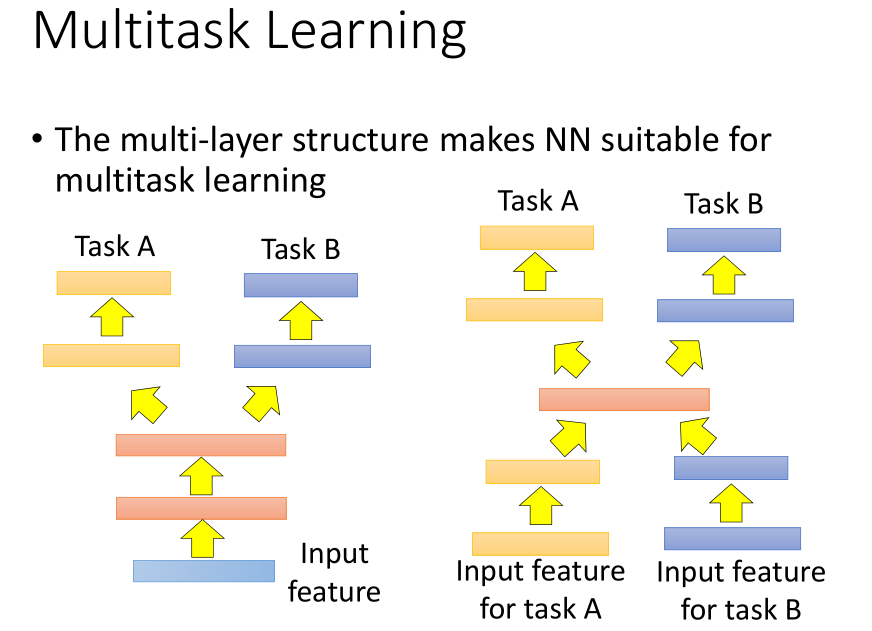
- 当两个任务可以共用同一组特征,我们就可以采用左边的网络结构,让两个任务共用前面几个网络层,
在某一个网络层产生分支,一个分支用于解决任务 A,另一个分支用于解决任务 B。 - 当两个任务不能共用特征的时候,我们就可以采用右边的网络结构,对两组特征做一些特征转换,
然后再输入到同一个网络结构中训练,最后再产生分支分别用于解决任务 A 和任务 B。
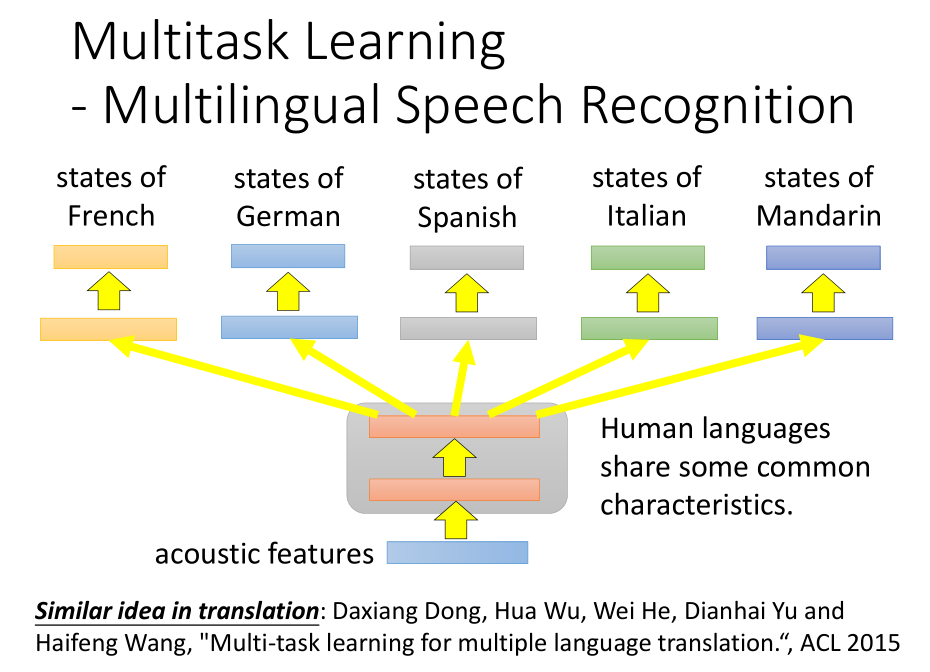
- 多种语言的语音识别的例子:
不论何种语言,它们的声音信号都是一样的,所以可以使用相同的网络层结构对声音信号进行特征提取;
当到达某一个特定的隐藏层的时候,网络结构开始产生分支处理不同的任务,然后同时进行训练。
最后得到的多种语言语音识别的效果比某种单一语言语音识别的效果更好。
 如图,横坐标表示训练样本的数量,纵坐标表示错误率
如图,横坐标表示训练样本的数量,纵坐标表示错误率
