这一节我们主要学习
- Keras 简介
- 用 Keras 实现手写数字识别模型
- 小批量梯度下降(Mini-batch Gradient Descent)
1. Keras 简介
- TensorFlow、theano 的特点:方便灵活但是难以上手;
- Keras 是 TensorFlow 和 theano 的接口,容易上手使用且具备一定的灵活性;
- Documentation: http://keras.io/
- Example: https://github.com/fchollet/keras/tree/master/examples
- 用 Keras 实现深度学习,就像是在搭积木。
2. 用 Keras 实现深度学习的“Hello World!” —— 手写数字识别模型
2.1 手写数字识别
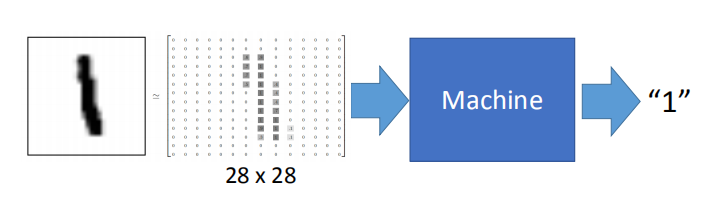
- MNIST Data: http://yann.lecun.com/exdb/mnist/
- Keras 提供数据集加载功能: http://keras.io/datasets/
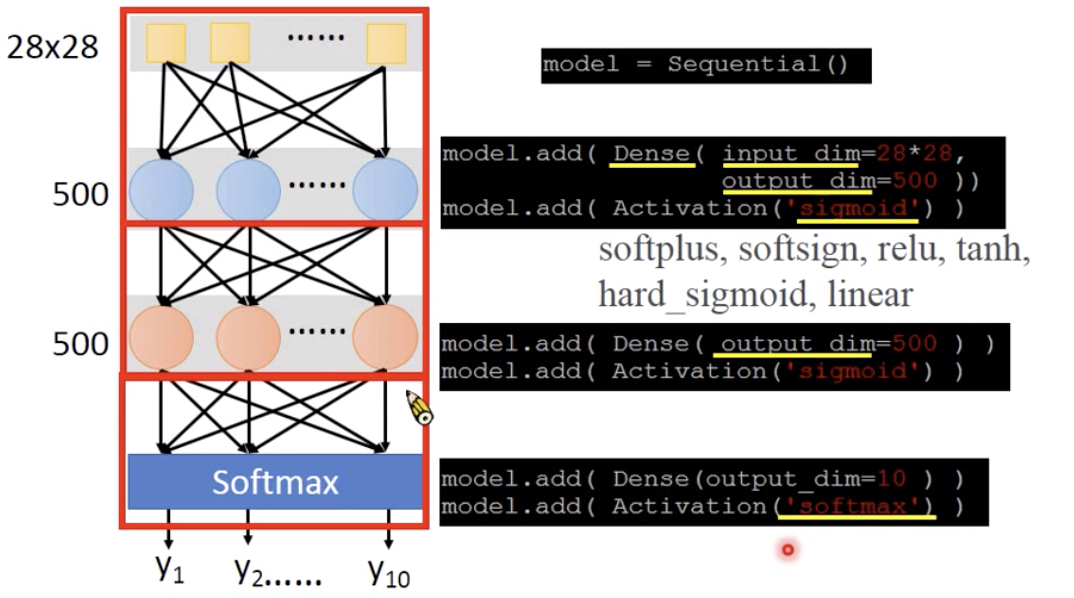
2.2 构建网络
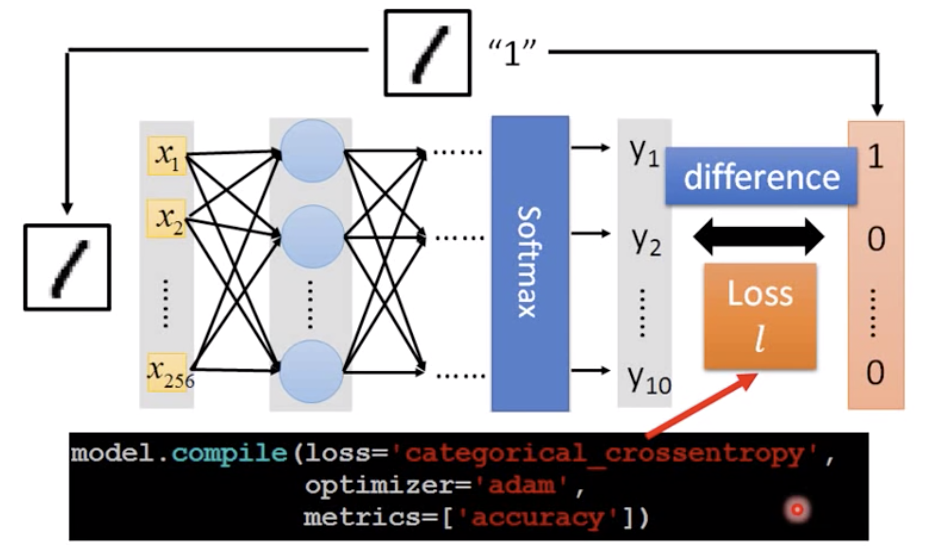
2.3 评价模型的好坏
- loss=‘categorical_crossentropy’
- Keras 中损失函数的几种选择:https://keras.io/objectives/
2.4 选择最佳的函数——训练
- 第一步,配置优化方式

