这一节我们主要学习
- 介绍 Auto-encoder
- 深度自动编码
- 深度自动编码实例化
1. 介绍 Auto-encoder
基本上 Auto-encoder 是使用神经网络进行降維。
编码器(Encoder)将输入降维成一段 code ;然后通过解码器(Decoder)进行解码输出。最终目标是让输入和输出相等或十分接近。
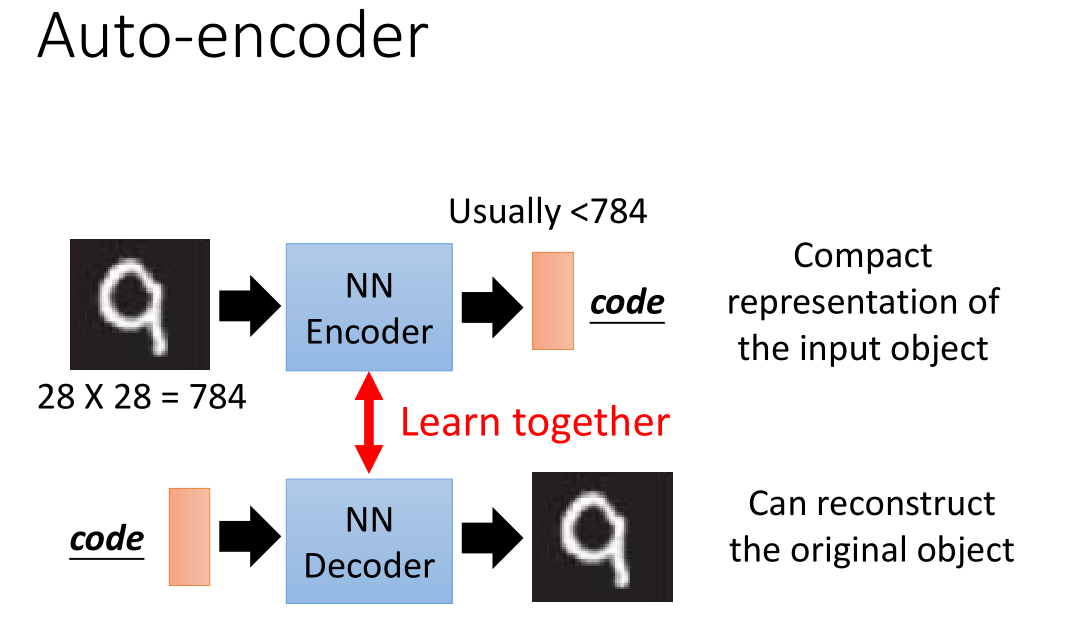
在手写数字识别任务中,想训练一个 NN encoder ,得到图像的精简表达。
但做的是无监督学习,可以找到很多 input image ,但是不知道 code 最终结果无法计算误差,所以没法学习更新编码器(NN Encoder)。
于是又提出一个 NN decoder(也没法单独更新),把两者连接在一起通过比较输入和输出的误差更新编码器和解码器 。
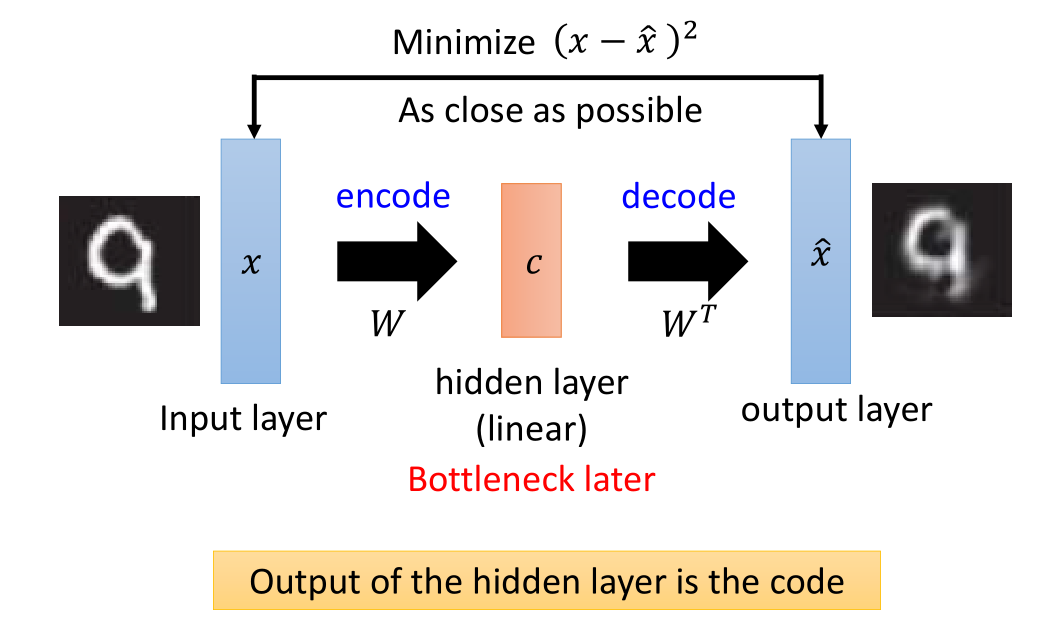
PCA 过程回顾:
首先通过输入的图片,乘以矩阵W,得到降维后的数据,
然后对于降维数据乘以前述矩阵的转置,可以得到预测的输出图片。
2. 深度自动编码
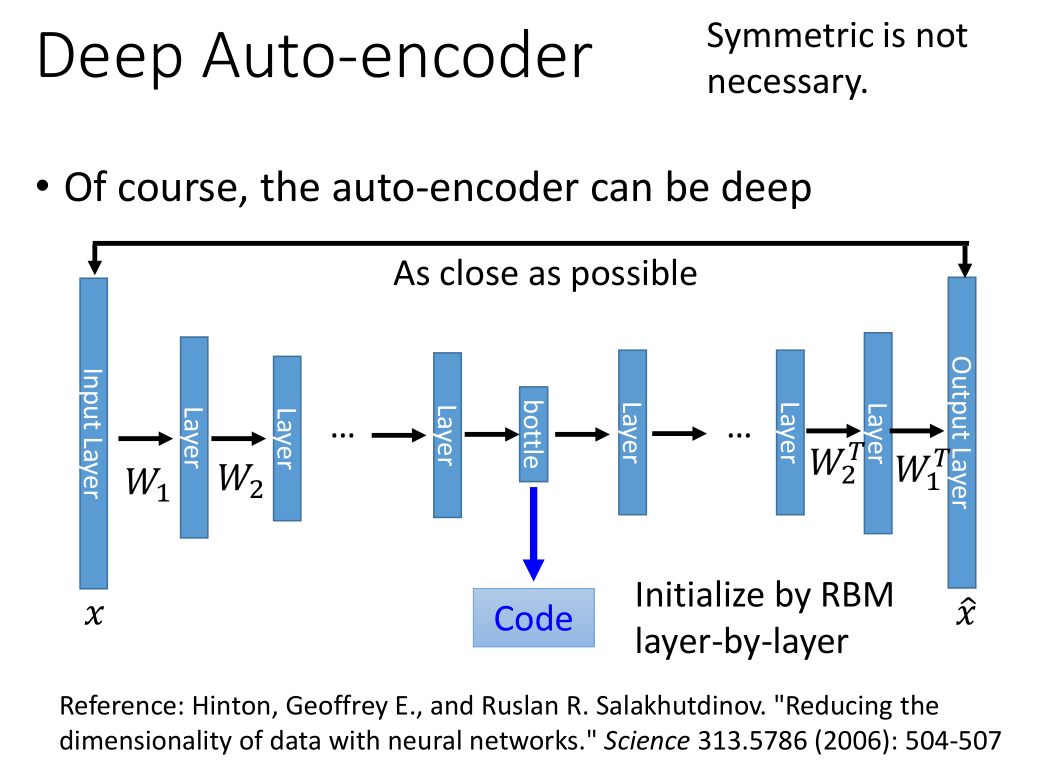
