这一节我们主要学习
- 为什么要使用词嵌入(Word Embedding)
- 为什么词嵌入是无监督学习
- 基于统计(Count based )
- 基于预测(Predition based)
- 词嵌入的特点
- 词嵌入的主要应用
1. 为什么要使用词嵌入
在词嵌入之前往往采用 1-of-N Encoding 的方法,如下图所示
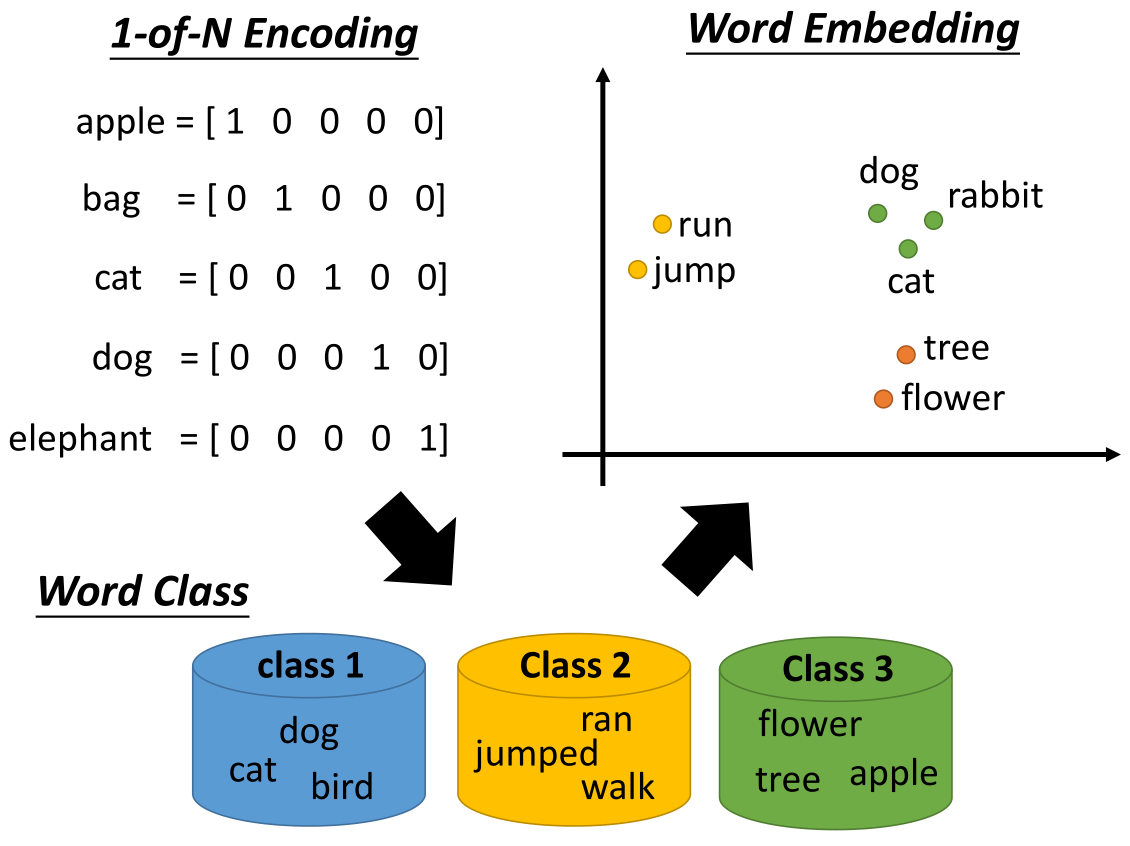
这种方法主要有两个缺点,首先这种表示是正交的,但是正是由于正交性使得具有相似属性的词之间的关系变得微弱;
其次这种编码方式使得词向量很长,比如说一共有10万个单词,那么就需要一个长度为10万的词向量进行编码。
为了克服这样的缺点,采用了词嵌入的方法。这种方法将词映射到高维之中(但是维数仍比 1-of-N Encoding 低很多),
相似的单词会聚集在一起,而不同的单词会分开;每个坐标轴可以看作是区分这些单词的一种属性,