- 蓝色曲线表示做单一中文语音识别时中文语音识别的错误率。
- 红色曲线表示将中文同其他欧洲语言一起做语音识别时中文语音识别的错误率。
- 对比两曲线我们可以发现,将中文和其他欧洲语言放在一起进行语音识别训练的训练效果比单一训练中文时的训练效果更好。
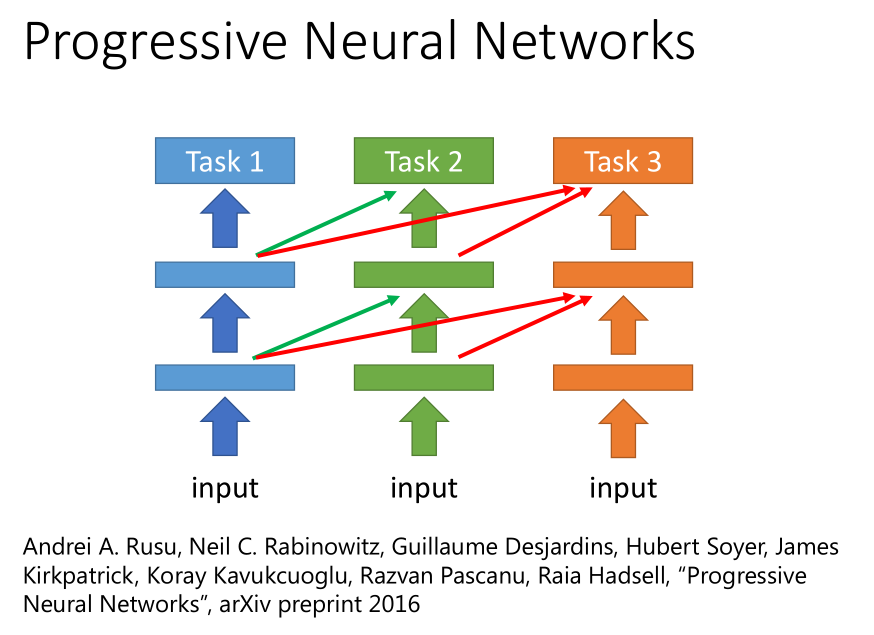
先训练一个解决任务 1 的网络模型 1,训练完成之后,固定该模型的参数;再去训练一个任务 2 的网络模型 2,它的每个隐藏层都会去接收模型 1 的隐藏层输出。
它的好处是,即便任务 1 和任务 2 完全不像,任务 2 的数据也不会影响到模型 1 的参数,
所以迁移的结果一定不会更差,最糟糕的情况就是直接训练任务 2 的模型(此时网络模型 1 的输出设置为 0)。
5.领域对抗训练(Domain-adversarial training)
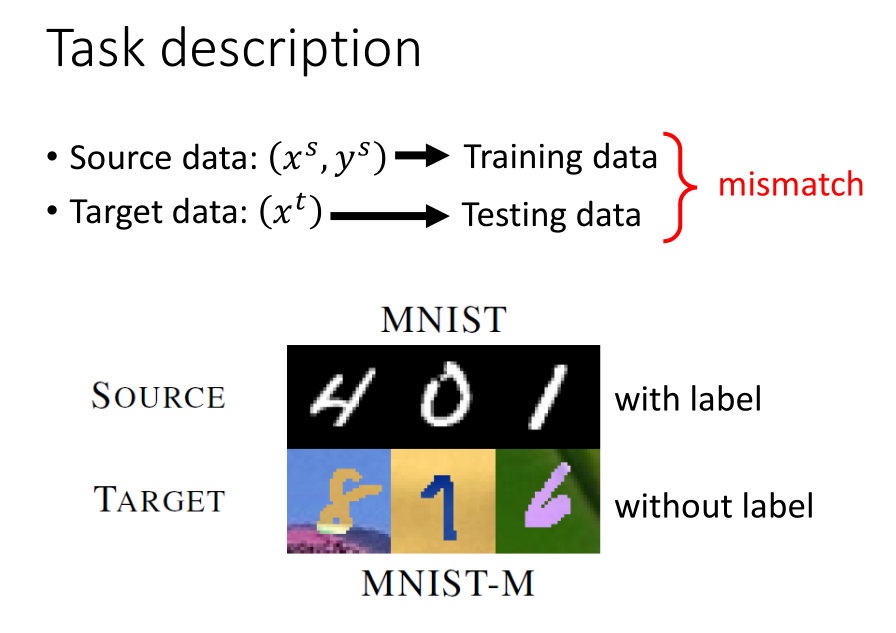
当源数据集有标签、目标数据集无标签的时候,我们应该如何处理该问题呢?