当这个结构变得很深,就变成了deep auto-encoder,encoder 和 decoder 的系数不一定是对称的。
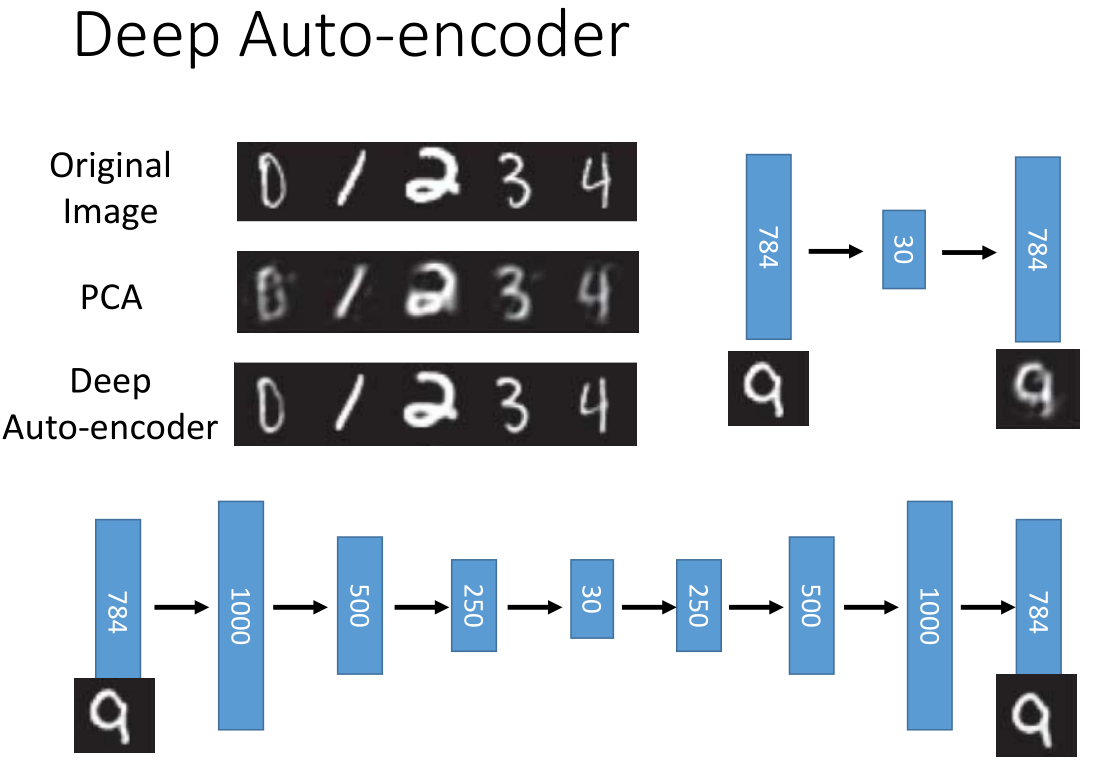
上图上面部分是手写数字采用 PCA 降维:把784维降到30维再恢复到784维
下面是采用 deep auto-encoder 降维:784-1000-500-250-30-250-500-1000-784
PCA&Deep Auto-encoder 比较,明显后者效果更好。
不过以上不是重点,重点如下:
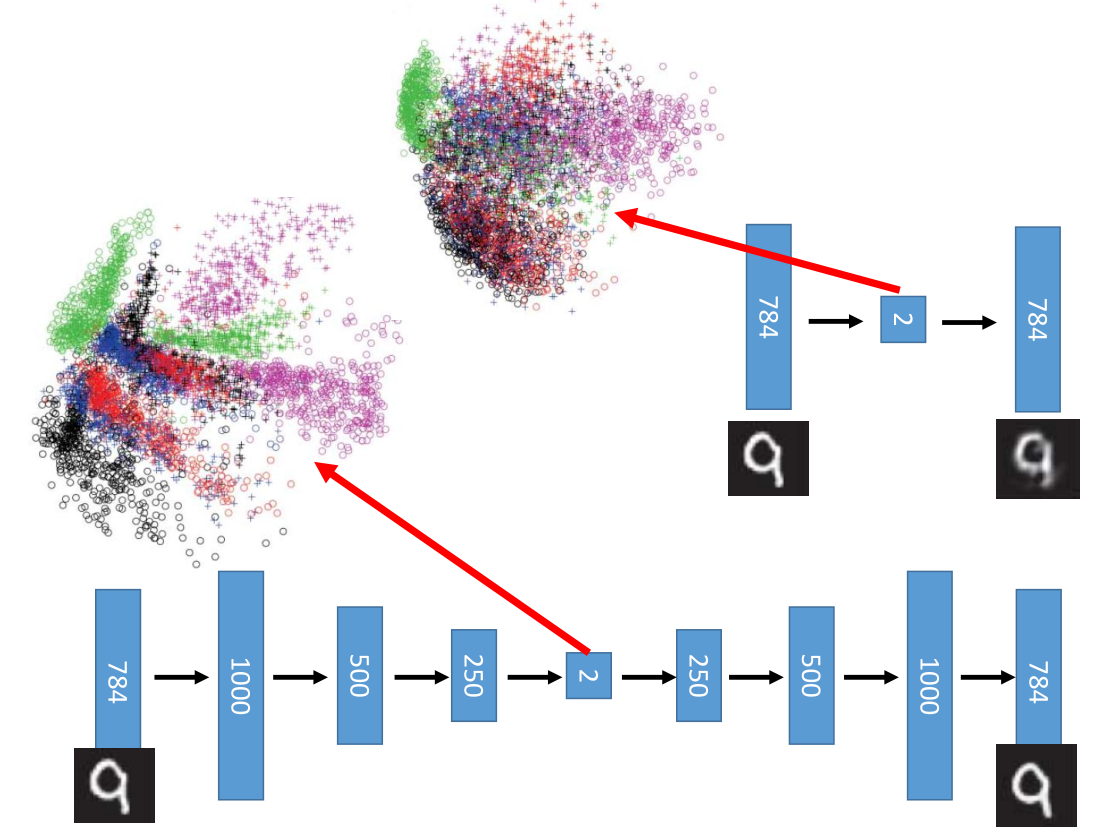
当 code 为二维时,很明显看到 Deep Auto-encoder 使数字手写识别集分类地更好。
- 添加噪声
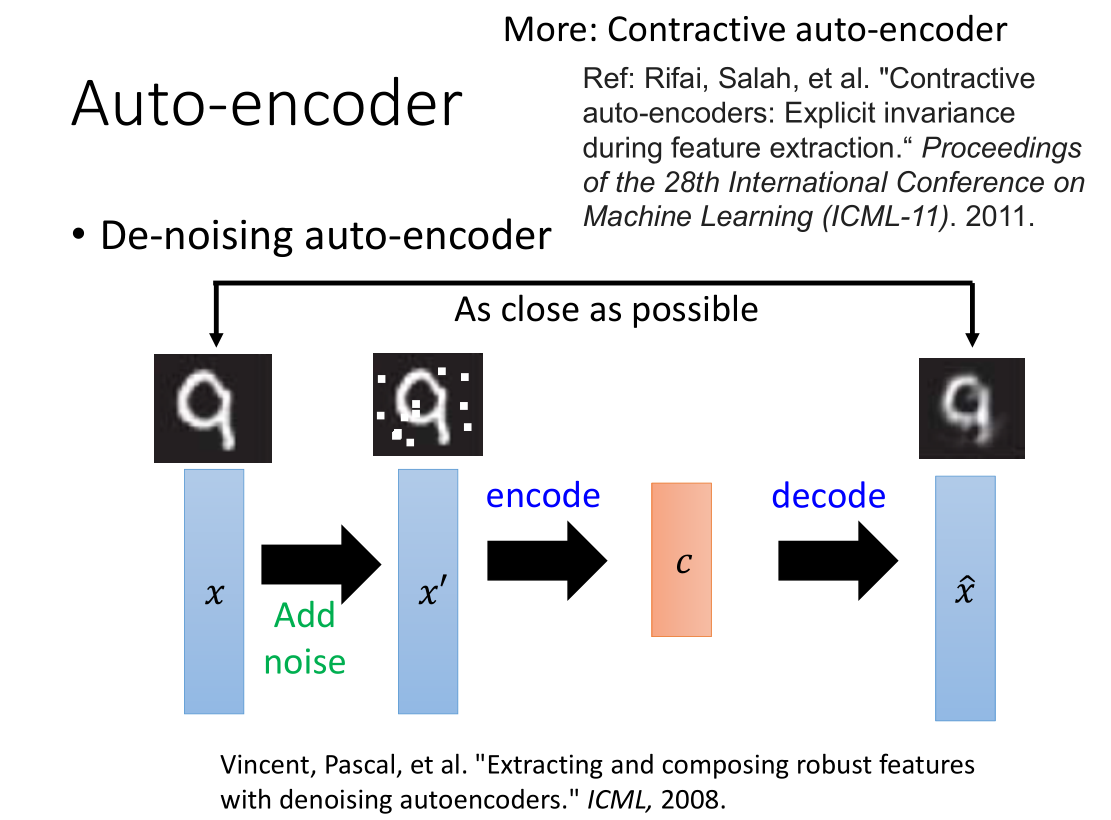
为了让 auto-encoder 学的更好,我们可以在输入加入噪音
3. 深度自动编码实例化
3.1 应用于图片
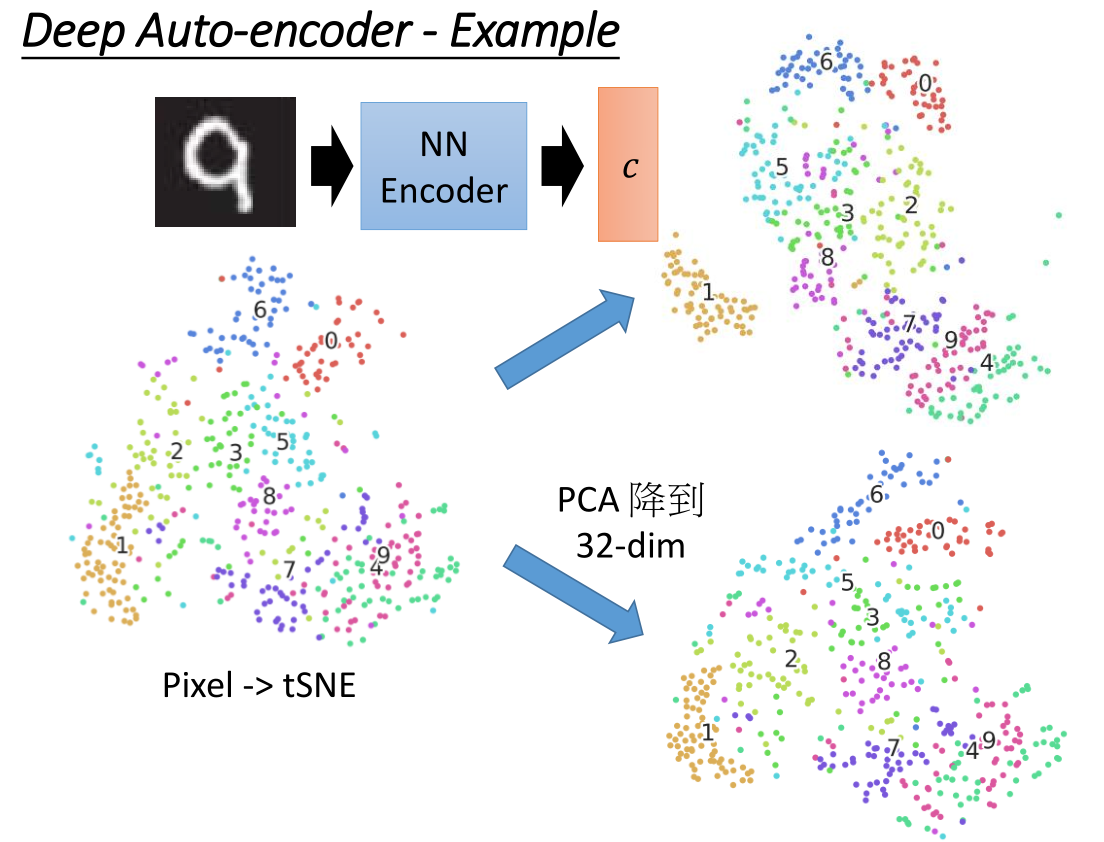
直接对像素做 t-SEN ,把 PCA 降维到32维,颜色分开效果还好。
与上面 Deep auto-encoder 对比:
1成功的被分开了,4与9与分开没有很明显,但是效果比原本混在一起好。
3.2 应用于文字处理