比如说在上图中,横坐标可以认为是生物与其他的区别,纵坐标可以认为是会动和不会动的区别。
2. 为什么词嵌入是无监督学习
因为在进行学习的过程中,我们只知道输入的是词的一种编码,输出的是词的另一种编码,但是并不知道具体应该是怎样的一种编码,所以是无监督学习。
有的人可能想可以通过自编码的方式实现词嵌入,但是如果你得输入是 1-of-N Encoding 的话,是基本上不可以采用这样的方法处理的 ,因为输入的向量都是无关的,很难通过自编码的过程提取出什么有用的信息。
词嵌入的两种方式:
词嵌入 主要有基于统计 (Count based ) 和基于预测 (Predition based) 的两种方法。
3. 基于统计(Count based )
这种方法的主要思路如下图所示
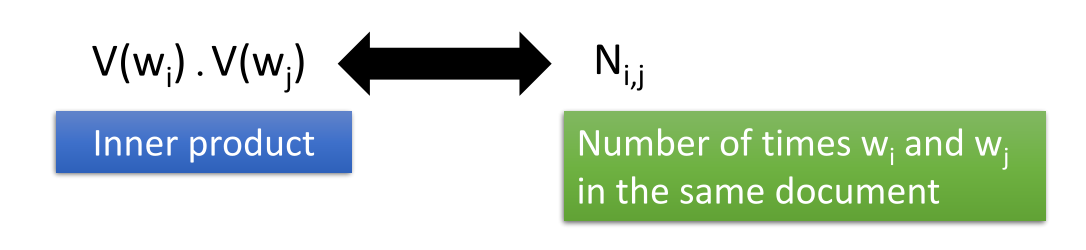
两词向量共同出现的频率比较高的话,那么这两个词向量也应该比较相似。
