这一节我们主要学习
- 序列标签
- 隐马尔科夫模型
- 条件随机场
- 结构感知器和结构化支持向量机
1. 序列标签
输入为一个序列,输出为另一个序列。不仅 RNN 可以解决这个问题,同时基于结构化学习也能解决这个问题。
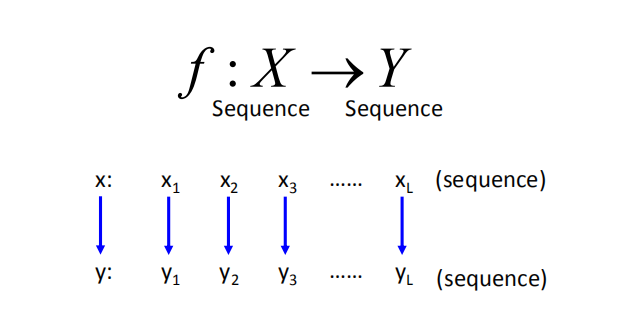
1.1 任务——词性标注
- 用词性注释句子中的每个单词
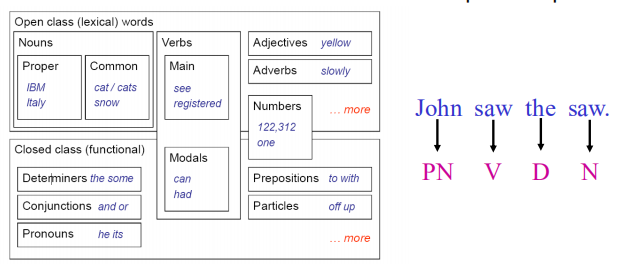
- 对后续的句法分析和词义消歧等有用。

2. 隐马尔科夫模型
- 如何产生一个句子
- 第一步:根据语法,产生词性序列
- 第二步:根据字典,有给出的词性序列产生一个句子
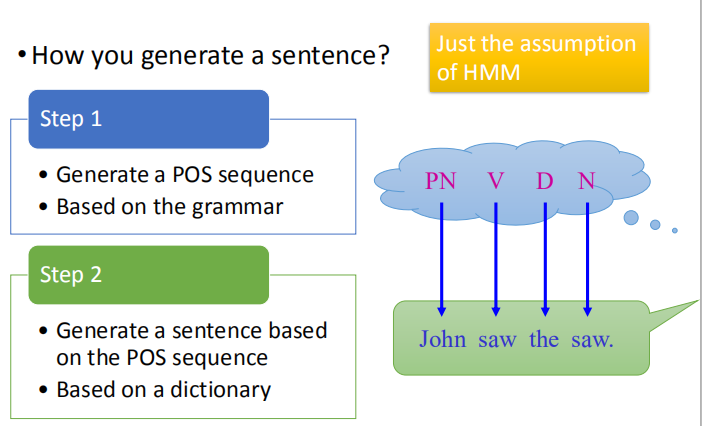
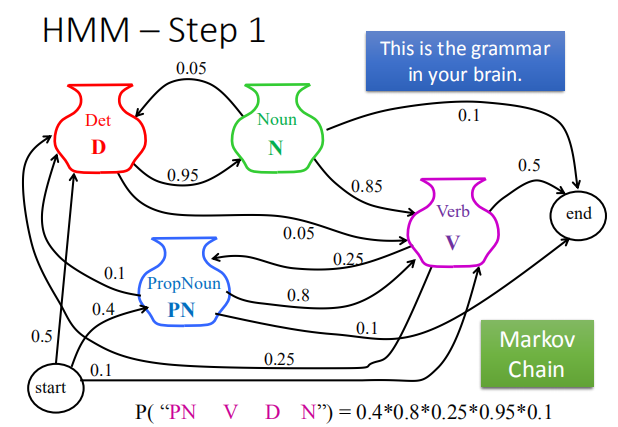
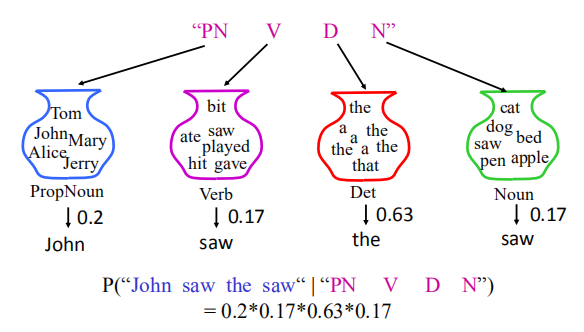
如何计算 $P(x,y)=P(x)P(y|x)$?
计算过程如下:

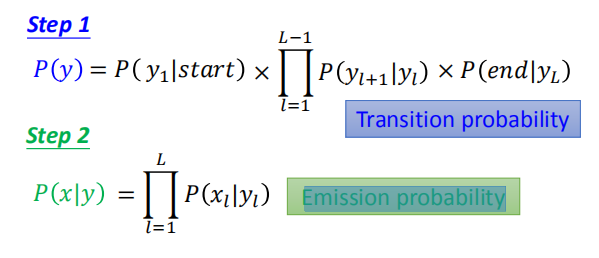 第一步计算转换概率,第二步计算发射概率。
第一步计算转换概率,第二步计算发射概率。
- 估算概率
- 如何计算$P(V|PN),P(saw|V)$?
- 从训练数据中获得

使用训练样本中事件发生的频率来估计概率:
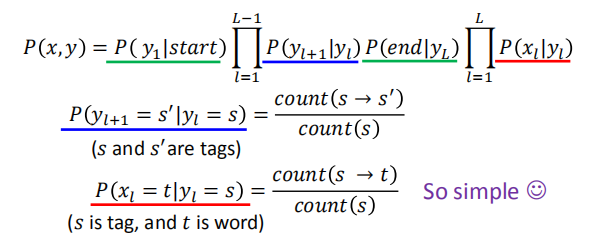
有了各个事件发生的概率之后,我们就可以求出可能性最大的 $y$

如果枚举所有的 $y$,计算的复杂度会非常的大;
这里我们使用维比特算法来求解可能性最大的 $y$

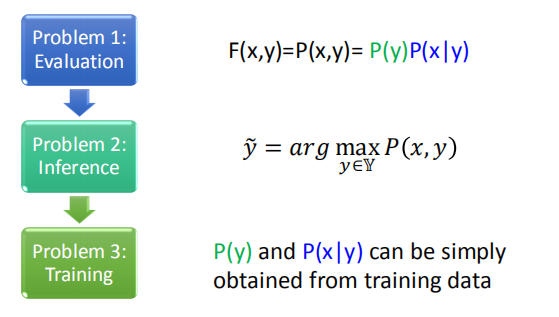

按照训练集的数据来看,$y_l$ 最可能应该是 $D$,但是 HMM 模型可能会自行“脑补“出 $V$.

- 优点:
- 当训练数据较少的时候,使用 HMM 模型比较好。
- 缺点:
- HMM 模型可能产生样本中并未出现的情况;使用 CRF 模型可以解决该问题。
- HMM 模型并不能保证数据集中数据点发生的概率是最大的
3. 条件随机场
3.1 CRF
$P(x,y)∝ exp(w \cdot \phi(x,y))$
- $\phi(x,y)$ 是特征向量
- $w$ 是通过训练数据学习出来的权重向量
- $exp(w \cdot \phi(x,y))$ 为正,有可能大于 1
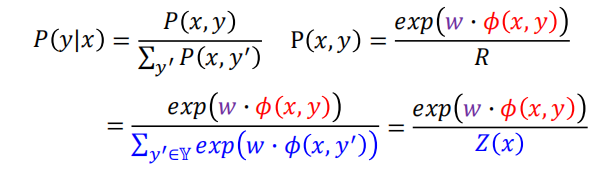
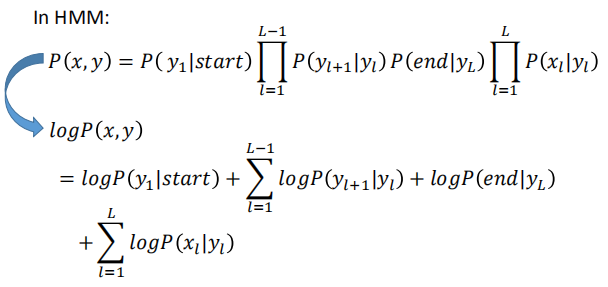 将 $P(x,y)$ 两边同取 $log$ 变换
将 $P(x,y)$ 两边同取 $log$ 变换
 将 $\sum logP(x_l|y_l)$ 表示成 $\sum logP(t|s)*N{s,t}(x,y)$ 的形式
将 $\sum logP(x_l|y_l)$ 表示成 $\sum logP(t|s)*N{s,t}(x,y)$ 的形式
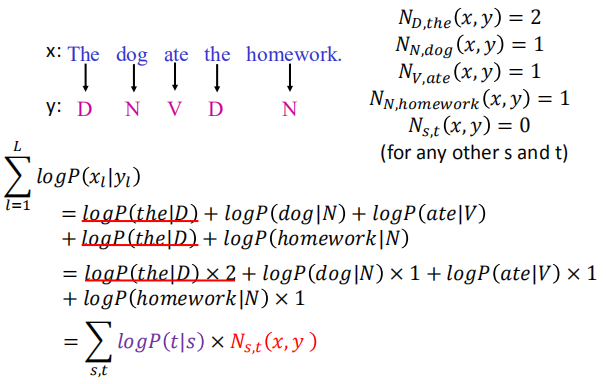
同理,对于 $logP(x,y)$ 可以得到如下的结果:

将上式表示成特征向量乘以权重向量的形式:
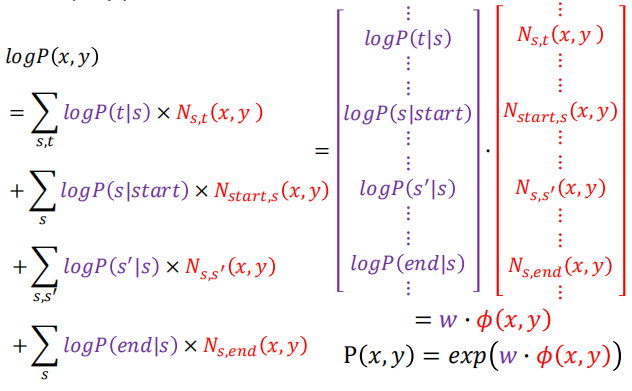 注意:
注意:
 由于我们在训练的时候没有给$w$任何的限制,是有正有负的,我们将 $=$ 改为 $ ∝$(成正比)。
由于我们在训练的时候没有给$w$任何的限制,是有正有负的,我们将 $=$ 改为 $ ∝$(成正比)。
3.2 特征向量
$\phi (x,y)$ 有两部分:
- 标签和单词之间的关系
该部分的维度可能比较大,但是非零的值比较少,较为稀疏

- 标签之间的关系
该部分的维度和标签的个数相关
 ** 注:$\phi (x,y)$ 可以定义为任意你想要的**
** 注:$\phi (x,y)$ 可以定义为任意你想要的**
3.3 训练标准
 我们需要增大我们观察到的事件的概率,减小未观察到的事件的概率。
我们需要增大我们观察到的事件的概率,减小未观察到的事件的概率。
3.4 梯度上升

3.5 训练

- 第一项表示(绿下划线):如果单词被标签s标记在训练集中,那么就要增大 $w_{s,t}$
- 第二项表示(黄下划线):如果单词被标签s标记不在训练集中,那么就要减小 $w_{s,t}$
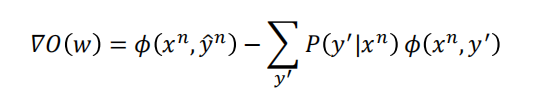
随机梯度下降:
随机选择一个数据$(x^n,y^n)$,进行训练:
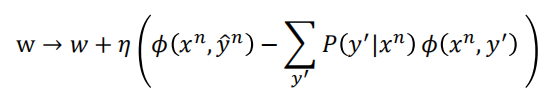
3.6 推理
用维特比算法求出最大的y。
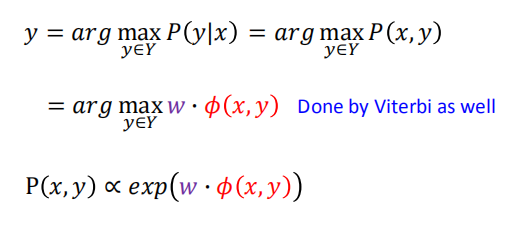
3.6 CRF v.s. HMM