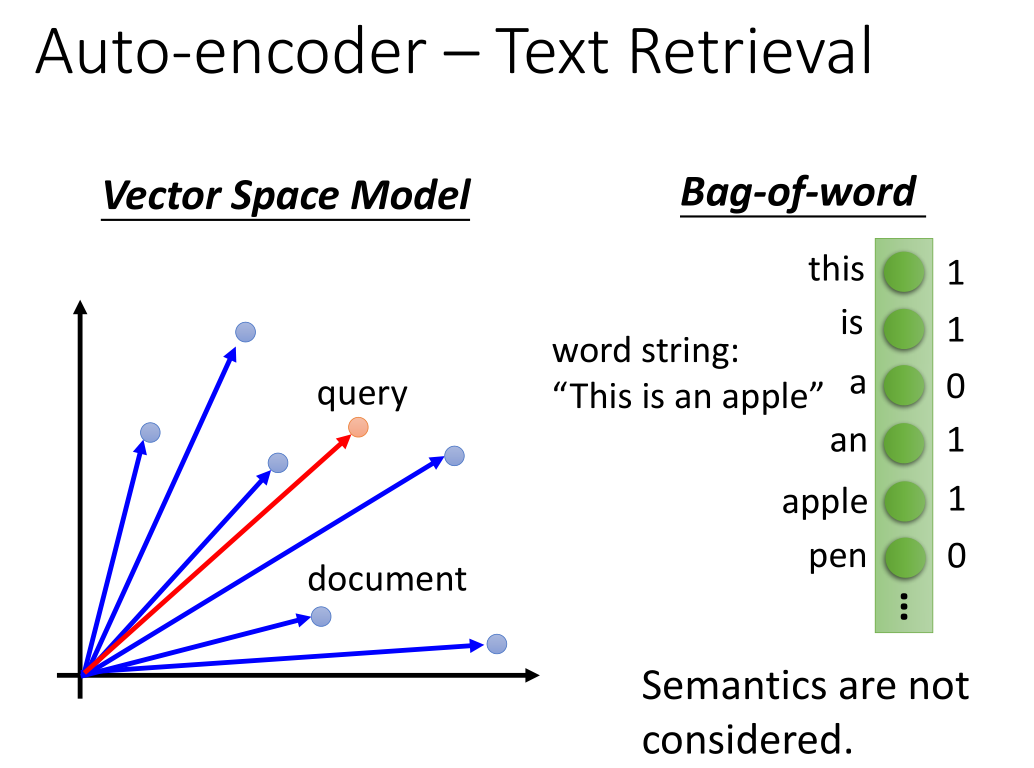
把文章变成一段 code ,得到 vector space model ,
把查询词汇也变成一个 vector ,从而进行查询。
比如图中与查询的向量接近的为红色左边和右边的文章向量,将向量解码后可能就是所查询得到的结果
一种方法是词袋,但是这种方法中每个词都独立,不能知道语意。
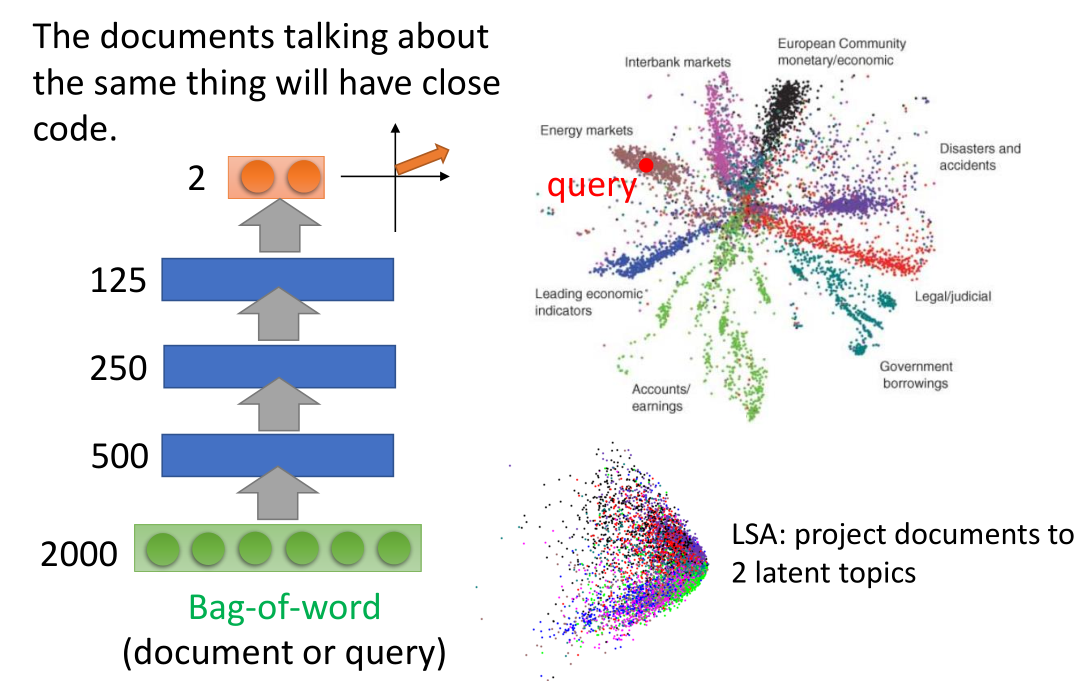
要把语意考虑进来的话,要用 Auto-encoder 。
词袋经过 auto-encoder 之后得到 code 。上图中不同颜色代表文档的不同种类。
3.3 应用于以图找图

如果基于像素计算图片之间相似度的话,得到的结果会比较差。
比如,会得到迈克尔杰克逊的照片比较像马蹄铁。

直接图像像素查找的效果不是太理想,选用深度自动编码,
先把图像像素作为 input ,总共5层,直至编码成256维度。
图片右上角是编码后解码回来的图像,比原图像模糊。

用编码后256维的信息寻找相似度接近的,结果就会好很多,最起码都是人脸了。
3.4 应用在CNN中
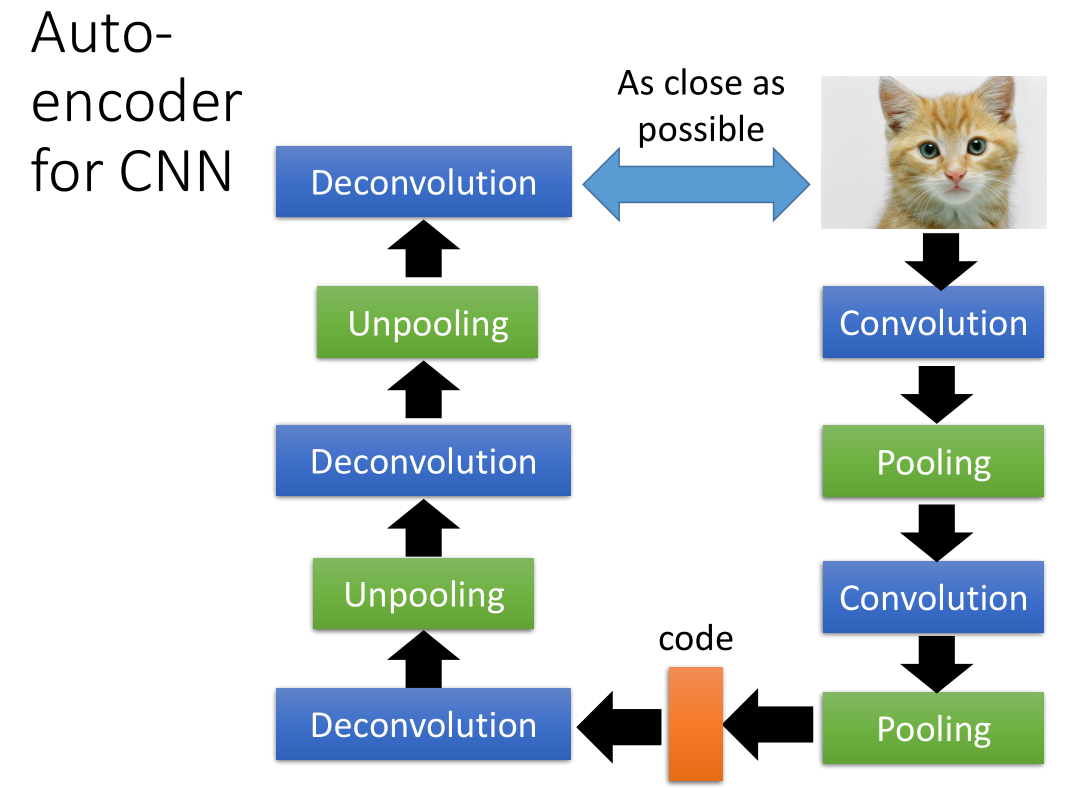
需要增加的隐藏层有 deconvolution 和 unpooling
