- 1.网络结构是否越深越好
- 2.神经网络模块化思想
- 3.端到端学习
- 4.处理复杂问题中深层网络的作用
1. 网络是否越深越好
理论上,一层隐藏层的神经网络就可以表示任意的函数,但是从效率、精度考量,
在实际的神经网络构建中往往采用多个隐藏层(即深度学习)。
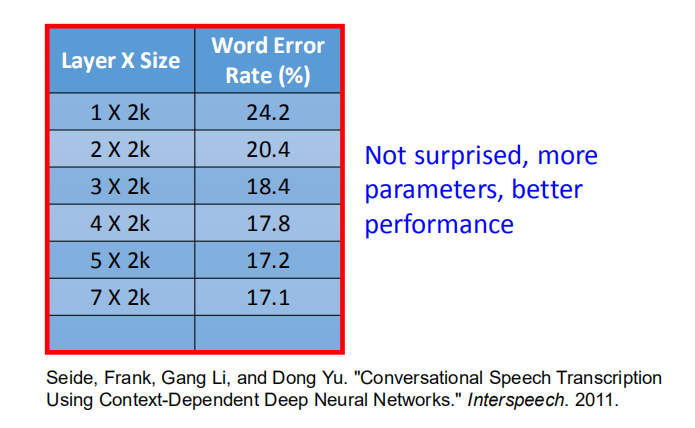 从上图对比可得,在神经元个数相同的情况下,多层神经网络的精度高于单层神经网络。
从上图对比可得,在神经元个数相同的情况下,多层神经网络的精度高于单层神经网络。
1.1 胖+短的网络 VS. 瘦+高的网络
那么,在参数相同的情况下,哪种网络的表现更好呢?
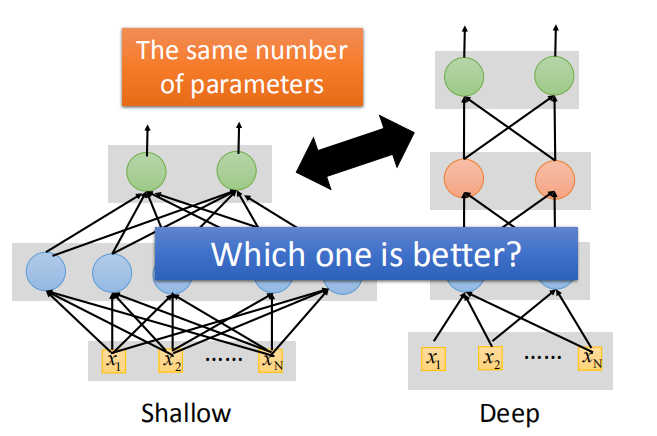
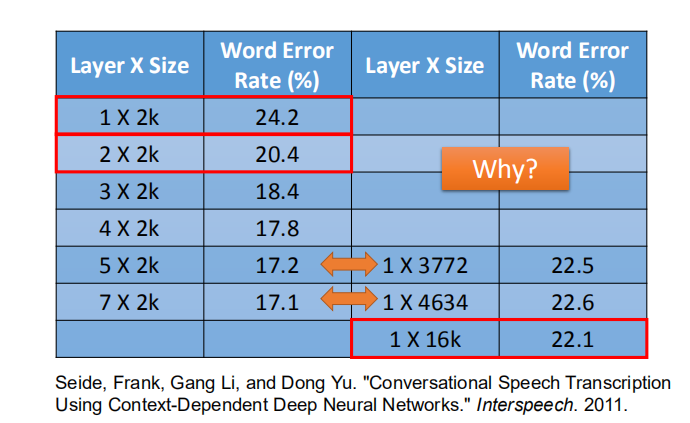
实验结果表明瘦而高的网络(层数多的),即深度神经网络,实验结果更好。
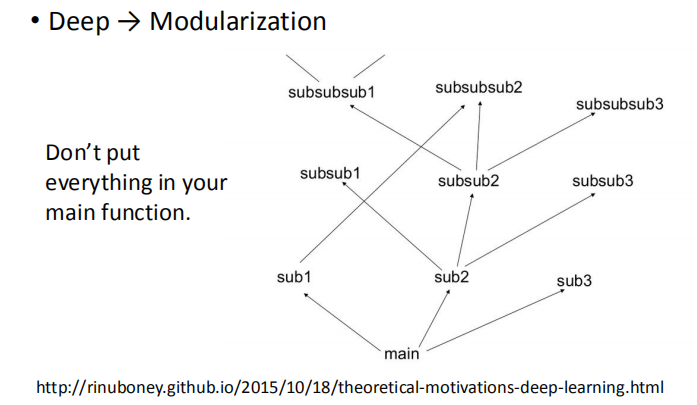
2. 模块化
通常,我们在写程序时,我们不会将所有的功能都放到主函数中,
我们会将一些常用的功能写成模块,以供反复调用,这其实就是模块化思想。
 网址链接: http://rinuboney.github.io/2015/10/18/theoretical-motivations-deep-learning.html
网址链接: http://rinuboney.github.io/2015/10/18/theoretical-motivations-deep-learning.html