其中一种做法是,将源数据视作训练集数据,将目标数据当做测试集数据来进行预测。
这种做法的问题在于源数据集和目标数据集的分布可能完全不同,出现不匹配的情况。
此时,我们需要采用领域对抗训练的方法。
- 领域对抗可以看做是 GAN 模型的一种,目的是把源数据和目标数据的特征转换到同一个领域中,
使得源数据和目标数据服从类似的分布。
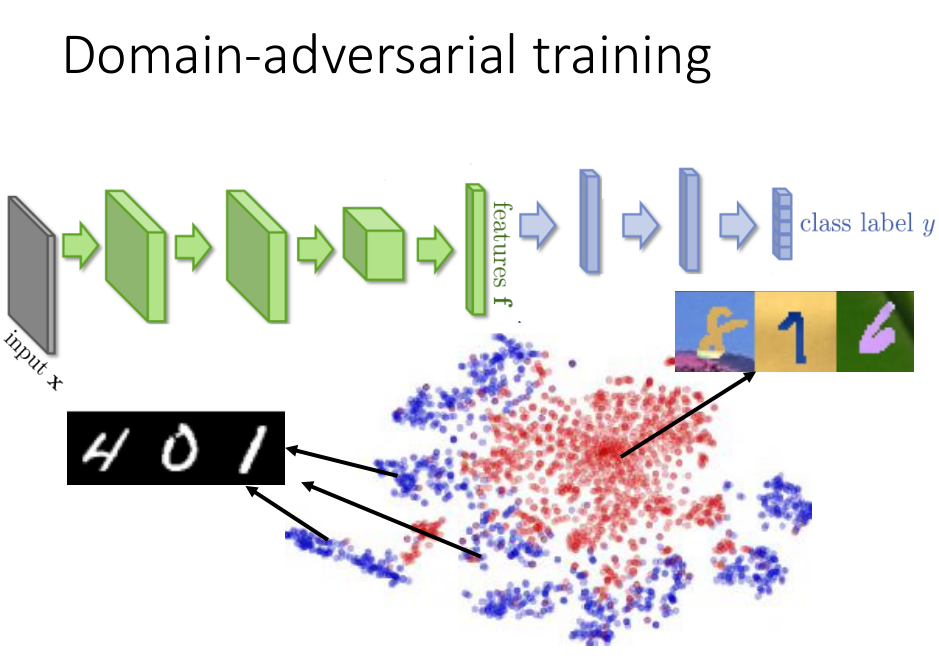
如果我们不靠源数据和目标数据不匹配的问题的,不对数据特征做任何处理,
可能会得到如上图所示的数据分布:蓝色点表示源数据的分布;红色点表示目标数据的分布。
我们可以看出蓝色点的分布是一个一个的集群,但是红色的数据点堆积在一起,源数据和目标数据的特征分布完全不一样。
若我们无法将源数据和特征数据的分布转换到同一领域上的相同分布,我们就不能使用分类器将目标数据很好的分类。
- 我们使用特征提取器来消除源数据集和目标数据集的领域特性,让它们数据的特征服从同一分布。
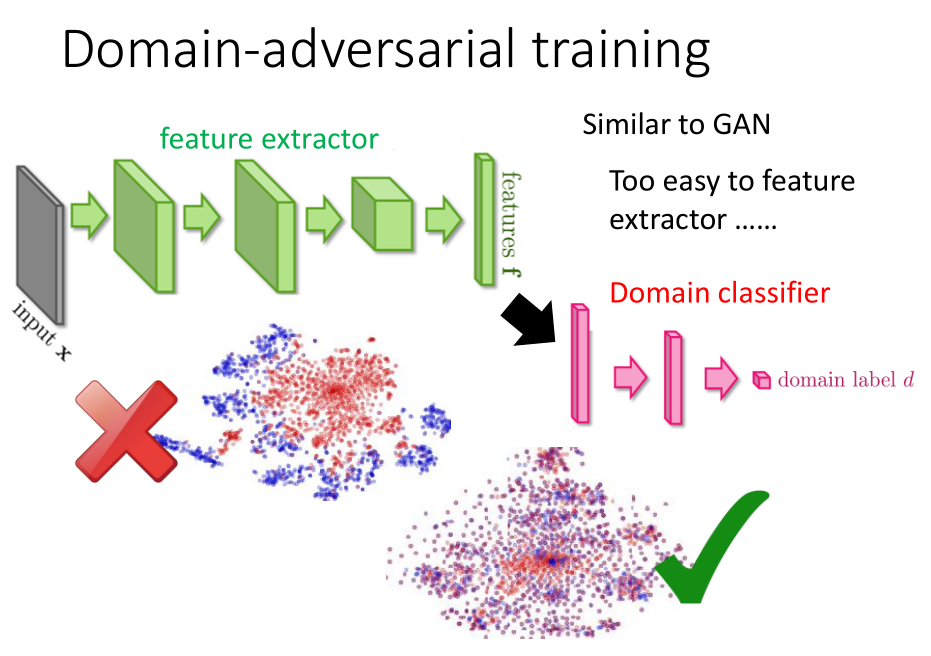
-
具体做法:
我们需要在特征提取器后面增加一个领域分类器。
特征提取器的目标是:由它提取出来的数据特征能够让领域分类器无法分辨该数据来自哪个领域,