所以两个词向量的点积应该与它们公共出现的次数成正比,这与上节课讲的矩阵分解就很像了。
具体可以参考:Glove Vector : http://nlp.stanford.edu/projects/glove/
4. 基于预测(Prediction based)
用前一个词预测后一个词:
4.1 词预测训练过程
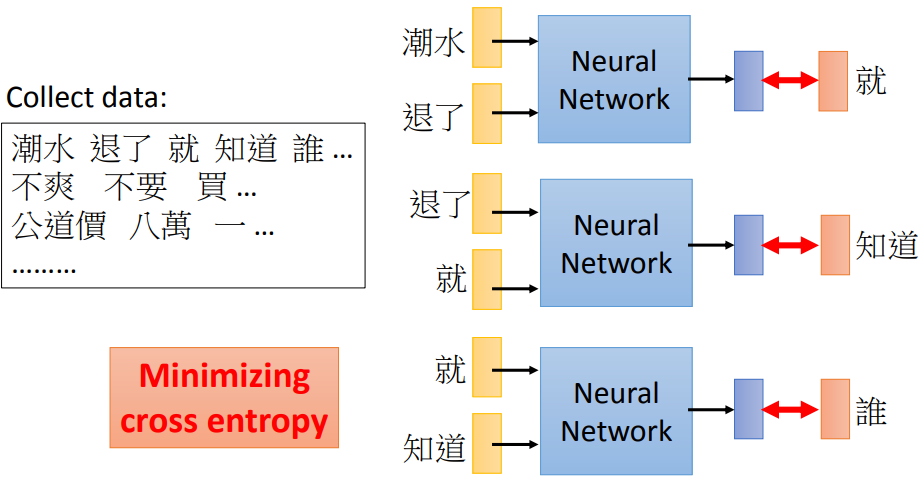
中文中“潮”、“水”是一个字,而“潮水”是一个词。
中文是以词和字为单位进行分词处理,故对中文如何分词是十分重要的。
但是对中文有一个断词问题,就是一个句子有好几种不同的分断法。
其作用可以拿来做推文接话,如下:

上图中红色部分都是一个词接一个词预测出来,然后形成一句话。
推文接话参考:https://www.ptt.cc/bbs/Teacher/M.1317226791.A.558.html