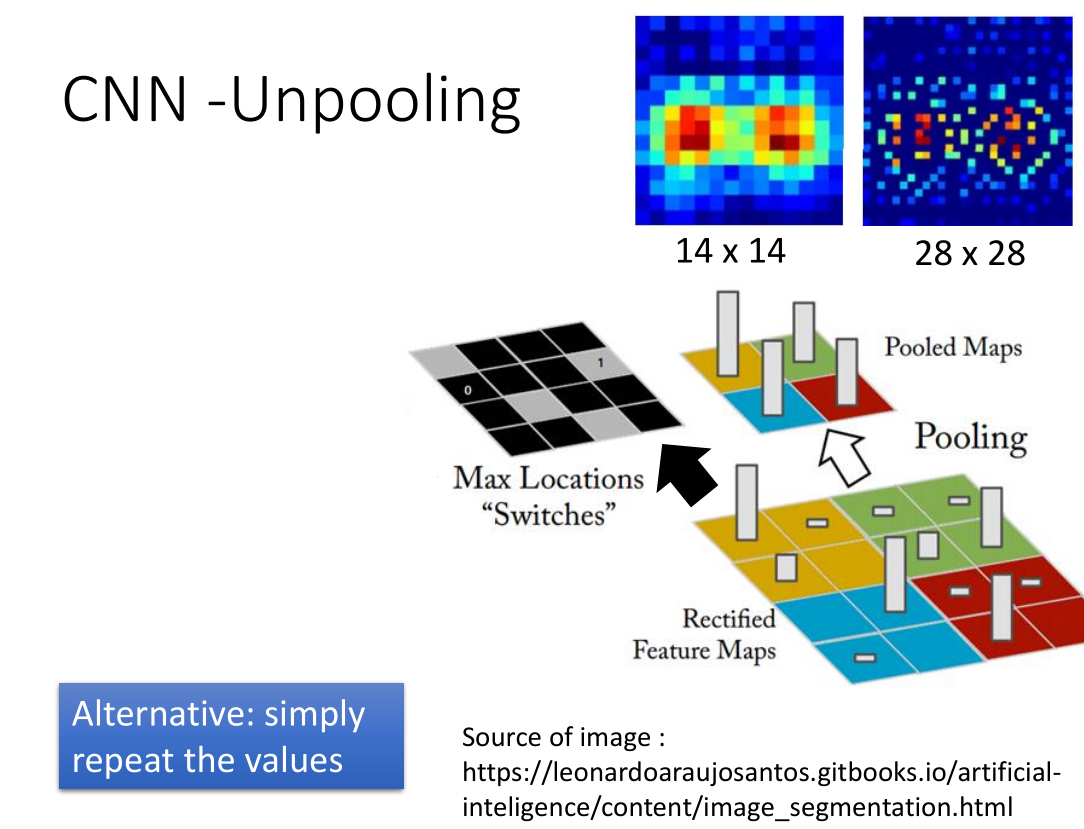
对于 unpooling ,我们只需要在 maxpooling 过程中把要把 max locations 记录下来,
然后 unpooling 时候还原其位置,其他全为0
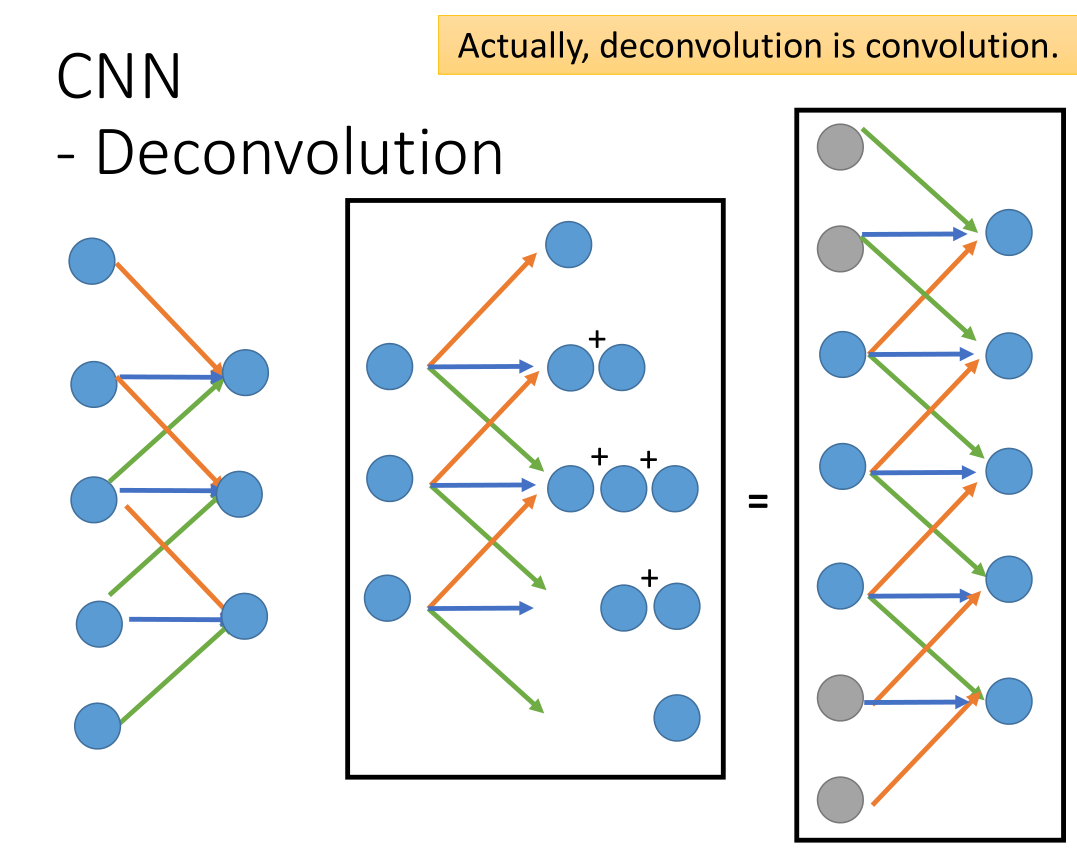
而 deconvolution 实质上就是 convolution 。
中间从三维扩展成五维的过程相当于右边通过CNN将七维降成5维(灰色的输入代表0)。
3.5 Pre-train DNN
Auto-encoder 还可以Pre-train DNN,第一步先将784维的数据转换成1000维,再将1000维的数据解码转换成784维,这样就可以通过比较先后784维度的数据更新得到w1。
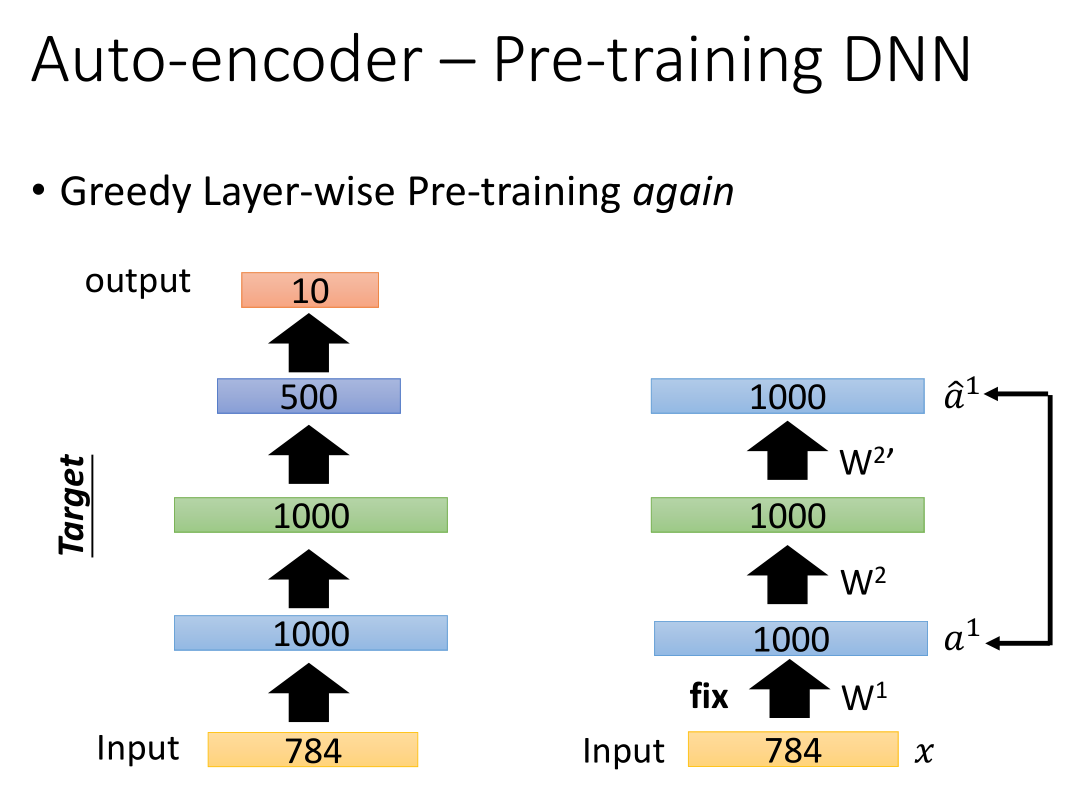
第二步可以得到 w2 ,依次类推
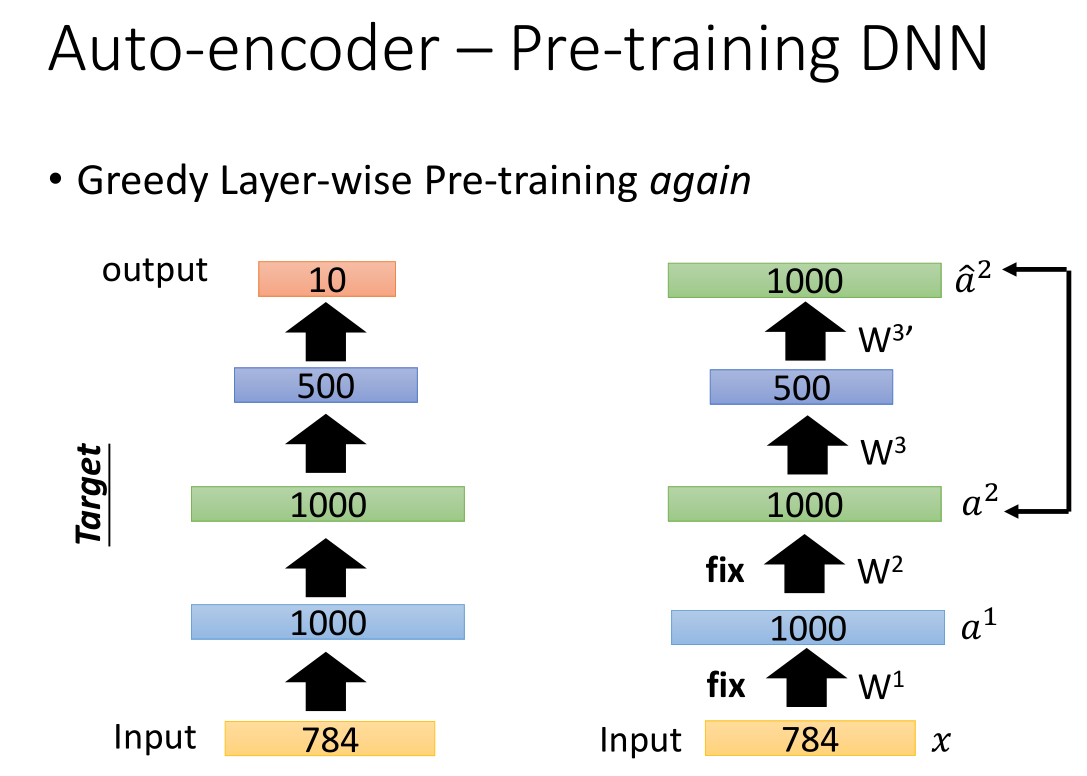
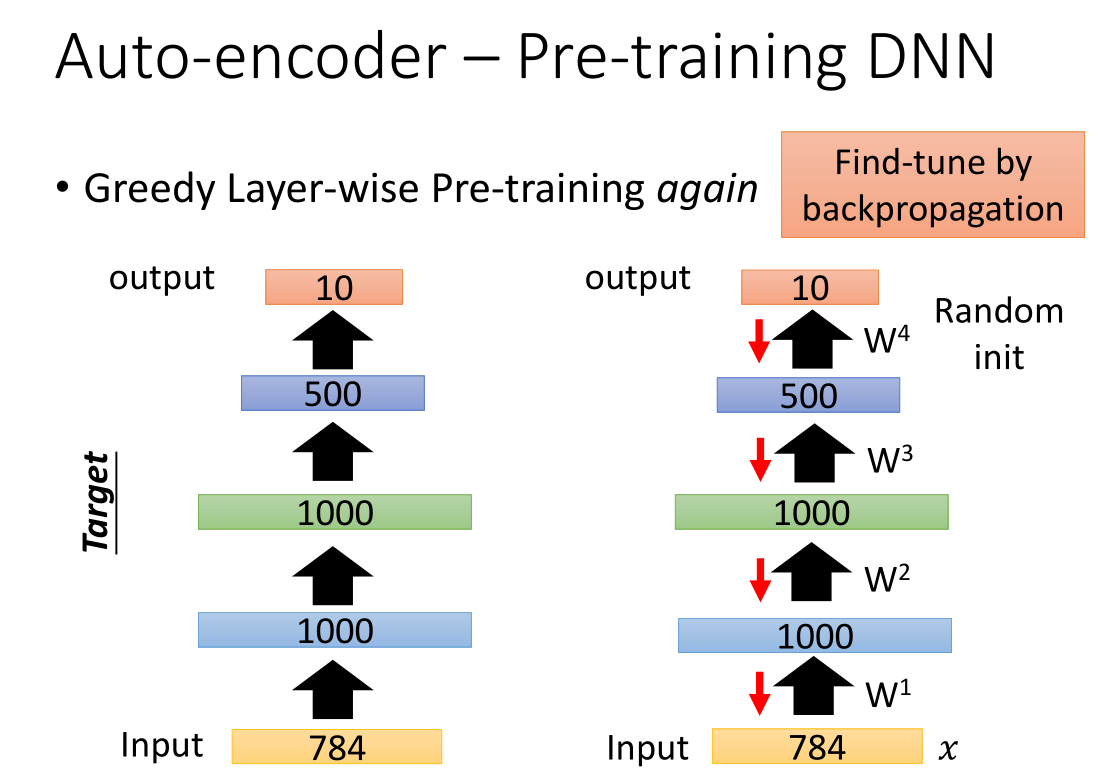
把 w1,w2,w3 当做初始的参数,把最后 output 接上去,再用反向传播更新所有参数