从而消除源数据集和目标数据集的领域特性,使这些数据特征服从同一分布。 -
存在的问题:
仅仅增加一个领域分类器并不能达到预期的效果,只要特征提取器每次输出一个特定的值,就可以骗过领域分类器。
因此,我们需要给特征提取器增加另外一个限制。 -
特征提取器除了要消除数据特征的领域特性之外,还需要提高标签预测的准确率。
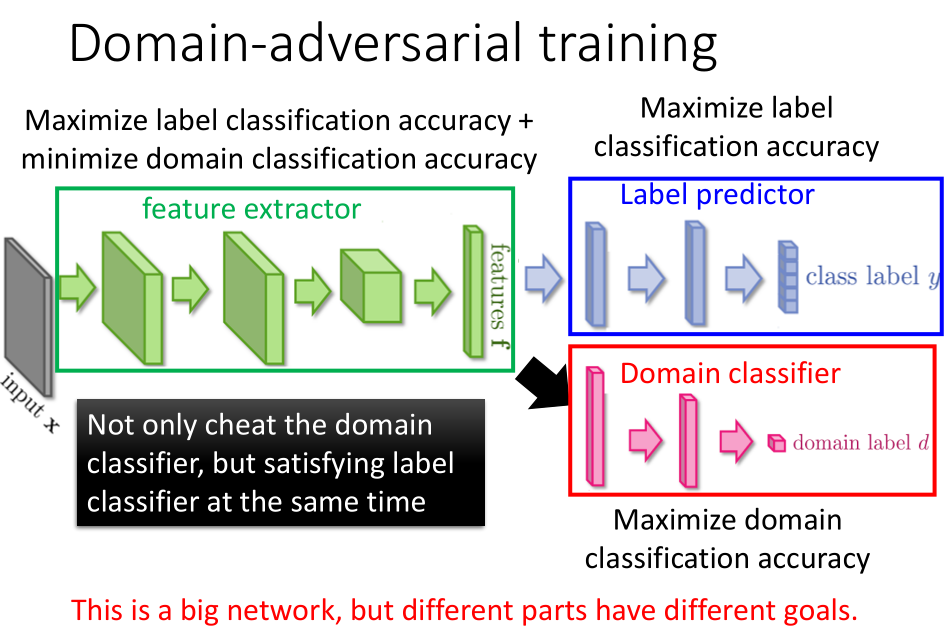
整个网络结构如上图所示,领域分类器想要判断数据特征来自哪个领域,标签预测器想要尽可能准确地预测出数据的标签,
而特征提取器希望提取出来的数据特征尽可能满足标签预测器的要求,而使领域分类器失效。
那么具体应该怎么做来达到上面的要求呢?
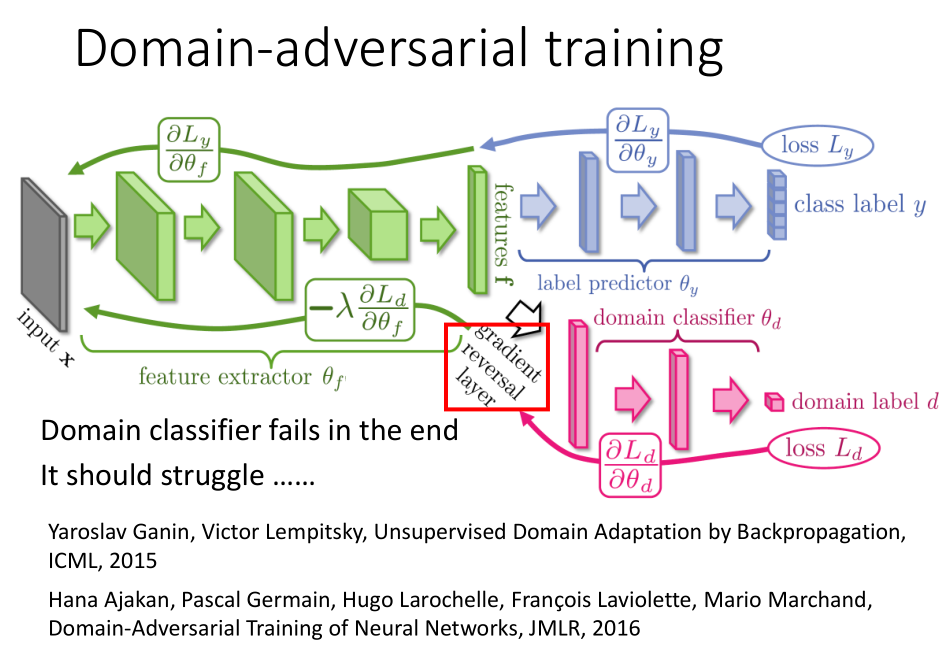
领域分类器和标签预测器都会使用梯度下降的方法使自己的损失函数最小,
但关键点在于特征提取器会尽量满足标签预测器的要求而反对领域分类器的做法。
因此,当反向传播的梯度经过特征提取器的时候,标签预测器的梯度会保持原来的方向,而领域分类器的梯度方向会朝着相反的方向向后传递。