预测的另外一个作用:Language Modeling
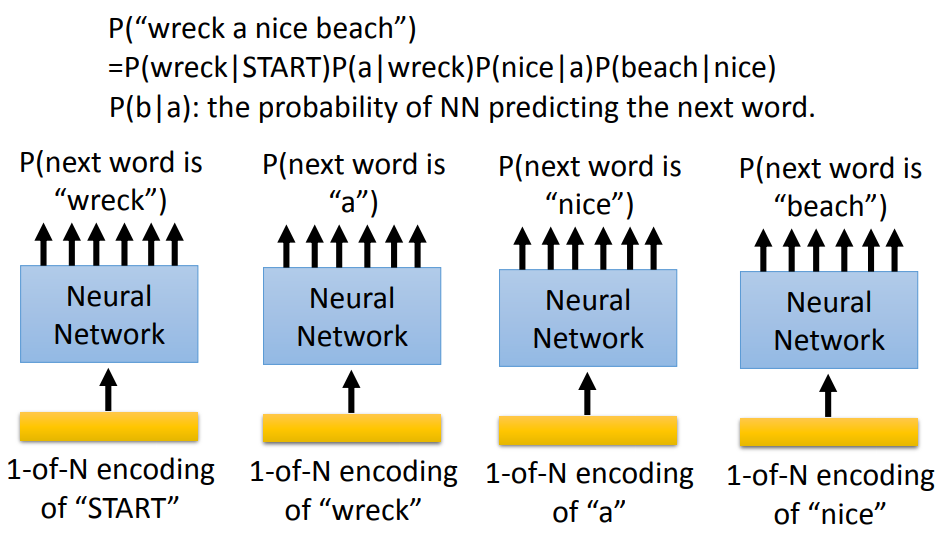
预测一个句子出现的几率,通常采用估测该句子中首个单词接下来的单词概率(比如通过 wreck 得到 a 的概率),
依次类推最终得到句子的概率等于所有单词的概率的乘积。
比如图中p(wrek|START)p(a|wreck)p(nice|a)p(beach|nice)
主要应用在机器翻译、语音识别中。
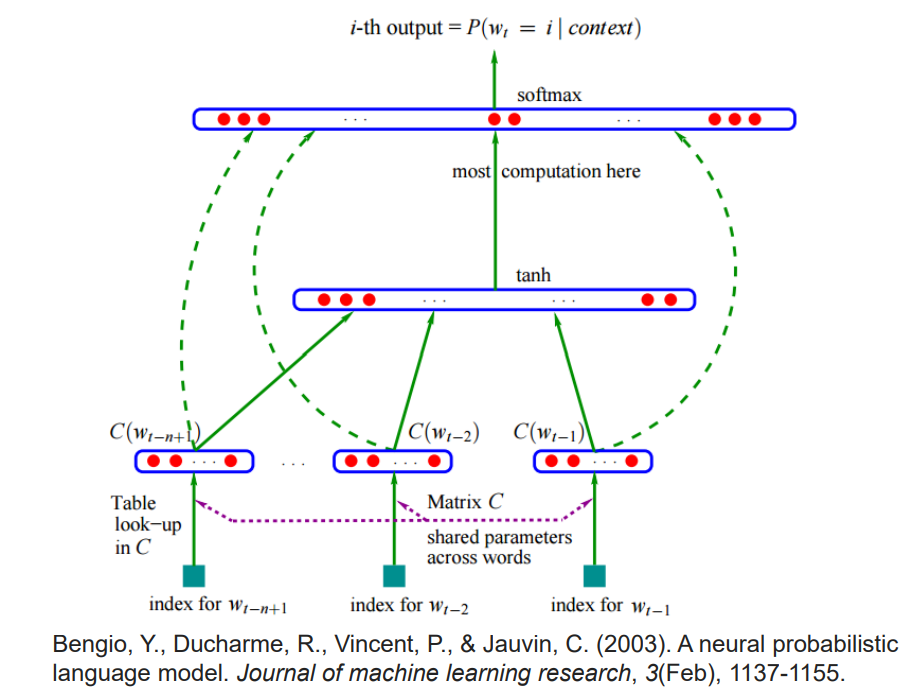
上图主要表达:预测$w_t$出现的几率,
输入是:$w_{t-1},w_{t-2},…,w_{t-n+1}$
每一个输入都会乘上一个矩阵C,成为$C(w_{t-1}),C(w_{t-2}),…,C(w_{t-n+1})$
然后将上述结果并起来并通过 tanh 激活函数和 softmax 处理得到某个单词出现的几率。