2.1 分类问题
我们需要将一个图像分为长头发男孩,短头发男孩,长头发女孩,短头发女孩四类;
但是我们遇到一个问题,长头发男孩的例子比较少,不好分类。
所以模型训练出来的效果对测试集上的长发男生效果会比较差(样本不平衡)。
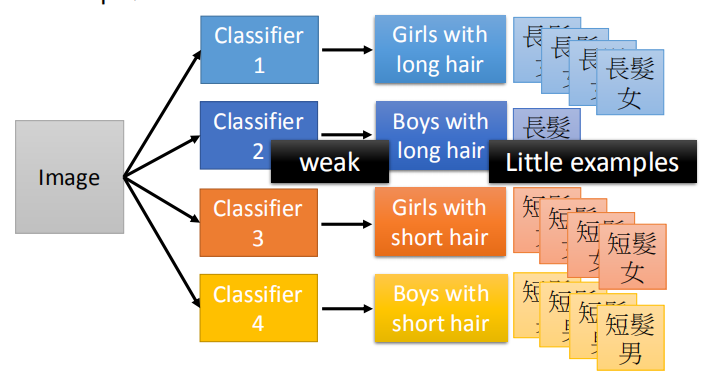
我们将该问题进行模块化处理,变成两个基础分类问题,是男孩还是女孩以及是长发还是短发。
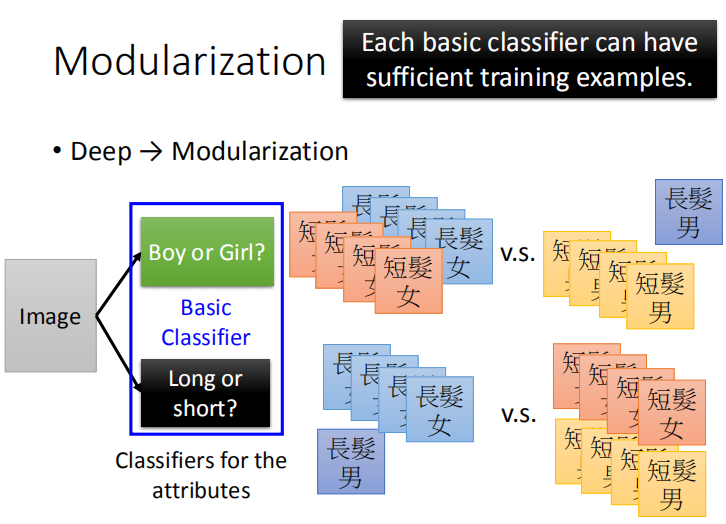 这样每一个基础的分类都有足够的例子进行训练。
这样每一个基础的分类都有足够的例子进行训练。
此时样本比例是相当的,由此训练的效果不会变差,且由两个基础类别的组合可以得到最终的四个类别。
通过将简单分类的结果组合得到最终的分类结果:

2.2 深度学习中的模块化
深度学习的优势就体现在模块化的处理方式上。
在深度学习的网络结构中,上一层的神经元可以作为下一层的模块,模块是通过学习数据自动生成的。
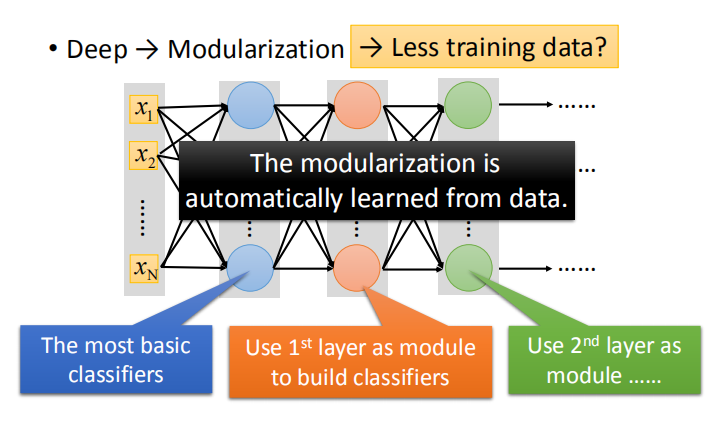
由上述例子可以看出,使用模块化的网络,我们可以使用更少的数据进行训练。
2.3 模块化应用之语音识别
- 人类语言的层次架构
比如一句 what do you think,这一句话其实是有很多音位(区分单词最小语音单元)组成。
同样的音位可能会有不一样的发音(比如 d uw 和 y uw 中,由于前一个音素不同,所以导致口腔真正发出的两个 uw 不一样),