相比于 HMM,CRF 除了增大正确事件发生的概率外,同时减小了错误事件发生的概率(HMM 就没有减小);
因此,CRF 通常可以产生更好的结果。

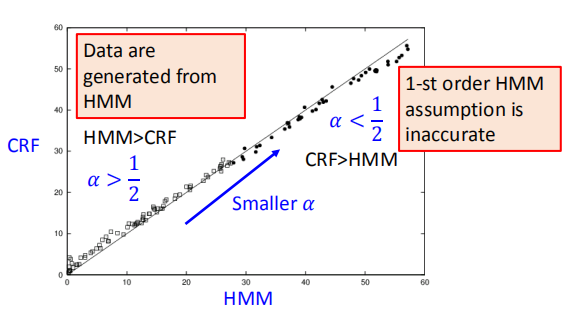 当$\alpha$越小时,实验结果越差;
当$\alpha$越小时,实验结果越差;
当$\alpha > \frac {1}{2}$时,HMM的表现更好;
当$\alpha < \frac{1}{2}$时,CRF的表现更好。
3.7 总结
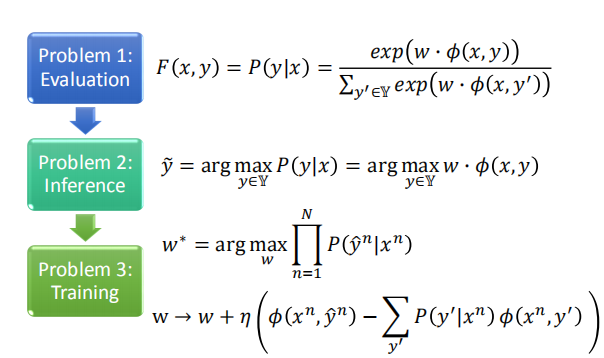
4.结构感知器和支持向量机
4.1 结构感知器
结构感知机的模型如图所示,

 不同的地方在于结构感知机减去的几率最大的 y 形成的 $\phi$;
不同的地方在于结构感知机减去的几率最大的 y 形成的 $\phi$;
CRF减去的是所有可能的 y 形成的 $\phi$ 乘上发生这个 y 的概率。
4.2 结构化支持向量机
 在步骤三中,与结构感知器不同的是,结构化支持向量机需要考虑边距和误差,方法有:
在步骤三中,与结构感知器不同的是,结构化支持向量机需要考虑边距和误差,方法有:
- 梯度下降法
- 二次规划(切割平面法)

-
$\Delta(\hat y,y)$:y 与 $\hat y$ 的偏差
-
结构化支持向量机的损失函数是误差函数的上界
-
理论上,误差函数可以设置为任何你喜欢的样子
-
在设置误差函数时,要保证能够 Problem $2.1$ 能够方便地解决。
- Problem $2.1$ : $\hat y^{n}$ = argmax[$\Delta(\hat y,y)+w \cdot \phi(x^{n},y)$](可以用 Vitervi 算法解决)
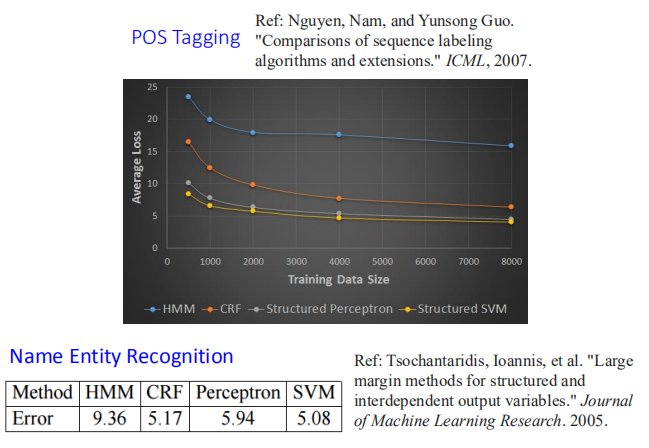
不同方法的实验结果:

- CRF,结构化支持向量机等的优点:
- 考虑整个序列
- 可以明确考虑标签依赖性
- 损失函数是误差的上界
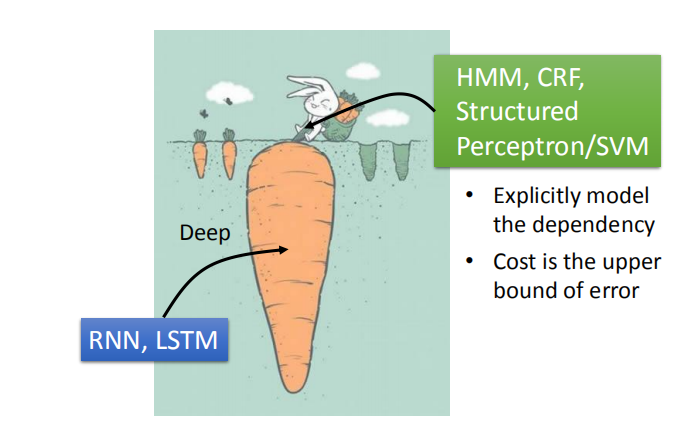
- RNN 的优点:
- 网络结构比较深
但是,RNN 的优点相比于 CRF,结构化支持向量机等的优点更好,所以 RNN 表现得过更好。
- 语音识别: CNN/LSTM/DNN + HMM
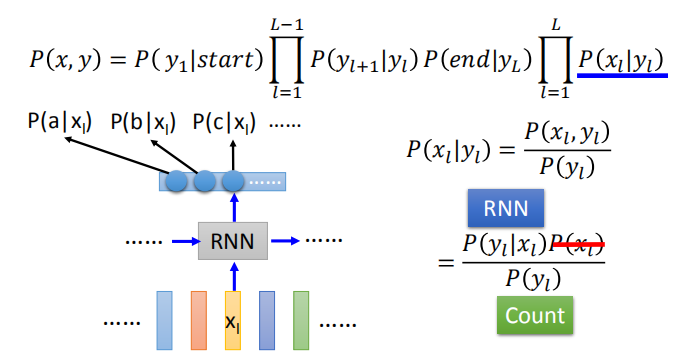 用贝叶斯公式求解概率 $P(x_l|y_l)$
用贝叶斯公式求解概率 $P(x_l|y_l)$
- 语义标记:Bi-directional LSTM + CRF/Structured SVM
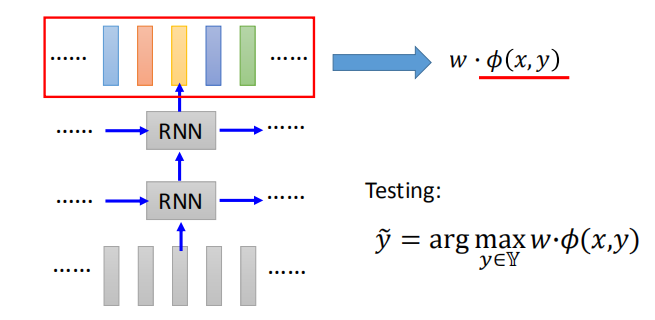 利用 RNN 模型得到特征向量,再用 CRF 进行标记。
利用 RNN 模型得到特征向量,再用 CRF 进行标记。
5.总结
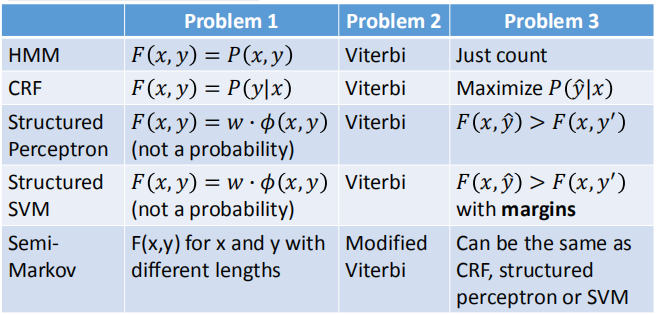 这些方法都能加上深度学习,从而有一个更好的表现
这些方法都能加上深度学习,从而有一个更好的表现