4.2 基于预测的原理
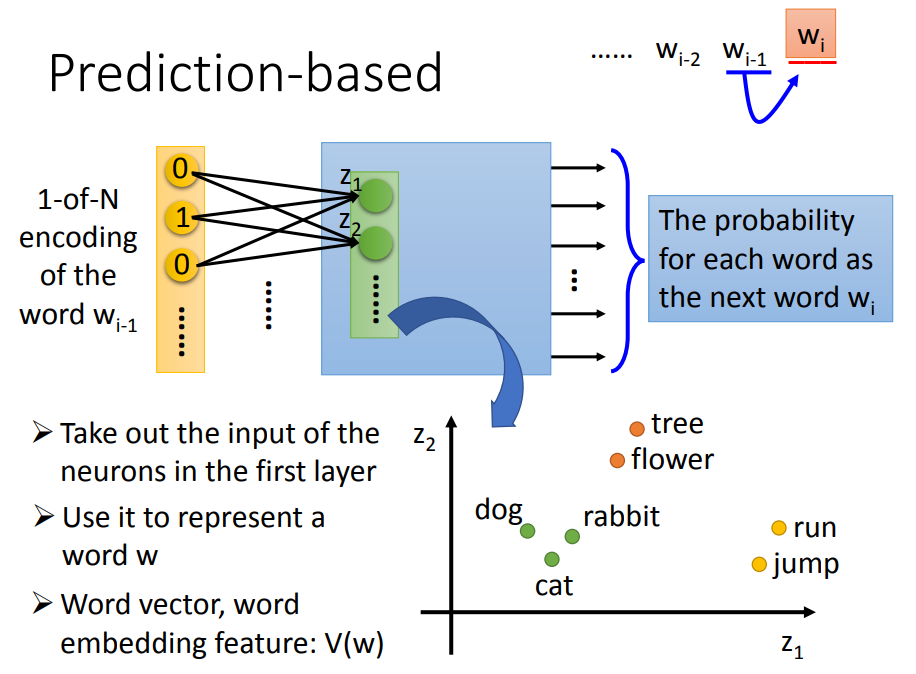
首先对词进行 one-hot 编码,然后进行类似于降维的处理,
得到第一个隐藏层的输入 $z_1,z_2,…$
训练出神经网络,所以我们将它的第一个隐藏层拿出来,就能将它们对应到相应的空间。
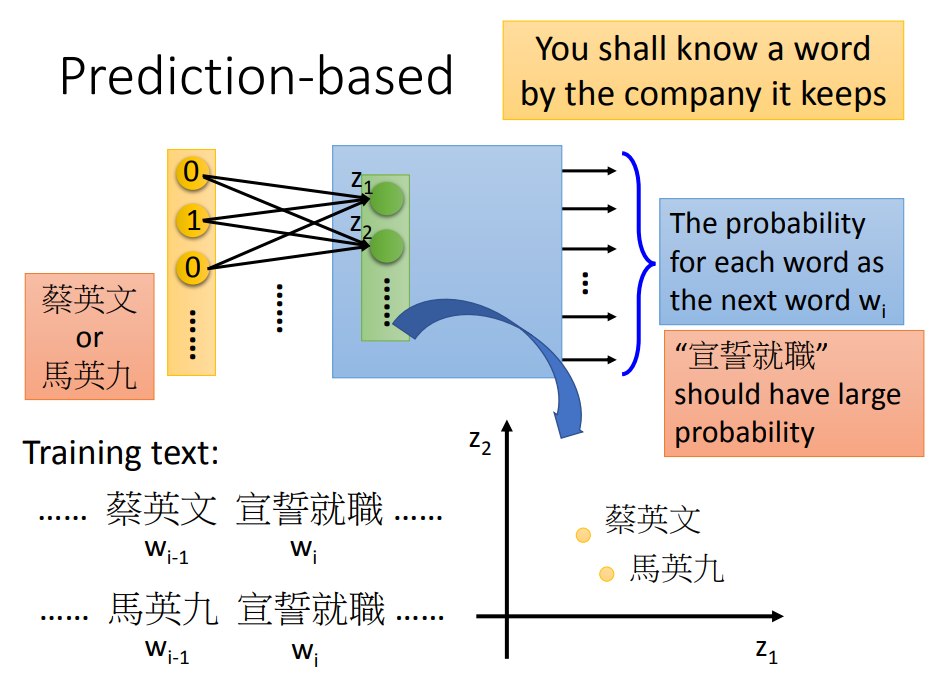
用第一个隐藏层的输出代表该词的词向量。(图中绿色的一层)
例子中“蔡英文”、“马英九”要让它们在进入隐藏层之后输入相近(为了得出共同结果“宣誓就职”)。
而且,仅通过一个词汇就要预测下一个词汇是很难的,所以通过共享参数来进行增强。
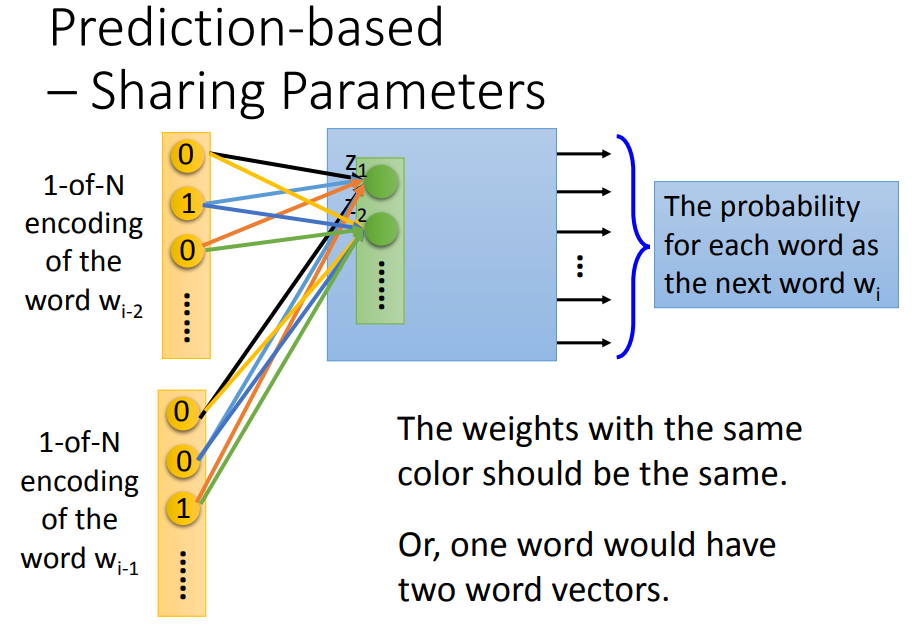
4.3 共享参数(Sharing Parameters)
不仅用前一个词,还用前 n 个词来一起预测。