因此我们给同样的音位不同的模块(Tri-phone,该音素加上前后两个音素)。
语音识别简而言之:从声音信号输出声音的特性(state),再从特性转成音位 ,最后音位转成文字。
由于人在说话时,每个字母的发音因前后字母的不同而有着不同的发音,
所以我们将一个 Tri-phone 称为一个发音单元,每一个 Tri-phone 有3个特征。
- 语音识别步骤一(整个语音识别比较复杂,课程里面只讲第一个步骤)
- 分类:输入→声学特征,输出→状态
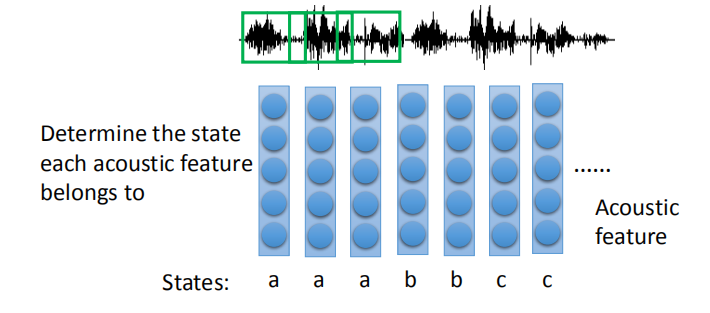 在语音的时序图中以一定大小的 window(如:250毫秒,上图中绿色框框)取出数据,然后用 acousitc feature 表示。
在语音的时序图中以一定大小的 window(如:250毫秒,上图中绿色框框)取出数据,然后用 acousitc feature 表示。
一段声音就表示成为 acousitc feature sequence 。
语音识别的第一步就是要决定 acousitc feature 属于哪个 state ,相当于一个分类问题。
也就是要构建一个分类器,把 acousitc feature 分类,决定是哪个 state ,后续还要把 state 转化成音位,最后组合成字并考虑多义字。
- 每个状态都有一个声学特征的固定分布
高斯混合模型( Gaussian Mixture Model ):

每个 state 用一个高斯分布来描述,参数过多,传统语音识别解决问题的方法就是 tied-state ,
意思就是有些 state 会共用一个高斯分布(就好比编程里面的不同指针指向的是相同地址),