由于领域分类器的的输入数据是由特征分类器来提取输出的数据特征,所以最终的结果会是领域分类器无法判断数据特征来自哪一个领域。
因此,上述的网络模型能够很好的消除源数据和目标数据的领域特性,使它们服从同一分布;
同时满足了标签预测器的要求,能够很好的对数据进行预测分类。
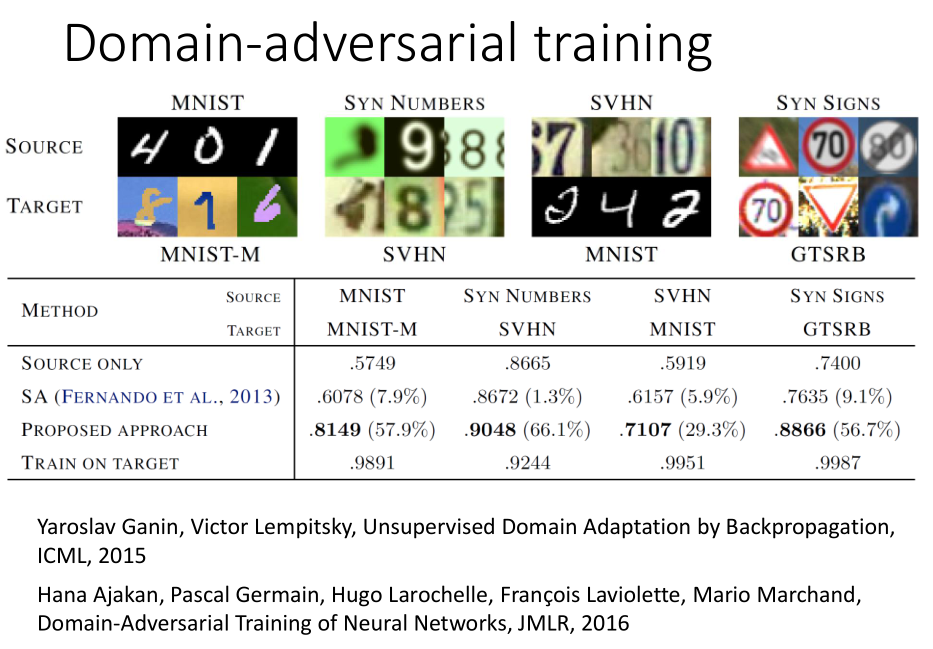
-
实验结果:
第一行(SOURCE ONLY)是将源数据作为训练集数据目标数据作为测试集数据的实验结果,可以看出模型的表现比较差;
最后一行(TRAIN TARGET)是直接使用目标数据来训练的实验结果,效果较好;
第三行(PROPOSED APPROACH)是使用领域对抗训练的实验结果,效果介于两者之间。 -
结论:
当源数据和目标数据不匹配但需要完成的任务相同的时候,使用领域对抗训练的方法可以让模型的表现更好。
6. 零样本学习(Zero-shot Learning)
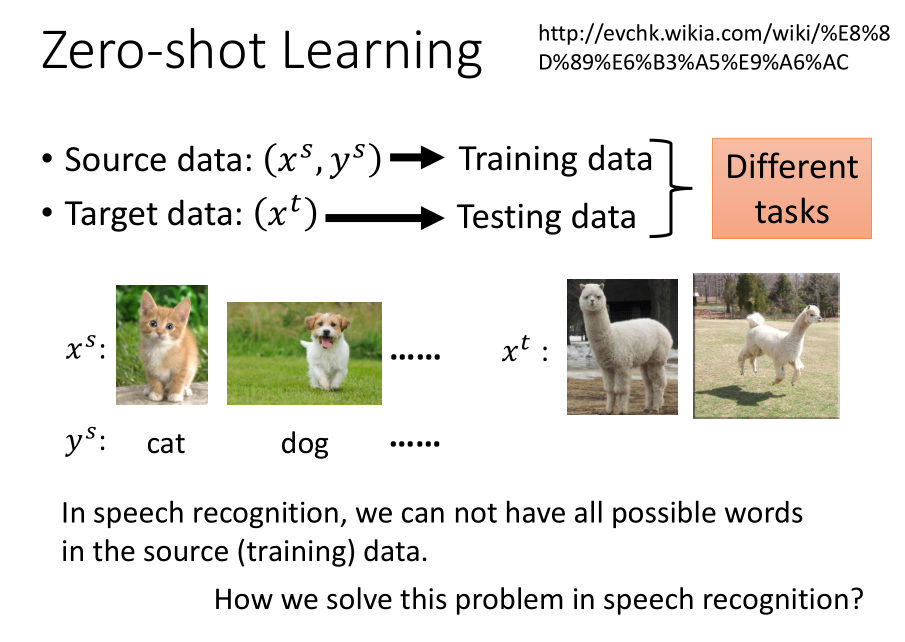
当源数据集(有标签)和目标数据集(无标签)处理的问题不同时,我们需要运用零样本学习的方法来处理问题。
例如,当源数据集都是猫和狗的图片的时候,我们需要识别的目标数据集都是草泥马的图片,我们应该怎么处理?