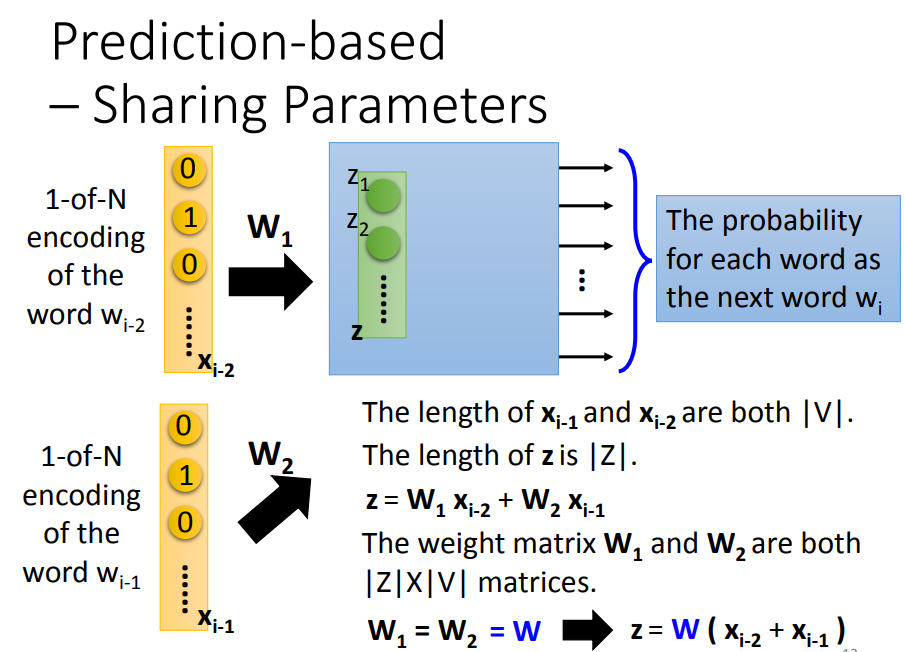
同样的权重是为了让同一个词放在 i-1 的位置和 i-2 的位置都有同样的输出,或者两个近义词可以得到近似的词向量输出,另外的好处是可以减少参数量。
计算过程:
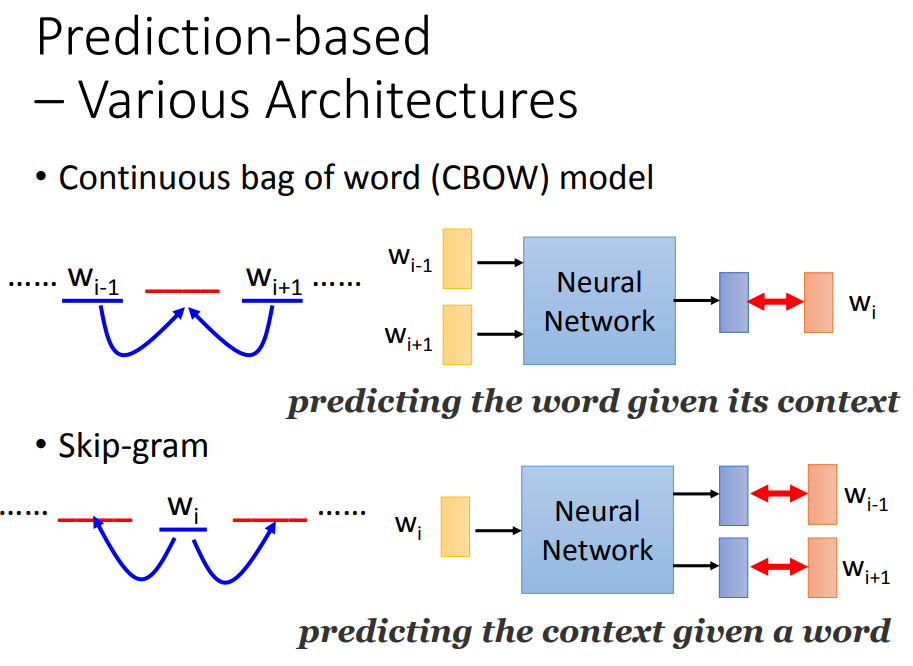
4.4 基于预测的其他结构
用前两个词预测后一个词和通过中间词汇预测前后2个词汇
5. 词嵌入的特点
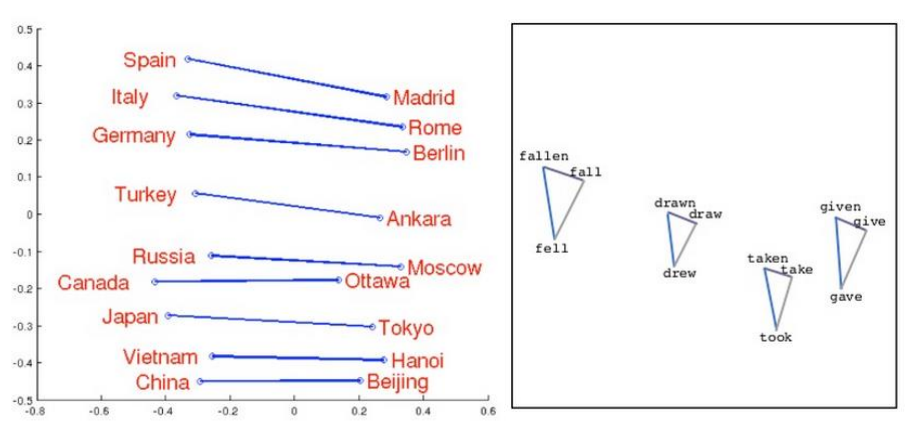

国家与首都有着固定的关系、动词的三态变化是一个有趣的三角形。
可以发现,我们把同样类型的单词摆在一起,他们之间是有固定的关系的。
比如让两个单词两两相减,然后部署到一个空间上,如果落到同一处,则他们之间的关系是很类似的。
参考资料: http://www.slideshare.net/hustwj/cikm-keynotenov2014