至于如何决定哪些 state 会共用一个高斯分布,则需要 domain knowledge 来决定。
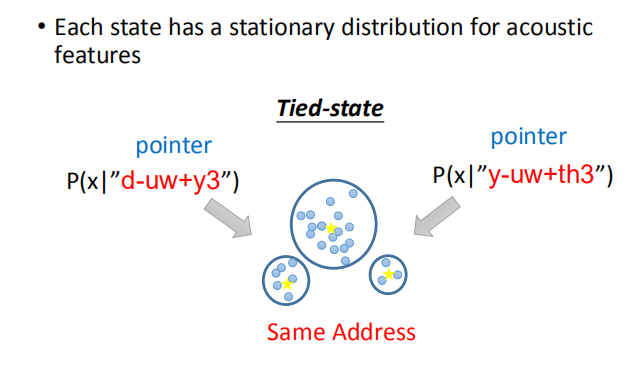
在 HMM-GMM 模型(隐马尔可夫模型-高斯混合模型)中,所有音位都是独立建模的、不相关的。
可以发现 state1 和 state 在某些时候可以共享高斯分布,有的时候又可以独立分布。
但是这样效率不高,因为人类语言发音是有一定关系。
 元音的发音受几个因素的控制。
它受三个因素影响:
舌头前后的位置、
舌头上下的位置、
嘴型。
元音的发音受几个因素的控制。
它受三个因素影响:
舌头前后的位置、
舌头上下的位置、
嘴型。
2.4 使用 DNN 处理语音识别
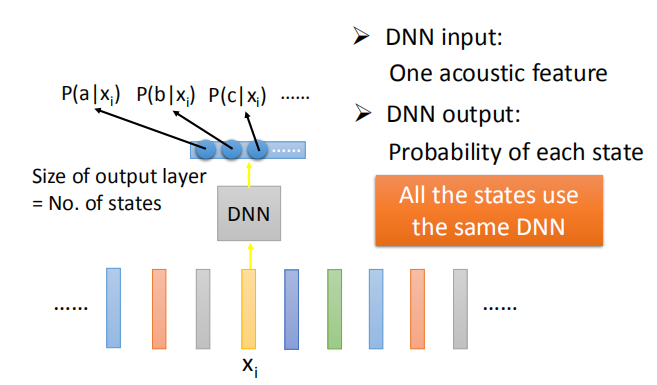 输入为声学特征;输出为每个 state 的概率。
输入为声学特征;输出为每个 state 的概率。
在 DNN 中,所有的 state 使用同一的模型,虽然 DNN 模型中使用的参数更多;
但是由于只需要使用一个模型,参数的数量与 HMM-GMM 模型中使用的参数数量相差无几。
DNN 模块化:
将中间层的输出结果进行降维可视化,得到如下结果:
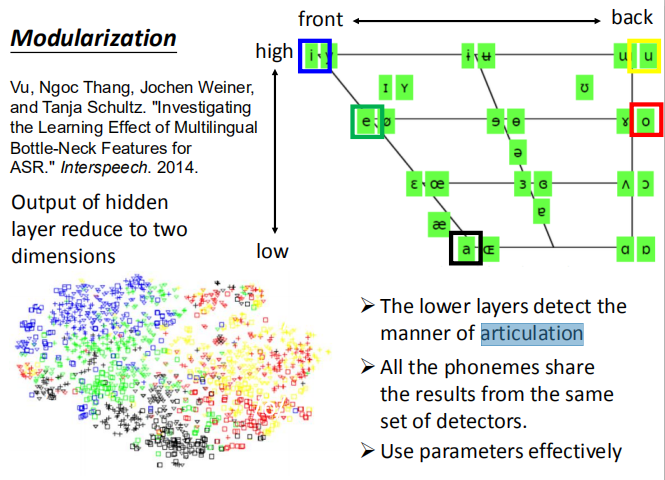
-
隐藏层可以检测关节处的动作,模拟人类发音时舌头的动作,判断这个声音人类是如何发出来的(舌头位置);
-
所有音位(phoneme)共享来自同一组探测器的结果,即模块化;