先看看语音识别的例子:我们在进行语音识别的时候,机器可能遇到从来没有见过的单词,我们如何处理这种情况呢?
实际上,机器识别的不是一个单词的发音,而是识别每个单词的各个音标,再根据音标和词汇的关系库判断出是哪个单词。
在图像问题上,我们把图像的类别用类的属性表示。如上图中的 Database 所示,
当类的属性足够丰富可以代表一个类的时候,我们可以直接通过判断图像拥有哪些属性来判断图片所属的类别。
当我们在识别目标数据集的数据的时候,我们就可以直接通过图片的属性来判断图片的类别。
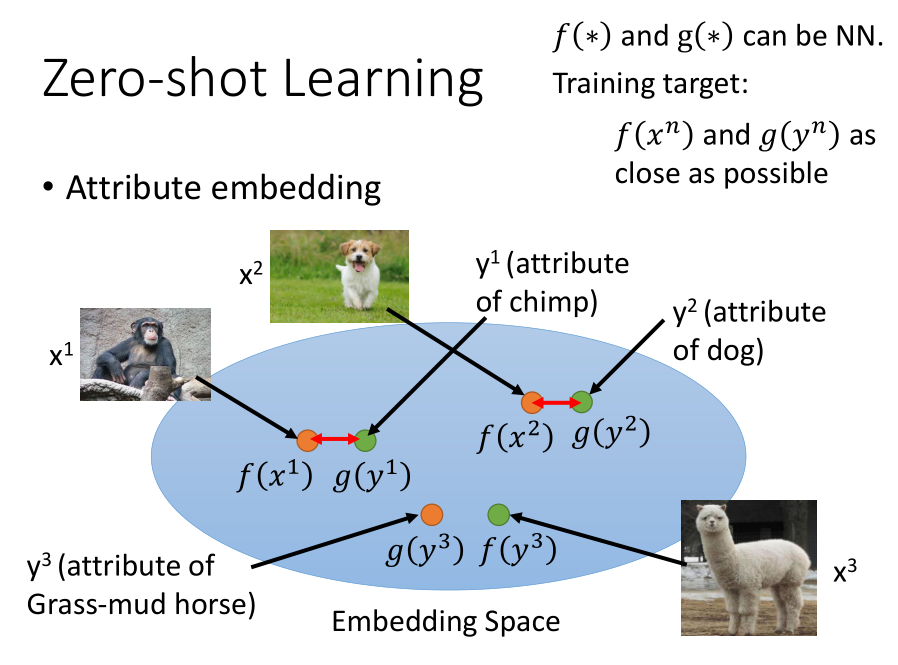
当图像的属性维度较高时,我们可以建立一个属性嵌入空间,将训练集中的每张图片变成嵌入空间中的一个点。
函数 $f$ 和 $g$ 都表示神经网络,它们将图片和属性的特征转换成嵌入空间中的一个点,
如果两个点比较接近的话,说明该图片具有该属性,再根据属性和类的关系判断图片的属性。

首先,我们想到是的使 $f(x)$ 和 $g(x)$ 的空间距离较小,但是仅仅这个约束还不能满足要求;