在训练第一个 auto-encoder 时,由于 hidden layer 的维数大于 input 维数,要加很强的正则项,
e.g.: 对1000维的输出做L1正则化(希望 output 稀疏)。
否则 hidden layer 可能直接记住 input ,没有 learn 到任何东西。
在训练第二个 auto-encoder 时,要把数据集中所有 digit 都变成1000维vector。
以此类推,最后随机初始化输出层之前的权重。然后用反向传播做 fine-tune (W1,W2,W3已经很好,微调即可)。
之前在训练较深的NN时要用到预训练,但是现在没必要了,因为训练技术进步了。
但在有大量无标注数据 、少量标注数据时仍需要预训练,
可以先用大量无标注数据先把W1,W2,W3先训练好,最后的标注的数据只需稍微调整权重就好。
如果你想了解更多,下面是关于restricted Boltzmann machine的资料
- Neural networks [5.1] : Restricted Boltzmann machine–definition
- https://www.youtube.com/watchv=p4Vh_zMwHQ&index=36&list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrN
- https://www.youtube.com/watchv=p4Vh_zMwHQ&index=36&list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrN
- Neural networks [5.2] : Restricted Boltzmann machine–inference
- https://www.youtube.com/watchv=lekCh_i32iE&list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH&index=37
- https://www.youtube.com/watchv=lekCh_i32iE&list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH&index=37
- Neural networks [5.3] : Restricted Boltzmann machine - free energy
- https://www.youtube.com/watchv=e0Ts_7Y6hZU&list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH&index=38