根据这个结果来判断 acousitc feature 属于哪个音位或属于哪个 state。
-
这样可以有效地使用参数; cousitc feature 可以用同一个 DNN 来进行识别。
2.5 通用原理总结
任何连续的函数都可以用单层神经网络来表示(给定足够多的神经元),这个已经有证明,见《深度学习》第四章。
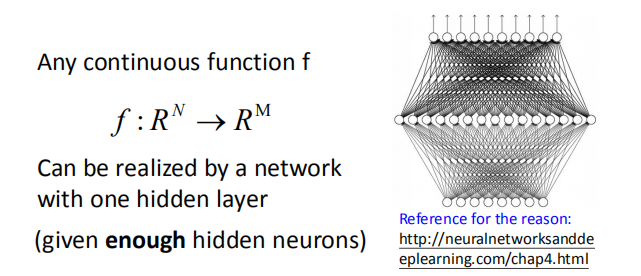 虽然浅层网络能够代表任何函数,但是深度网络更加高效。
虽然浅层网络能够代表任何函数,但是深度网络更加高效。
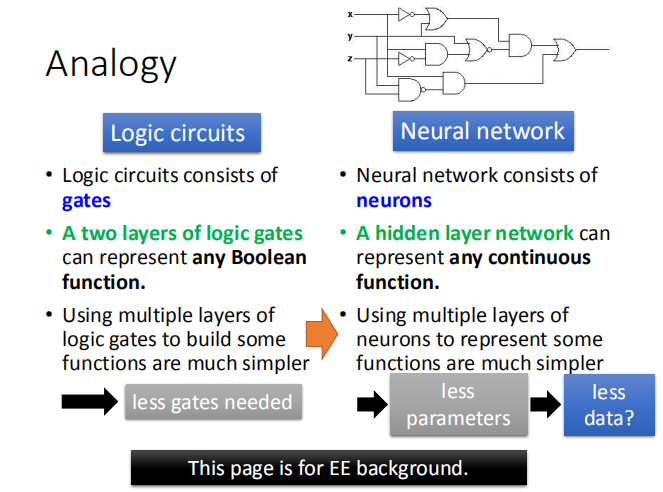
2.6 逻辑电路类比神经网络
使用两层逻辑门电路可以表示任何的布尔函数,但是使用多层逻辑门电路实现一些函数更加简单;深度神经网络亦是如此。
神经网络需要的参数少,好处多多,不容易过拟合,需要比较少的数据就完成训练。
举个栗子,奇偶校验( parity check ):
我们使用多个同或门实验奇偶校验的电路,右上角是 XNOR 真值表。
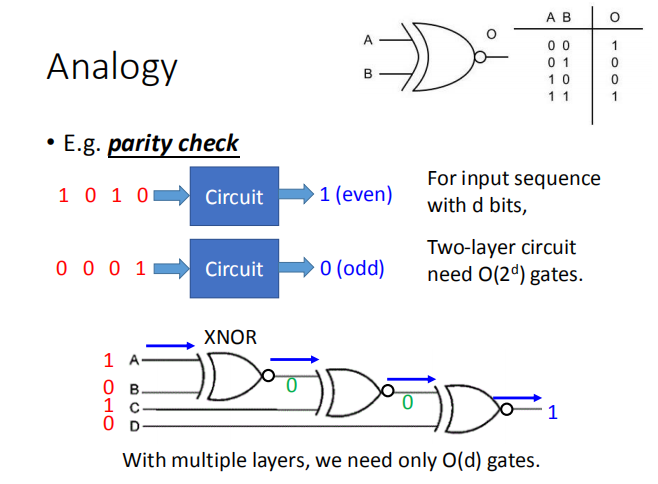 如果使用两层逻辑门电路时,我们需要 $O(2^d)$ 个逻辑门;
如果使用两层逻辑门电路时,我们需要 $O(2^d)$ 个逻辑门;
如果使用多层逻辑门电路时,我们只需要 $O(d)$ 个逻辑门电路。
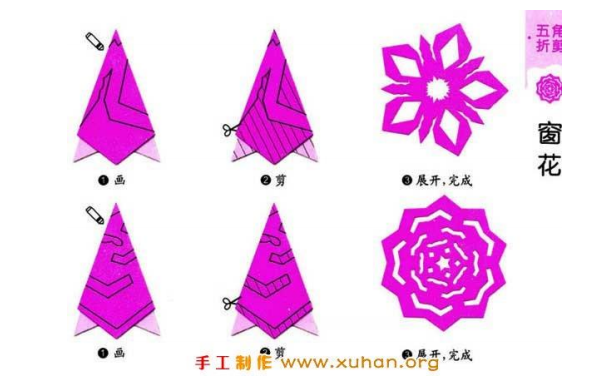
另外一个栗子,剪窗花:
折了再剪,只用剪几下就能构造出更加复杂的形状,这个与神经网络有什么联系?