我们需要添加另外一个约束条件:图片和对应属性的数据特征的内积要比其他不对应的属性的内积要大一个间隔 $K$。
这样我们就可以使图片和对应属性点之间的距离尽可能的小,且对应点与不对应的点之间有一个明显的分界。
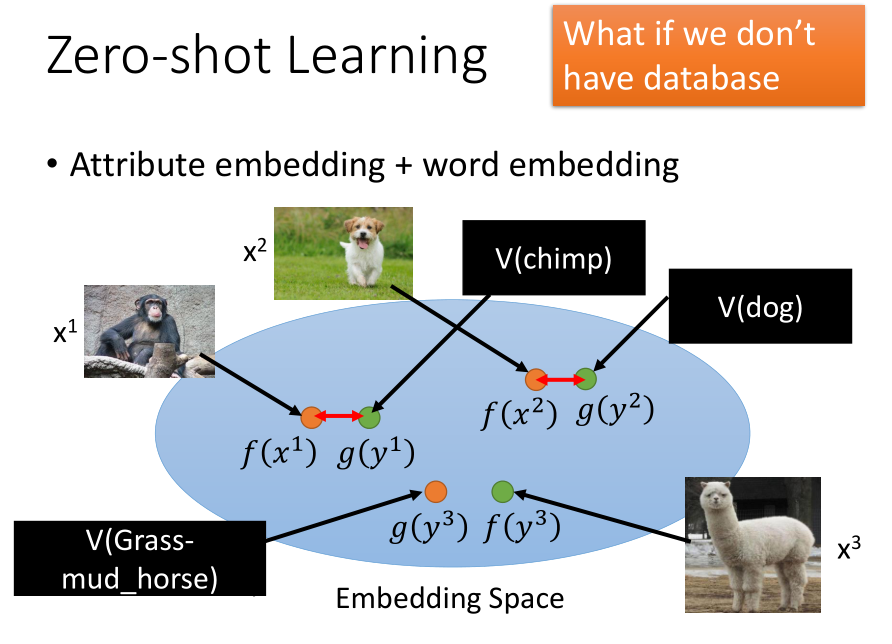
如果我们没有类和属性的关系数据库,我们可以通过单词嵌入,将属性转换成单词向量。
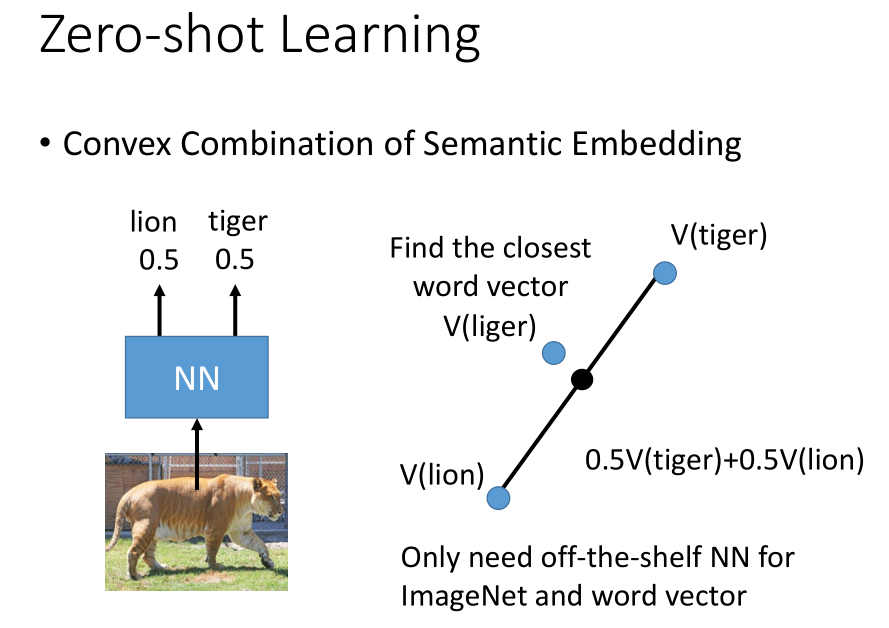
语义嵌入的凸结合是处理零样本学习的一个更简单的方法,它不需要我们来训练模型;
我们可以根据原有的模型的得到一个分类的输出结果,再在单词嵌入空间中找到和输出结果(图中的黑色点)最接近的一个数据点(liger 点)。
论文:https://arxiv.org/pdf/1312.5650v3.pdf
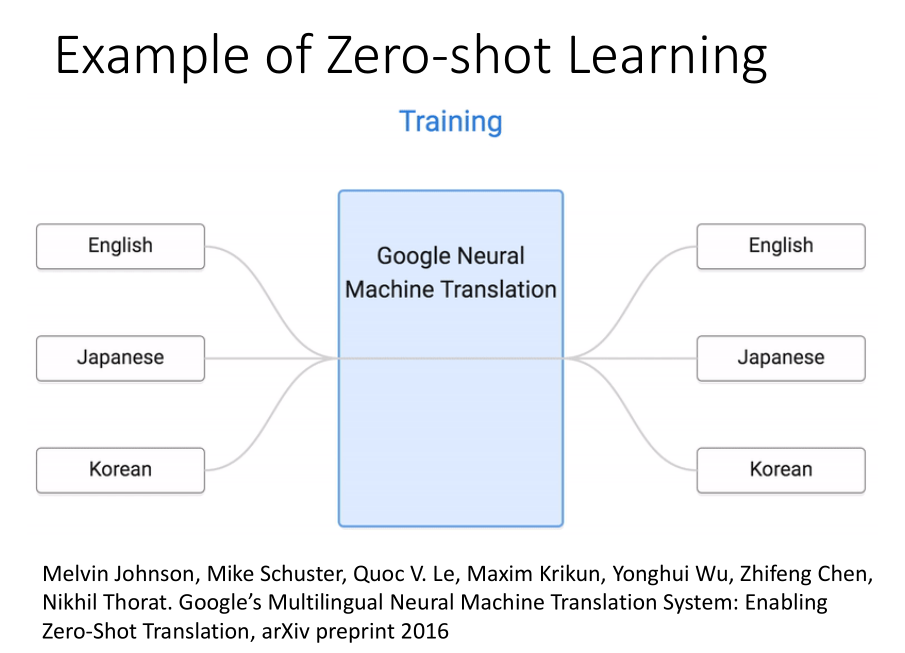
当我们要把日文翻译成韩文的时候,由于我们没有日文到韩文的数据样本,我们需要使用零样本学习的方法来解决这个问题。