6. 应用
- 多语种词向量 (Multi-lingual Embedding)
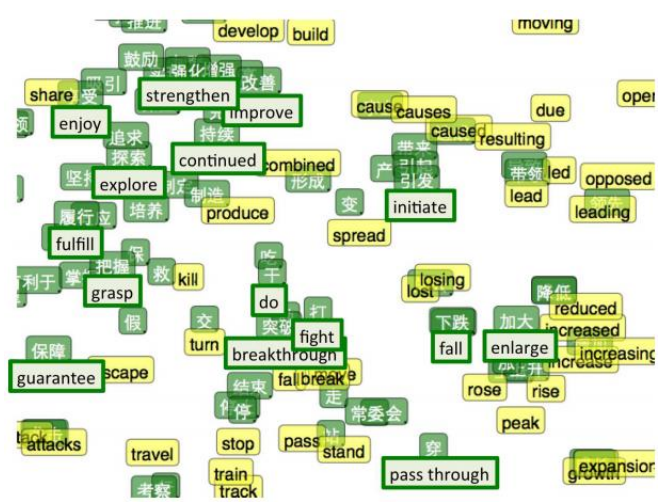
中文的 word embedding 和英文的 word embedding 无法将其混在一起使用。
但是将一些中文英文对应的词放在一起训练后,黄色部分词汇靠近其相近意思的中文词汇附近。
- 文章 Embedding(Document Embedding)
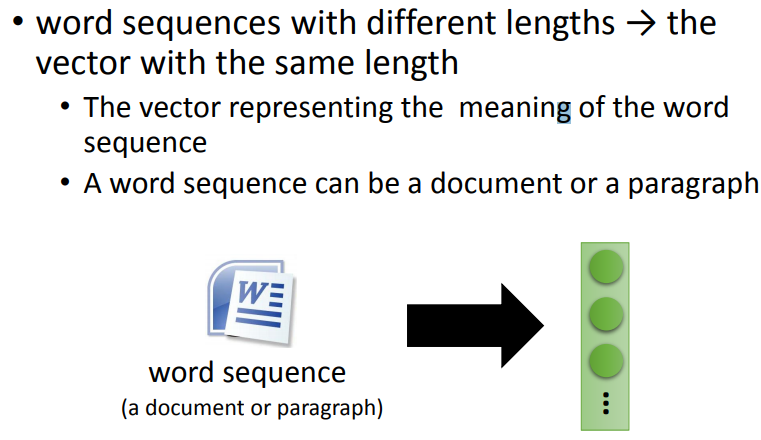
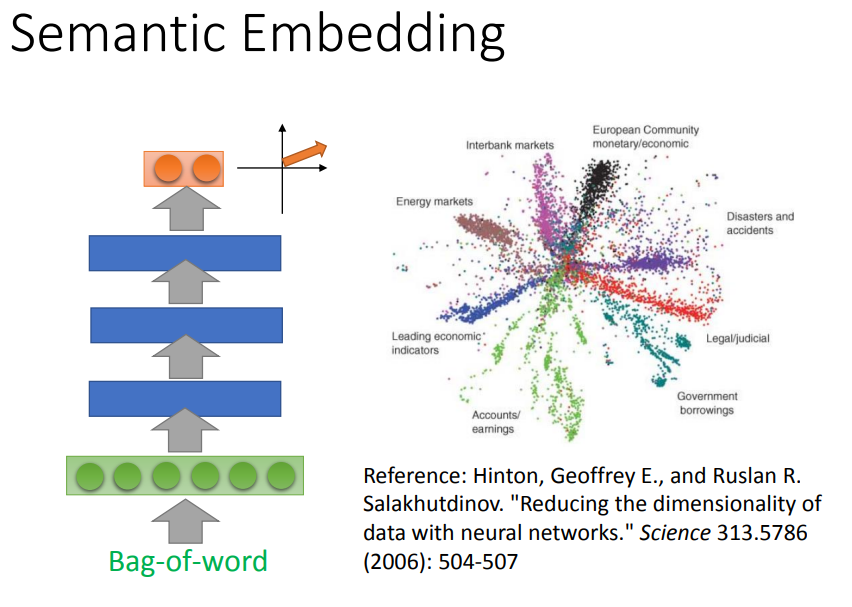
难点:不同文章长度不一致;不同的文章内容有不同的词汇数目;
解决方式:采用 bag-of-word 来描述文章

相同词汇,不同顺序表达不同的意思。
7. 总结
- 词嵌入的作用和分类
- 基于统计的词嵌入模型原理
- 基于预测的词嵌入模型原理