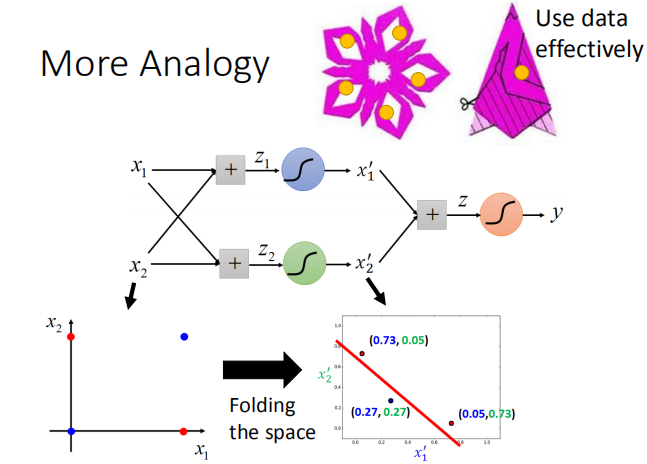
回到之前讲逻辑回归划分异或坐标点的例子:
增加一个隐藏层实际上是将 feature 进行特征转换,以便于分类。
让我们做个小实验:
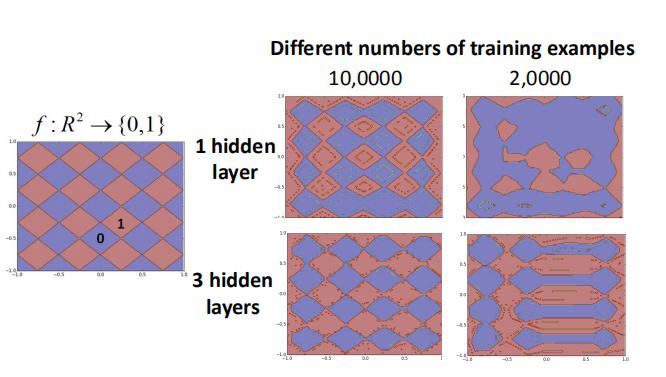 左图是函数,输入的是对应的 X,Y 坐标,输出为0和1,函数形状就是菱形的纹路。
左图是函数,输入的是对应的 X,Y 坐标,输出为0和1,函数形状就是菱形的纹路。
右图上为1个隐藏层,下为3个隐藏层,不同训练样本个数的学习效果,
这里要注意的是1个隐藏层和3个隐藏层的参数是基本相同的。
可以看出,10万训练数据的时候两个神经网络都差不多,
当只有2万训练数据的时候3个隐藏层的神经网络的结果还是比较好。
3. 端到端学习
- 生产线( production line )
一个模块由许多个简单的功能块组成,而每一个功能块对应深层网络中的一层,可以通过数据训练自动的生成。
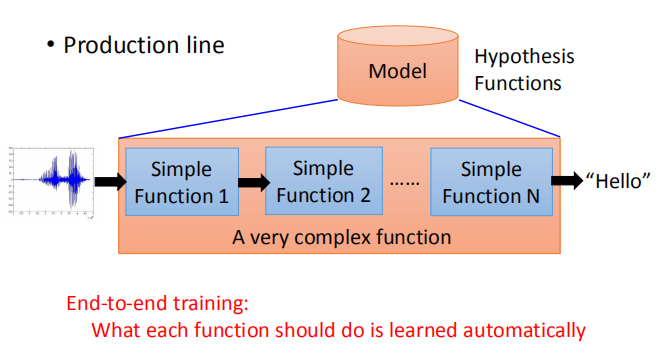 比如,在语音辨识中先将语音信号送进去,通过模块一层一层的转换,直接输出结果。
比如,在语音辨识中先将语音信号送进去,通过模块一层一层的转换,直接输出结果。
3.1 语音识别
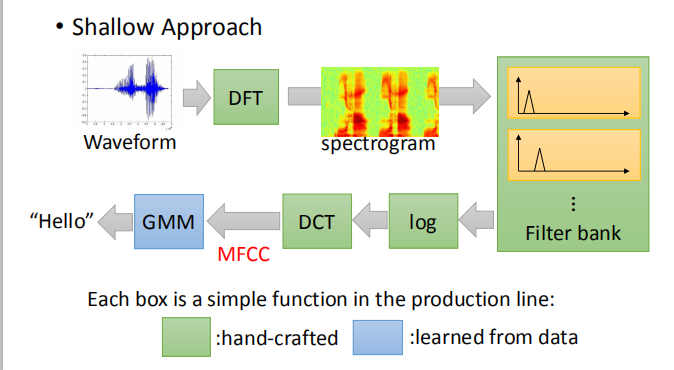
- 浅方法
每个盒子都是生产线上的一个简单功能:
其中只有 GMM 是通过数据训练自动生成的,其他的都是由科学家们手动设计的。
- 深度学习
 通过深度学习的方法进行语音识别,可以减少工程设计的部分,更多地通过机器自主学习。
通过深度学习的方法进行语音识别,可以减少工程设计的部分,更多地通过机器自主学习。
3.2 图像识别
- 浅方法
 同上,原来是绿色(手工设计)+蓝色(学习得到)来弄,现在变成:
同上,原来是绿色(手工设计)+蓝色(学习得到)来弄,现在变成:
- 深度学习
 现在,通过深度学习方式,把手工设计的模块去除了,所有功能块都是学习得来的。
现在,通过深度学习方式,把手工设计的模块去除了,所有功能块都是学习得来的。
4. 复杂的任务
在面对一些复杂的任务时,我们需要深层次的网络结构来解决一些问题,
而这些任务通过一两层的神经网络是无法完成的。
输入的声学特征中,相同的颜色表示同一个人说的话,他们说的话是完全相同的,
但是在图中的显示结果完全杂乱无章,我们通过多层的神经网络的输出结果可以观察到
相同颜色的信号聚集在一起,特征更加明显。
 上图中不同颜色代表的是不同人讲话,可以看出来同一句话,
上图中不同颜色代表的是不同人讲话,可以看出来同一句话,
不同人讲话,在二维平面的投影比较难以区分,用一层神经网络进行处理得到右边的图。
 经过网络层加深,使用八层隐藏层的神经网络就明显分开了。
经过网络层加深,使用八层隐藏层的神经网络就明显分开了。
MNIST 手写数字识别的输出结果:
 同样的,拥有更多隐藏层的网络结构,识别的更明确。
同样的,拥有更多隐藏层的网络结构,识别的更明确。
更多参考:
 网址: http://research.microsoft.com/apps/video/default.aspx?id=232373&r=1
网址: http://research.microsoft.com/apps/video/default.aspx?id=232373&r=1
- 深度学习:理论动机
http://videolectures.net/deeplearning2015_bengio_theoretical_motivations/
- 物理学与深度学习之间的联系
https://www.youtube.com/watch?v=5MdSE-N0bxs
- 为什么深度学习起作用:理论化学的视角
https://www.youtube.com/watch?v=kIbKHIPbxiU