由于我们有将英文翻译成韩文、英文翻译成日文的例子,我们可以将英文、日文、韩文都对应到一个属性的样本空间上,
因此,即使没有日文到韩文的数据样本,我们也可以实现日文到韩文的文本翻译。
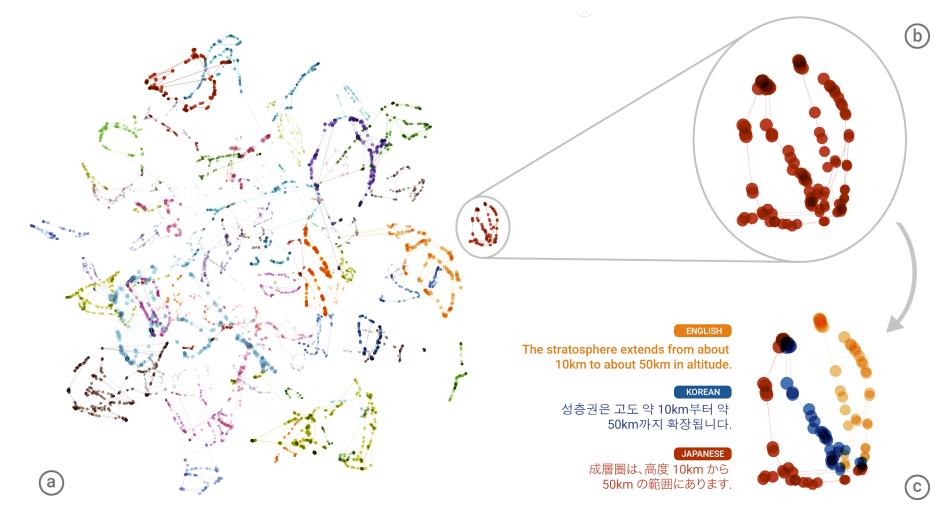
根据学习好的编码器,把各种语言的词汇映射到空间中的向量,会出现上图的结果:
不同颜色代表不同语言,处于相同位置的代表意义相同。
7. 自我学习
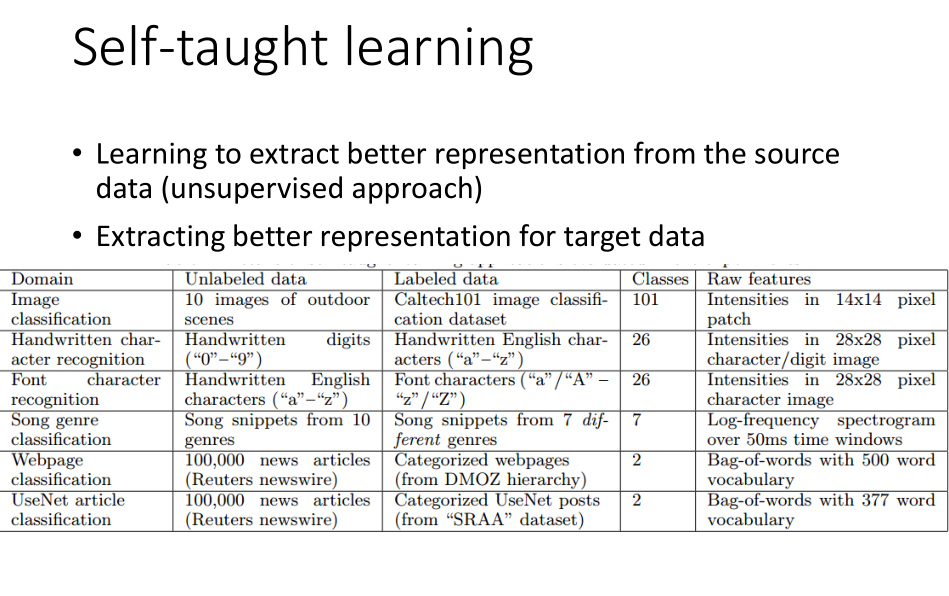
自我学习适用于目标数据带标签而源数据不带标签的情况。
自我学习的做法是,如果现在的源数据足够多的,可以训练得到一个特征提取器,
然后用这个特征提取器在目标数据上提取数据特征。
8. 总结
本章主要介绍了模型微调(Model Fine-tuning)、多任务学习(Multitask Learning)、领域对抗训练(Domain-adversarial training)、零样本学习(Zero-shot learning)、自我学习(Self-taught Learning)等多种迁移学习的方法及其具体的适用情况。