- https://www.youtube.com/watchv=e0Ts_7Y6hZU&list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH&index=38
下面是关于deep belief network的资料
- Neural networks [7.7] : Deep learning - deep belief networks
- https://www.youtube.com/watchv=vkb6AWYXZ5I&list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH&index=57
- https://www.youtube.com/watchv=vkb6AWYXZ5I&list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH&index=57
- Neural networks [7.8] : Deep learning - variational bound
- https://www.youtube.com/watchv=pStDscJh2Wo&list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH&index=58
- https://www.youtube.com/watchv=pStDscJh2Wo&list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH&index=58
- Neural networks [7.9] : Deep learning - DBN pre-training
- https://www.youtube.com/watchv=35MUlYCColk&list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH&index=59
Decoder 还可以生成我们想要的东西,比如图像


784维降到2维,根据向量的分布选择红框,在红框中等间隔采样,
作为解码的输入,得到计算机生成的图片。
如果红框选错了位置,比如选在右下方,可能得不到数字。
“需知道词向量分布”略麻烦,改进方法:加正则化。
在训练时,对 code 加L2正则化,这样 code 比较接近0。
采样时在0附近采样,这样采样得到的词向量比较有可能都对应数字。
4. 总结
- Auto-encoder 原理
- Deep Auto-encoder 原理及其应用