- 第二步,训练

- 其中,x_train 和 y_train 都是 numpy array 的形式:
 其中:
其中:
- batch_size: 在实际操作中,我们并不会最小化总的损失函数,而是把训练集分成多个 batch,每次最小化一个 batch 的总损失 —— 小批量梯度下降法(Mini-batch)。
- nb_epoch: 将所有的 batch 都跑一遍叫做一个 epoch。

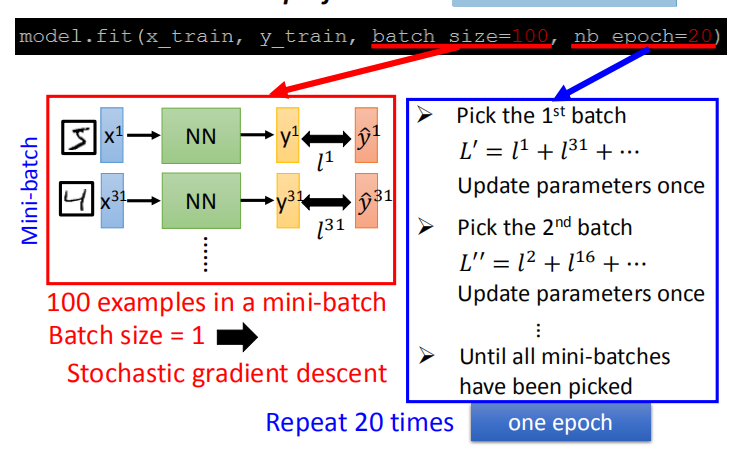
- 如果 batch_size 设为1,小批量梯度下降法(Mini-batch Gradient Descent)就相当于随机梯度下降法(SGD)。
- 随机梯度下降法特点是参数更新的更快,不稳定。小批量梯度下降法特点是参数更新慢,更稳定。
- 实际操作中,相同时间内,两种梯度下降算法参数更新的次数相当,所以我们更倾向于稳定的小批量梯度下降法。
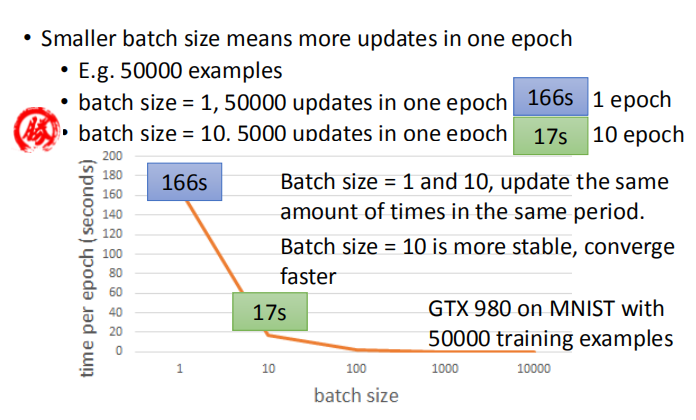
- Batch_size 不能过大的原因:1. GPU 平行运算的能力是有限度的;2. 容易陷入局部最优点(这也是 SGD 的随机性可以解决的问题)。
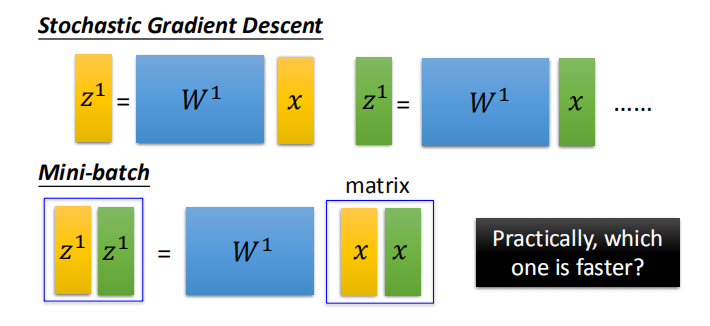
- 小批量梯度下降法比随机梯度下降法更快的原因是前者可以调用 GPU 平行运算:
3. Keras 补充
-
保存和加载模型: http://keras.io/getting-started/faq/#how-can-i-save-a-keras-model
-
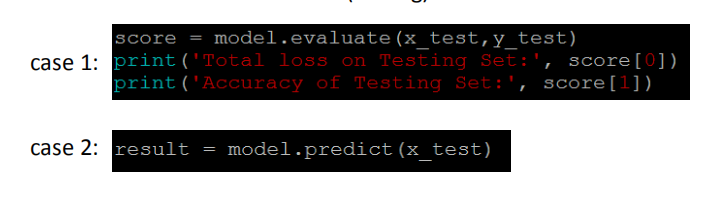
帮你做测试:1. 有测试集的情况下算正确率(score[0]:损失,score[1]:正确率) 2. 只有输入的情况下做预测。